Pandas对数值进行分箱操作的4种方法总结
目录
- 前言
- 1、between & loc
- 2、cut
- 3、qcut
- 4、value_counts
前言
使用 Pandas 的between 、cut、qcut 和 value_count离散化数值变量。
分箱是一种常见的数据预处理技术有时也被称为分桶或离散化,他可用于将连续数据的间隔分组到“箱”或“桶”中。在本文中,我们将讨论使用 python Pandas 库对数值进行分箱的 4 种方法。
我们创建以下合成数据用于演示
import pandas as pd # version 1.3.5
import numpy as np
def create_df():
df = pd.DataFrame({'score': np.random.randint(0,101,1000)})
return df
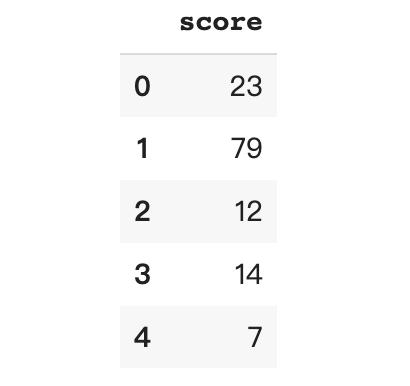
create_df()
df.head()
数据包括 1000 名学生的 0 到 100 分的考试分数。而这次的任务是将数字分数分为值“A”、“B”和“C”的等级,其中“A”是最好的等级,“C”是最差的等级。
1、between & loc
Pandas .between 方法返回一个包含 True 的布尔向量,用来对应的 Series 元素位于边界值 left 和 right 之间。
参数有下面三个:
- left:左边界
- right:右边界
- inclusive:要包括哪个边界。可接受的值为 {“both”、“neither”、“left”、“right”}。
根据以下间隔规则将学生的分数分为等级:
- A: (80, 100]
- B: (50, 80]
- C: [0, 50]
其中方括号 [ 和圆括号 ) 分别表示边界值是包含的和不包含的。我们需要确定哪个分数在感兴趣的区间之间,并为其分配相应的等级值。注意看下面的不同的参数表示是否包含边界
df.loc[df['score'].between(0, 50, 'both'), 'grade'] = 'C' df.loc[df['score'].between(50, 80, 'right'), 'grade'] = 'B' df.loc[df['score'].between(80, 100, 'right'), 'grade'] = 'A'
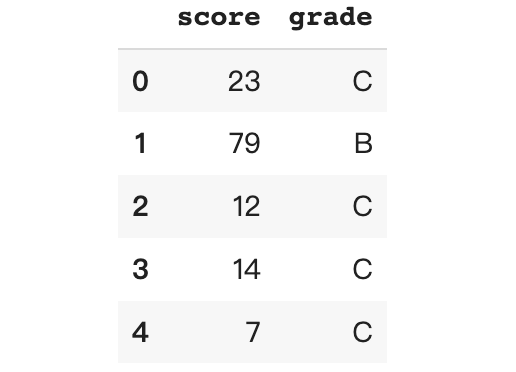
以下是每个分数区间的人数:
df.grade.value_counts()
C 488
B 310
A 202
Name: grade, dtype: int64
此方法需要为每个 bin 编写处理的代码,因此它仅适用于 bin 很少的情况。
2、cut
可以使用 cut将值分类为离散的间隔。此函数对于从连续变量到分类变量也很有用。
cut的参数如下:
- x:要分箱的数组。必须是一维的。
- bins:标量序列:定义允许非均匀宽度的 bin 边缘。
- labels:指定返回的 bin 的标签。必须与上面的 bins 参数长度相同。
- include_lowest: (bool) 第一个区间是否应该是左包含的。
bins = [0, 50, 80, 100] labels = ['C', 'B', 'A'] df['grade'] = pd.cut(x = df['score'], bins = bins, labels = labels, include_lowest = True)
这样就创建一个包含 bin 边界值的 bins 列表和一个包含相应 bin 标签的标签列表。
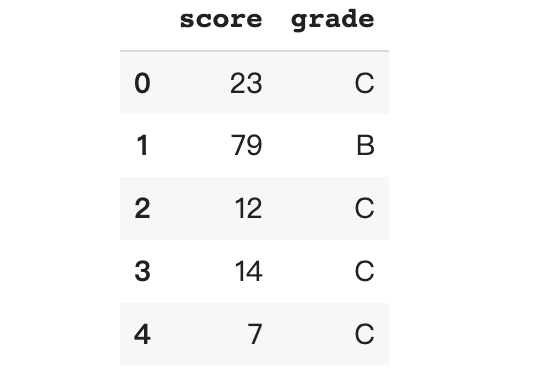
查看每个区段的人数
df.grade.value_counts()
C 488
B 310
A 202
Name: grade, dtype: int64
结果与上面示例相同。
3、qcut
qcut可以根据排名或基于样本分位数将变量离散为大小相等的桶[3]。
在前面的示例中,我们为每个级别定义了分数间隔,这回使每个级别的学生数量不均匀。在下面的示例中,我们将尝试将学生分类为 3 个具有相等(大约)数量的分数等级。示例中有 1000 名学生,因此每个分箱应该有大约 333 名学生。
qcut参数:
- x:要分箱的输入数组。必须是一维的。
- q:分位数。10 表示十分位数,4 表示四分位数等。也可以是交替排列的分位数,例如[0, .25, .5, .75, 1.] 四分位数。
- labels:指定 bin 的标签。必须与生成的 bin 长度相同。
- retbins: (bool) 是否返回 (bins, labels)。
df['grade'], cut_bin = pd.qcut(df['score'], q = 3, labels = ['C', 'B', 'A'], retbins = True) df.head()
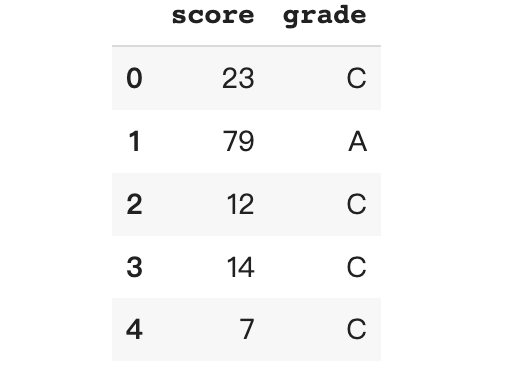
print (cut_bin) >> [ 0. 36. 68. 100.]
分数间隔如下:
- C:[0, 36]
- B:(36, 68]
- A:(68, 100]
使用 .value_counts() 检查每个等级有多少学生。理想情况下,每个箱应该有大约 333 名学生。
df.grade.value_counts()
C 340
A 331
B 329
Name: grade, dtype: int64
4、value_counts
虽然 pandas .value_counts 通常用于计算系列中唯一值的数量,但它也可用于使用 bins 参数将值分组到半开箱中。
df['score'].value_counts(bins = 3, sort = False)
默认情况下, .value_counts 按值的降序对返回的系列进行排序。将 sort 设置为 False 以按其索引的升序对系列进行排序。
(-0.101, 33.333] 310 (33.333, 66.667] 340 (66.667, 100.0] 350 Name: score, dtype: int64
series 索引是指每个 bin 的区间范围,其中方括号 [ 和圆括号 ) 分别表示边界值是包含的和不包含的。返回series 的值表示每个 bin 中有多少条记录。
与 .qcut 不同,每个 bin 中的记录数不一定相同(大约)。.value_counts 不会将相同数量的记录分配到相同的类别中,而是根据最高和最低分数将分数范围分成 3 个相等的部分。分数的最小值为 0,最大值为 100,因此这 3 个部分中的每一个都大约在 33.33 范围内。这也解释了为什么 bin 的边界是 33.33 的倍数。
我们还可以通过传入边界列表来定义 bin 边界。
df['score'].value_counts(bins = [0,50,80,100], sort = False)
(-0.001, 50.0] 488
(50.0, 80.0] 310
(80.0, 100.0] 202
Name: score, dtype: int64
这给了我们与示例 1 和 2 相同的结果。
以上就是Pandas对数值进行分箱操作的4种方法总结的详细内容,更多关于Pandas数值分箱的资料请关注我们其它相关文章!
相关推荐
-
使用pandas实现连续数据的离散化处理方式(分箱操作)
Python实现连续数据的离散化处理主要基于两个函数,pandas.cut和pandas.qcut,前者根据指定分界点对连续数据进行分箱处理,后者则可以根据指定箱子的数量对连续数据进行等宽分箱处理,所谓等宽指的是每个箱子中的数据量是相同的. 下面简单介绍一下这两个函数的用法: # 导入pandas包 import pandas as pd ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 41, 32] # 待分箱数据 bins = [18, 25,
-
python的等深分箱实例
背景 当前很多文章尝试过最优分箱,python上也有cut等方法进行等宽分箱.为了方便日后输出结果以及分箱要求.做一个简单的轮子以供大家日后使用.很多能用其他轮子的地方也没有多余出力,也不托大会比别人写的好.空间复杂度尽我所能. 方法展示 话不多说上代码. 以下为等深分箱以及encoding方法 # -*- coding: utf-8 -*- """ Created on Tue Jan 29 17:26:38 2019 @author: DamomWCG "&qu
-
使用python 计算百分位数实现数据分箱代码
对于百分位数,相信大家都比较熟悉,以下解释源引自百度百科. 百分位数,如果将一组数据从小到大排序,并计算相应的累计百分位,则某一百分位所对应数据的值就称为这一百分位的百分位数.可表示为:一组n个观测值按数值大小排列.如,处于p%位置的值称第p百分位数. 因为百分位数是采用等分的方式划分数据,因此也可用此方法进行等频分箱. import pandas as pd import numpy as np import random t=pd.DataFrame(columns=['l','s']) #
-
python实现二分类的卡方分箱示例
解决的问题: 1.实现了二分类的卡方分箱: 2.实现了最大分组限定停止条件,和最小阈值限定停止条件: 问题,还不太清楚,后续补充. 1.自由度k,如何来确定,卡方阈值的自由度为 分箱数-1,显著性水平可以取10%,5%或1% 算法扩展: 1.卡方分箱除了用阈值来做约束条件,还可以进一步的加入分箱数约束,以及最小箱占比,坏人率约束等. 2.需要实现更多分类的卡方分箱算法: 具体代码如下: # -*- coding: utf-8 -*- """ Created on Wed No
-
python实现连续变量最优分箱详解--CART算法
关于变量分箱主要分为两大类:有监督型和无监督型 对应的分箱方法: A. 无监督:(1) 等宽 (2) 等频 (3) 聚类 B. 有监督:(1) 卡方分箱法(ChiMerge) (2) ID3.C4.5.CART等单变量决策树算法 (3) 信用评分建模的IV最大化分箱 等 本篇使用python,基于CART算法对连续变量进行最优分箱 由于CART是决策树分类算法,所以相当于是单变量决策树分类. 简单介绍下理论: CART是二叉树,每次仅进行二元分类,对于连续性变量,方法是依次计算相邻两元素值的中位
-
Python实现对相同数据分箱的小技巧分享
目录 前言 思路 类型一:数字 类型二:元组 附:利用Python的cut方法可以对数据进行分箱. 总结 前言 博主最近工作中刚好用到数据分箱操作(对相同数据进行遍历比较,避免了全部遍历比较,大大减少了电脑IO次数,提高程序运行速度),翻了很多博文都没有找到解决方法,写一下我自己的解决思路!!! 什么是分箱? 简单点说就是将不同的东西,按照特定的条件放到一个指定容器里,比如水果 把绿色的放一个篮子里,红色一个篮子等等,这个篮子就是箱,而水果就是数据 颜色就是条件 什么样式的数据要进行分箱 数据主
-

Pandas对数值进行分箱操作的4种方法总结
目录 前言 1.between & loc 2.cut 3.qcut 4.value_counts 前言 使用 Pandas 的between .cut.qcut 和 value_count离散化数值变量. 分箱是一种常见的数据预处理技术有时也被称为分桶或离散化,他可用于将连续数据的间隔分组到“箱”或“桶”中.在本文中,我们将讨论使用 python Pandas 库对数值进行分箱的 4 种方法. 我们创建以下合成数据用于演示 import pandas as pd # version 1.3.5
-
python利用pd.cut()和pd.qcut()对数据进行分箱操作
目录 1.cut()可以实现类似于对成绩进行优良统计的功能,来看代码示例. 2.qcut()可以生成指定的箱子数,然后使每个箱子都具有相同数量的数据 1.cut()可以实现类似于对成绩进行优良统计的功能,来看代码示例. 假如我们有一组学生成绩,我们需要将这些成绩分为不及格(0-59).及格(60-70).良(71-85).优(86-100)这几组.这时候可以用到cut() import numpy as np import pandas as pd # 我们先给 scores传入30个从0到10
-
iOS app 右滑返回操作的两种方法
前提条件,存在A和B两个页面,A是主界面,A push 到 B 方法一:如果B页面的返回按钮要用自定义的按钮(在iOS7中,如果使用了UINavigationController,那么系统自带的附加了一个从屏幕左边缘开始滑动可以实现pop的手势.但是,如果自定义了navigationItem的leftBarButtonItem,那么这个手势就会失效.) 在A界面: - (void)viewDidAppear:(BOOL)animated { self.navigationController.i
-
Android延时操作的三种方法
在Android开发中我们可能会有延时执行某个操作的需求,例如我们启动应用的时候,一开始呈现的是引导页面,3秒后进入主界面,这就是一个延时操作. 下面是实现延时操作的三种方法: 一.使用线程的休眠实现延时操作 new Thread(new Runnable() { @Override public void run() { Thread.sleep(1000); // 休眠1秒 /** * 延时执行的代码 */ } }).start(); 二.使用TimerTask实现延时操作 Timer ti
-
PHP实现链式操作的三种方法详解
本文实例讲述了PHP实现链式操作的三种方法.分享给大家供大家参考,具体如下: 在php中有很多字符串函数,例如要先过滤字符串收尾的空格,再求出其长度,一般的写法是: strlen(trim($str)) 如果要实现类似js中的链式操作,比如像下面这样应该怎么写? $str->trim()->strlen() 下面分别用三种方式来实现: 方法一.使用魔法函数__call结合call_user_func来实现 思想:首先定义一个字符串类StringHelper,构造函数直接赋值value,然后链式
-
linux下终端分屏使用的两种方法(screen和tmux)
本文主要介绍两种终端分屏工具:screen和tmux,分享出来供大家参考学习,下面来看看详细的介绍: 一.使用screen分屏(只能上下分屏,不能左右分屏) (1)安装工具 在ubuntu系统中使用sudo apt-get install screen 安装screen工具 (2)使用工具 1,输入命令screen使用工具 2,上下分屏:ctrl + a 再按shift + s 3,切换屏幕:ctrl + a 再按tab键 4,新建一个终端:ctrl + a 再按c 5,关闭一个终端:ct
-
R语言数据预处理操作——离散化(分箱)
一.项目环境 开发工具:RStudio R:3.5.2 相关包:infotheo,discretization,smbinning,dplyr,sqldf 二.导入数据 # 这里我们使用的是鸢尾花数据集(iris) data(iris) head(iris) Sepal.Length Sepal.Width Petal.Length Petal.Width Species 1 5.1 3.5 1.4 0.2 setosa 2 4.9 3.0 1.4 0.2 setosa 3 4.7 3.2 1.