C++ TensorflowLite模型验证的过程详解
故事是这样的:
有一个手撑检测的tflite模型,需要在开发板上跑起来。手机版本的已成熟,要移植到开发板上。现在要验证tflite模型文件在板子上的运行结果要和手机上一致。
前提:为了多次重复测试,在Android端使用了同一帧数据(从一个录制的mp4中固定取一张图)测试代码如下图

下面是测试过程
记录下Android版API运行推理前的图片数据文件(经过了规一化处理,所以都是-1~1之间的float数据)

这一步卡在了写float数据到二进制文件中,C++读出来有问题换了个方案,直接存储float字符串
private void saveFile(float[] pfImageData) {
try {
File file = new File(Environment.getExternalStoragePublicDirectory(Environment.DIRECTORY_DOWNLOADS).getAbsolutePath() + "/tfimg");
StringBuilder sb = new StringBuilder();
for (float val : pfImageData) {
//保留4位小数,这里可以改为其他值
sb.append(String.format("%.4f", val));
sb.append("\r\n");
}
FileWriter out = new FileWriter(file); //文件写入流
out.write(sb.toString());
out.close();
} catch (Exception e) {
e.printStackTrace();
Log.e("Melon", "存储文件异常," + e.getMessage());
}
}
拿着这个文件在板子上输入到Tflite模型中
测试代码,主要是RunInference()和read_file()
/* Copyright 2017 The TensorFlow Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
==============================================================================*/
#include "tensorflow/lite/examples/label_image/label_image.h"
#include <fcntl.h> // NOLINT(build/include_order)
#include <getopt.h> // NOLINT(build/include_order)
#include <sys/time.h> // NOLINT(build/include_order)
#include <sys/types.h> // NOLINT(build/include_order)
#include <sys/uio.h> // NOLINT(build/include_order)
#include <unistd.h> // NOLINT(build/include_order)
#include <cstdarg>
#include <cstdio>
#include <cstdlib>
#include <fstream>
#include <iomanip>
#include <iostream>
#include <map>
#include <memory>
#include <sstream>
#include <string>
#include <unordered_set>
#include <vector>
#include "absl/memory/memory.h"
#include "tensorflow/lite/examples/label_image/bitmap_helpers.h"
#include "tensorflow/lite/examples/label_image/get_top_n.h"
#include "tensorflow/lite/examples/label_image/log.h"
#include "tensorflow/lite/kernels/register.h"
#include "tensorflow/lite/optional_debug_tools.h"
#include "tensorflow/lite/profiling/profiler.h"
#include "tensorflow/lite/string_util.h"
#include "tensorflow/lite/tools/command_line_flags.h"
#include "tensorflow/lite/tools/delegates/delegate_provider.h"
namespace tflite
{
namespace label_image
{
double get_us(struct timeval t) { return (t.tv_sec * 1000000 + t.tv_usec); }
using TfLiteDelegatePtr = tflite::Interpreter::TfLiteDelegatePtr;
using ProvidedDelegateList = tflite::tools::ProvidedDelegateList;
class DelegateProviders
{
public:
DelegateProviders() : delegate_list_util_(¶ms_)
{
delegate_list_util_.AddAllDelegateParams();
}
// Initialize delegate-related parameters from parsing command line arguments,
// and remove the matching arguments from (*argc, argv). Returns true if all
// recognized arg values are parsed correctly.
bool InitFromCmdlineArgs(int *argc, const char **argv)
{
std::vector<tflite::Flag> flags;
// delegate_list_util_.AppendCmdlineFlags(&flags);
const bool parse_result = Flags::Parse(argc, argv, flags);
if (!parse_result)
{
std::string usage = Flags::Usage(argv[0], flags);
LOG(ERROR) << usage;
}
return parse_result;
}
// According to passed-in settings `s`, this function sets corresponding
// parameters that are defined by various delegate execution providers. See
// lite/tools/delegates/README.md for the full list of parameters defined.
void MergeSettingsIntoParams(const Settings &s)
{
// Parse settings related to GPU delegate.
// Note that GPU delegate does support OpenCL. 'gl_backend' was introduced
// when the GPU delegate only supports OpenGL. Therefore, we consider
// setting 'gl_backend' to true means using the GPU delegate.
if (s.gl_backend)
{
if (!params_.HasParam("use_gpu"))
{
LOG(WARN) << "GPU deleate execution provider isn't linked or GPU "
"delegate isn't supported on the platform!";
}
else
{
params_.Set<bool>("use_gpu", true);
// The parameter "gpu_inference_for_sustained_speed" isn't available for
// iOS devices.
if (params_.HasParam("gpu_inference_for_sustained_speed"))
{
params_.Set<bool>("gpu_inference_for_sustained_speed", true);
}
params_.Set<bool>("gpu_precision_loss_allowed", s.allow_fp16);
}
}
// Parse settings related to NNAPI delegate.
if (s.accel)
{
if (!params_.HasParam("use_nnapi"))
{
LOG(WARN) << "NNAPI deleate execution provider isn't linked or NNAPI "
"delegate isn't supported on the platform!";
}
else
{
params_.Set<bool>("use_nnapi", true);
params_.Set<bool>("nnapi_allow_fp16", s.allow_fp16);
}
}
// Parse settings related to Hexagon delegate.
if (s.hexagon_delegate)
{
if (!params_.HasParam("use_hexagon"))
{
LOG(WARN) << "Hexagon deleate execution provider isn't linked or "
"Hexagon delegate isn't supported on the platform!";
}
else
{
params_.Set<bool>("use_hexagon", true);
params_.Set<bool>("hexagon_profiling", s.profiling);
}
}
// Parse settings related to XNNPACK delegate.
if (s.xnnpack_delegate)
{
if (!params_.HasParam("use_xnnpack"))
{
LOG(WARN) << "XNNPACK deleate execution provider isn't linked or "
"XNNPACK delegate isn't supported on the platform!";
}
else
{
params_.Set<bool>("use_xnnpack", true);
params_.Set<bool>("num_threads", s.number_of_threads);
}
}
}
// Create a list of TfLite delegates based on what have been initialized (i.e.
// 'params_').
std::vector<ProvidedDelegateList::ProvidedDelegate> CreateAllDelegates()
const
{
return delegate_list_util_.CreateAllRankedDelegates();
}
private:
// Contain delegate-related parameters that are initialized from command-line
// flags.
tflite::tools::ToolParams params_;
// A helper to create TfLite delegates.
ProvidedDelegateList delegate_list_util_;
};
// Takes a file name, and loads a list of labels from it, one per line, and
// returns a vector of the strings. It pads with empty strings so the length
// of the result is a multiple of 16, because our model expects that.
// std::vector<uint8_t> read_file(const std::string &input_bmp_name)
// {
// int begin, end;
// std::ifstream file(input_bmp_name, std::ios::in | std::ios::binary);
// if (!file)
// {
// LOG(FATAL) << "input file " << input_bmp_name << " not found";
// exit(-1);
// }
// begin = file.tellg();
// file.seekg(0, std::ios::end);
// end = file.tellg();
// size_t len = end - begin;
// LOG(INFO) << "len: " << len;
// std::vector<uint8_t> img_bytes(len);
// file.seekg(0, std::ios::beg);
// file.read(reinterpret_cast<char *>(img_bytes.data()), len);
// return img_bytes;
// }
/**
* 读取文件
*/
std::vector<float> read_file(const std::string &input_bmp_name)
{
int begin, end;
std::ifstream file(input_bmp_name, std::ios::in | std::ios::binary);
if (!file)
{
LOG(FATAL) << "input file " << input_bmp_name << " not found";
exit(-1);
}
begin = file.tellg();
file.seekg(0, std::ios::end);
end = file.tellg();
size_t len = end - begin;
LOG(INFO) << "len: " << len;
std::vector<float> img_bytes;
file.seekg(0, std::ios::beg);
string strLine = "";
float temp;
while (getline(file, strLine))
{
temp = atof(strLine.c_str());
img_bytes.push_back(temp);
}
LOG(INFO) << "文件读取完成:" << input_bmp_name;
return img_bytes;
}
/**
* 运行推理
*/
void RunInference(Settings *settings)
{
if (!settings->model_name.c_str())
{
LOG(ERROR) << "no model file name";
exit(-1);
}
std::unique_ptr<tflite::FlatBufferModel> model;
std::unique_ptr<tflite::Interpreter> interpreter;
model = tflite::FlatBufferModel::BuildFromFile(settings->model_name.c_str());
if (!model)
{
LOG(ERROR) << "Failed to mmap model " << settings->model_name;
exit(-1);
}
settings->model = model.get();
LOG(INFO) << "Loaded model " << settings->model_name;
model->error_reporter();
LOG(INFO) << "resolved reporter";
tflite::ops::builtin::BuiltinOpResolver resolver;
tflite::InterpreterBuilder(*model, resolver)(&interpreter); //生成interpreter
if (!interpreter)
{
LOG(ERROR) << "Failed to construct interpreter";
exit(-1);
}
interpreter->SetAllowFp16PrecisionForFp32(settings->allow_fp16);
if (settings->verbose)
{
LOG(INFO) << "tensors size: " << interpreter->tensors_size();
LOG(INFO) << "nodes size: " << interpreter->nodes_size();
LOG(INFO) << "inputs: " << interpreter->inputs().size();
LOG(INFO) << "input(0) name: " << interpreter->GetInputName(0);
int t_size = interpreter->tensors_size();
for (int i = 0; i < t_size; i++)
{
if (interpreter->tensor(i)->name)
LOG(INFO) << i << ": " << interpreter->tensor(i)->name << ", "
<< interpreter->tensor(i)->bytes << ", "
<< interpreter->tensor(i)->type << ", "
<< interpreter->tensor(i)->params.scale << ", "
<< interpreter->tensor(i)->params.zero_point;
}
}
if (settings->number_of_threads != -1)
{
interpreter->SetNumThreads(settings->number_of_threads);
}
int image_width = 128;
int image_height = 128;
int image_channels = 3;
// std::vector<uint8_t> in = read_bmp(settings->input_bmp_name, &image_width, &image_height, &image_channels, settings);
std::vector<float> file_bytes = read_file(settings->input_bmp_name);
for (int i = 0; i < 100; i++)
{
//和Android的输入做对比
LOG(INFO) << i << ": " << file_bytes[i];
}
/* inputs()[0]得到输入张量数组中的第一个张量,也就是classifier中唯一的那个输入张量;
input是个整型值,是张量列表中的引索 */
int input = interpreter->inputs()[0];
LOG(INFO) << "input: " << input;
const std::vector<int> inputs = interpreter->inputs();
const std::vector<int> outputs = interpreter->outputs();
LOG(INFO) << "number of inputs: " << inputs.size();
LOG(INFO) << "input index: " << inputs[0];
LOG(INFO) << "number of outputs: " << outputs.size();
LOG(INFO) << "outputs index1: " << outputs[0] << ",outputs index2: " << outputs[1];
if (interpreter->AllocateTensors() != kTfLiteOk)
{ //加载所有tensor
LOG(ERROR) << "Failed to allocate tensors!";
exit(-1);
}
if (settings->verbose)
PrintInterpreterState(interpreter.get());
// 从输入张量的原数据中得到输入尺寸
TfLiteIntArray *dims = interpreter->tensor(input)->dims;
int wanted_height = dims->data[1];
int wanted_width = dims->data[2];
int wanted_channels = dims->data[3];
settings->input_type = interpreter->tensor(input)->type;
//typed_tensor返回一个经过固定数据类型转换的tensor指针
//以input为索引,在TfLiteTensor* content_.tensors这个张量表得到具体的张量
//返回该张量的data.raw,它指示张量正关联着的内存块
// resize<float>(interpreter->typed_tensor<float>(input), in.data(),
// image_height, image_width, image_channels, wanted_height,
// wanted_width, wanted_channels, settings);
//赋值给input tensor
float *inputP = interpreter->typed_input_tensor<float>(0);
LOG(INFO) << "file_bytes size: " << file_bytes.size();
for (int i = 0; i < file_bytes.size(); i++)
{
inputP[i] = file_bytes[i];
}
struct timeval start_time, stop_time;
gettimeofday(&start_time, nullptr);
for (int i = 0; i < settings->loop_count; i++)
{ //调用模型进行推理
if (interpreter->Invoke() != kTfLiteOk)
{
LOG(ERROR) << "Failed to invoke tflite!";
exit(-1);
}
}
gettimeofday(&stop_time, nullptr);
LOG(INFO) << "invoked";
LOG(INFO) << "average time: "
<< (get_us(stop_time) - get_us(start_time)) /
(settings->loop_count * 1000)
<< " ms";
const float threshold = 0.001f;
int output = interpreter->outputs()[1];
LOG(INFO) << "output: " << output;
LOG(INFO) << "interpreter->tensors_size: " << interpreter->tensors_size();
TfLiteTensor *tensor = interpreter->tensor(output);
TfLiteIntArray *output_dims = tensor->dims;
// assume output dims to be something like (1, 1, ... ,size)
auto output_size = output_dims->data[output_dims->size - 1];
LOG(INFO) << "索引为" << output << "的输出张量的-"
<< "output_size: " << output_size;
for (int i = 0; i < output_dims->size; i++)
{
LOG(INFO) << "元数据有:" << output_dims->data[i];
}
float *prediction = interpreter->typed_output_tensor<float>(1);
float classificators[1][896][1];
memcpy(classificators, prediction, 896 * 1 * sizeof(float));
// float classificators[1][896][18];
// memcpy(classificators, prediction, 896 * 18 * sizeof(float));
//输出分类结果
for (float(&r)[896][1] : classificators)
{
for (float(&p)[1] : r)
{
for (float &q : p)
{
std::cout << q << ' ';
}
std::cout << std::endl;
}
std::cout << std::endl;
}
}
int Main(int argc, char **argv)
{
DelegateProviders delegate_providers;
bool parse_result = delegate_providers.InitFromCmdlineArgs(
&argc, const_cast<const char **>(argv));
if (!parse_result)
{
return EXIT_FAILURE;
}
Settings s;
int c;
while (true)
{
static struct option long_options[] = {
{"accelerated", required_argument, nullptr, 'a'},
{"allow_fp16", required_argument, nullptr, 'f'},
{"count", required_argument, nullptr, 'c'},
{"verbose", required_argument, nullptr, 'v'},
{"image", required_argument, nullptr, 'i'},
{"labels", required_argument, nullptr, 'l'},
{"tflite_model", required_argument, nullptr, 'm'},
{"profiling", required_argument, nullptr, 'p'},
{"threads", required_argument, nullptr, 't'},
{"input_mean", required_argument, nullptr, 'b'},
{"input_std", required_argument, nullptr, 's'},
{"num_results", required_argument, nullptr, 'r'},
{"max_profiling_buffer_entries", required_argument, nullptr, 'e'},
{"warmup_runs", required_argument, nullptr, 'w'},
{"gl_backend", required_argument, nullptr, 'g'},
{"hexagon_delegate", required_argument, nullptr, 'j'},
{"xnnpack_delegate", required_argument, nullptr, 'x'},
{nullptr, 0, nullptr, 0}};
/* getopt_long stores the option index here. */
int option_index = 0;
c = getopt_long(argc, argv,
"a:b:c:d:e:f:g:i:j:l:m:p:r:s:t:v:w:x:", long_options,
&option_index);
/* Detect the end of the options. */
if (c == -1)
break;
switch (c)
{
case 'a':
s.accel = strtol(optarg, nullptr, 10); // NOLINT(runtime/deprecated_fn)
break;
case 'b':
s.input_mean = strtod(optarg, nullptr);
break;
case 'c':
s.loop_count =
strtol(optarg, nullptr, 10); // NOLINT(runtime/deprecated_fn)
break;
case 'e':
s.max_profiling_buffer_entries =
strtol(optarg, nullptr, 10); // NOLINT(runtime/deprecated_fn)
break;
case 'f':
s.allow_fp16 =
strtol(optarg, nullptr, 10); // NOLINT(runtime/deprecated_fn)
break;
case 'g':
s.gl_backend =
strtol(optarg, nullptr, 10); // NOLINT(runtime/deprecated_fn)
break;
case 'i':
s.input_bmp_name = optarg;
break;
case 'j':
s.hexagon_delegate = optarg;
break;
case 'l':
s.labels_file_name = optarg;
break;
case 'm':
s.model_name = optarg;
break;
case 'p':
s.profiling =
strtol(optarg, nullptr, 10); // NOLINT(runtime/deprecated_fn)
break;
case 'r':
s.number_of_results =
strtol(optarg, nullptr, 10); // NOLINT(runtime/deprecated_fn)
break;
case 's':
s.input_std = strtod(optarg, nullptr);
break;
case 't':
s.number_of_threads = strtol( // NOLINT(runtime/deprecated_fn)
optarg, nullptr, 10);
break;
case 'v':
s.verbose =
strtol(optarg, nullptr, 10); // NOLINT(runtime/deprecated_fn)
break;
case 'w':
s.number_of_warmup_runs =
strtol(optarg, nullptr, 10); // NOLINT(runtime/deprecated_fn)
break;
case 'x':
s.xnnpack_delegate =
strtol(optarg, nullptr, 10); // NOLINT(runtime/deprecated_fn)
break;
case 'h':
case '?':
/* getopt_long already printed an error message. */
exit(-1);
default:
exit(-1);
}
}
delegate_providers.MergeSettingsIntoParams(s);
RunInference(&s);
return 0;
}
} // namespace label_image
} // namespace tflite
int main(int argc, char **argv)
{
return tflite::label_image::Main(argc, argv);
}
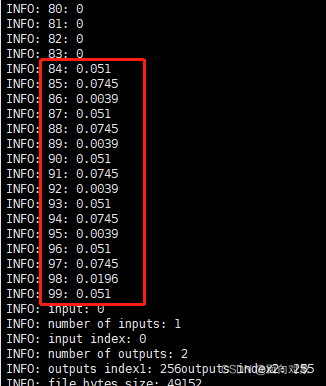
运行指令 ./ws_app --tflite_model libnewpalm_detection.tflite --image tfimg对比推理前的输入一致
Android端

开发板上
对比推理后的输出一致 Android端
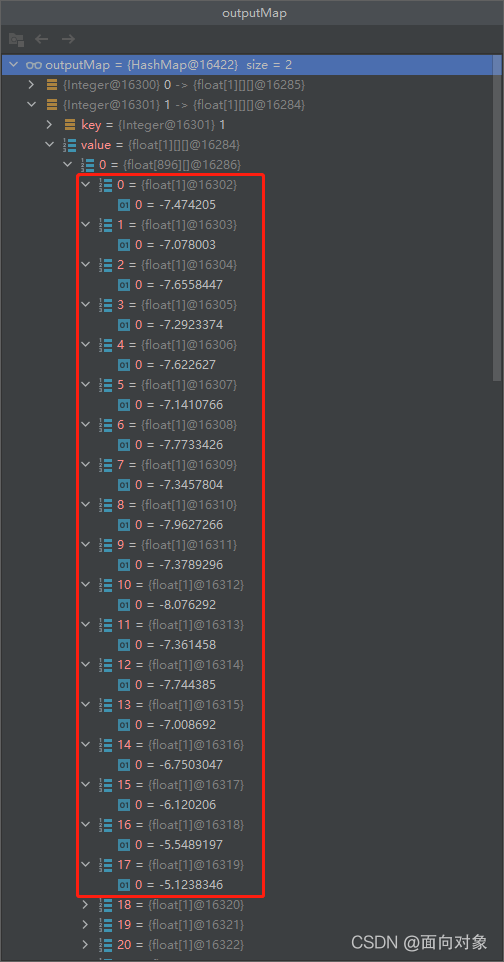
开发板端

到此这篇关于C++ TensorflowLite模型验证的文章就介绍到这了,更多相关C++ TensorflowLite模型验证内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
C++实现LeetCode(98.验证二叉搜索树)
[LeetCode] 98. Validate Binary Search Tree 验证二叉搜索树 Given a binary tree, determine if it is a valid binary search tree (BST). Assume a BST is defined as follows: The left subtree of a node contains only nodes with keys less than the node's key. The ri
-
c++验证哥德巴赫猜想
哥德巴赫猜想是世界近代三大数学难题之一.1742年,由德国中学教师哥德巴赫在教学中首先发现的.1742年6月7日哥德巴赫把自己的多年实验证明写信给当时的大数学家欧拉,欧拉回信正式提出了以下两个猜想:a.任何一个大于 6的偶数都可以表示成两个素数之和.b.任何一个大于9的奇数都可以表示成三个素数之和. 这就是哥德巴赫猜想. 复制代码 代码如下: //任一大于2的偶数,都可表示成两个素数之和.#include<iostream>using namespace std;int prime(int n
-

C++实现LeetCode(36.验证数独)
[LeetCode] 36. Valid Sudoku 验证数独 Determine if a 9x9 Sudoku board is valid. Only the filled cells need to be validated according to the following rules: Each row must contain the digits 1-9without repetition. Each column must contain the digits 1-9 wi
-
C++验证LeetCode包围区域的DFS方法
验证LeetCode Surrounded Regions 包围区域的DFS方法 在LeetCode中的Surrounded Regions 包围区域这道题中,我们发现用DFS方法中的最后一个条件必须是j > 1,如下面的红色字体所示,如果写成j > 0的话无法通过OJ,一直百思不得其解其中的原因,直到有网友告诉我说他验证了最后一个大集合在本地机子上可以通过,那么我也来验证看看吧. class Solution { public: void solve(vector<vector<
-
结构体对齐的规则详解及C++代码验证
目录 基本概念 结构体对齐的规则 程序验证 基本概念 CPU一次能读取多少个字节的数据主要是看数据总线是多少位的,16位CPU一次能读取2个字节,32位CPU一次能读取4个字节,64位CPU一次能读取8个字节.并且不能跨内存区间访问,这句话的意思可以理解为,如果CPU是32位的话,那么可以将整个内存区间每4个字节分为一块(BLOCK),每次读取一个BLOCK的数据. 那么对于下面这个结构体: struct st { char c; int i; }; 如果不进行对齐操作,char 的地址范围0x
-
C++ TensorflowLite模型验证的过程详解
故事是这样的: 有一个手撑检测的tflite模型,需要在开发板上跑起来.手机版本的已成熟,要移植到开发板上.现在要验证tflite模型文件在板子上的运行结果要和手机上一致. 前提:为了多次重复测试,在Android端使用了同一帧数据(从一个录制的mp4中固定取一张图)测试代码如下图 下面是测试过程 记录下Android版API运行推理前的图片数据文件(经过了规一化处理,所以都是-1~1之间的float数据) 这一步卡在了写float数据到二进制文件中,C++读出来有问题换了个方案,直接存储flo
-
Go gin权限验证实现过程详解
目录 权限管理 1. 特征 2. 怎么运行的 3. 安装 4. 示例代码 权限管理 Casbin是用于Golang项目的功能强大且高效的开源访问控制库. 1. 特征 Casbin的作用: 以经典{subject, object, action}形式或您定义的自定义形式实施策略,同时支持允许和拒绝授权. 处理访问控制模型及其策略的存储. 管理角色用户映射和角色角色映射(RBAC中的角色层次结构). 支持内置的超级用户,例如root或administrator.超级用户可以在没有显式权限的情况下执行
-
springmvc处理模型数据ModelAndView过程详解
这篇文章主要介绍了springmvc处理模型数据ModelAndView过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 springmvc提供了以下几种途径来输出模型数据: (1)ModelAndView:处理方法返回值类型为ModelAndView时,方法体即可通过该对象添加模型数据. (2)Map及Model:入参为org.springframework.ui.Model.org.springframework.ui.ModelMa
-
ASP.NET Core如何添加统一模型验证处理机制详解
一.前言 模型验证自ASP.NET MVC便有提供,我们可以在Model(DTO)的属性上加上数据注解(Data Annotations)特性,在进入Action之前便会根据数据注解,来验证输入的数据是否合法,下面介绍以下如何统一处理验证并返回错误信息.话不多说了,来一起看看详细的介绍吧. 二.Action过滤器实现统一验证 我们在判断验证状态时一般会在Action里判断ModelState.IsValid是否为true. public IActionResult Create([FromBod
-
基于PHP实现邮箱验证激活过程详解
我们在很多网站注册会员时,注册完成后,系统会自动向用户的邮箱发送一封邮件,这封邮件的内容就是一个URL链接,用户需要点击打开这个链接才能激活之前在该网站注册的帐号.激活成功后才能正常使用会员功能. 本文将结合实例,讲解如何使用PHP+Mysql完成注册帐号.发送激活邮件.验证激活帐号.处理URL链接过期的功能. 业务流程 1.用户提交注册信息. 2.写入数据库,此时帐号状态未激活. 3.将用户名密码或其他标识字符加密构造成激活识别码(你也可以叫激活码). 4.将构造好的激活识别码组成URL发送到
-
Anaconda+vscode+pytorch环境搭建过程详解
1.安装Anaconda Anaconda指的是一个开源的Python发行版本,其包含了conda.Python等180多个科学包及其依赖项.在官网上下载https://www.anaconda.com/distribution/,因为服务器在国外会很慢,建议从清华镜像https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/下载. 2.安装VScode 需要在Anaconda再装VScode,因为Anaconda公司和微软公司的合作,不用在对进
-
sklearn和keras的数据切分与交叉验证的实例详解
在训练深度学习模型的时候,通常将数据集切分为训练集和验证集.Keras提供了两种评估模型性能的方法: 使用自动切分的验证集 使用手动切分的验证集 一.自动切分 在Keras中,可以从数据集中切分出一部分作为验证集,并且在每次迭代(epoch)时在验证集中评估模型的性能. 具体地,调用model.fit()训练模型时,可通过validation_split参数来指定从数据集中切分出验证集的比例. # MLP with automatic validation set from keras.mode
-
Tensorflow2.4使用Tuner选择模型最佳超参详解
目录 前言 实现过程 1. 获取 MNIST 数据并进行处理 2. 搭建超模型 3. 实例化调节器并进行模型超调 4. 训练模型获得最佳 epoch 5. 使用最有超参数集进行模型训练和评估 前言 本文使用 cpu 版本的 tensorflow 2.4 ,选用 Keras Tuner 工具以 Fashion 数据集的分类任务为例,完成最优超参数的快速选择任务. 当我们搭建完成深度学习模型结构之后,我们在训练模型的过程中,有很大一部分工作主要是通过验证集评估指标,来不断调节模型的超参数,这是比较耗
-
OpenAI的Whisper模型进行语音识别使用详解
目录 正文 Whisper 模型介绍 使用Whisper 模型进行语音识别 总结 正文 语音识别是人工智能中的一个领域,它允许计算机理解人类语音并将其转换为文本.该技术用于 Alexa 和各种聊天机器人应用程序等设备.而我们最常见的就是语音转录,语音转录可以语音转换为文字记录或字幕. wav2vec2.Conformer 和 Hubert 等最先进模型的最新发展极大地推动了语音识别领域的发展.这些模型采用无需人工标记数据即可从原始音频中学习的技术,从而使它们能够有效地使用未标记语音的大型数据集.
-
Yii2框架数据验证操作实例详解
本文实例讲述了Yii2框架数据验证操作.分享给大家供大家参考,具体如下: 一.场景 什么情况下需要使用场景呢?当一个模型需要在不同情境中使用时,若不同情境下需要的数据表字段和数据验证规则有所不同,则需要定义多个场景来区分不同使用情境.例如,用户注册的时候需要填写email,登录的时候则不需要,这时就需要定义两个不同场景加以区分. 默认情况下模型的场景是由rules()方法申明的验证规则中使用到的场景决定的,也可以通过覆盖scenarios()方法来更具体地定义模型的所有场景,例如: public