Python爬虫和反爬技术过程详解
目录
- 一、浏览器模拟(Headers)
- 如何找到浏览器信息
- 打开浏览器,按F12(或者鼠标右键+检查)
- 点击如下图所示的Network按钮
- 按键盘Ctrl+R(MAC:Command+R)进行抓包
- 在Python中使用user-agent的方式如下:
- 常用的请求头(模拟浏览器)信息如下:
- 二、IP代理
- Python使用IP代理的方式如下:
- 控制访问频率使用time模块即可:
- 三、Cookies模拟
- 手动获取cookie
- 自动获取cookie
- 使用cookies
一、浏览器模拟(Headers)
浏览器模拟是最常用的一种反爬方式。设想一下:一个网站不停的被同一个版本的浏览器频率的访问,那大概了就要被认为是机器人了。所以上有政策下有对策,我们每次访问都使用不同的浏览器版本信息不就可以了吗。首先我们来看一下如何找到自己浏览器信息。
如何找到浏览器信息
打开浏览器,按F12(或者鼠标右键+检查)
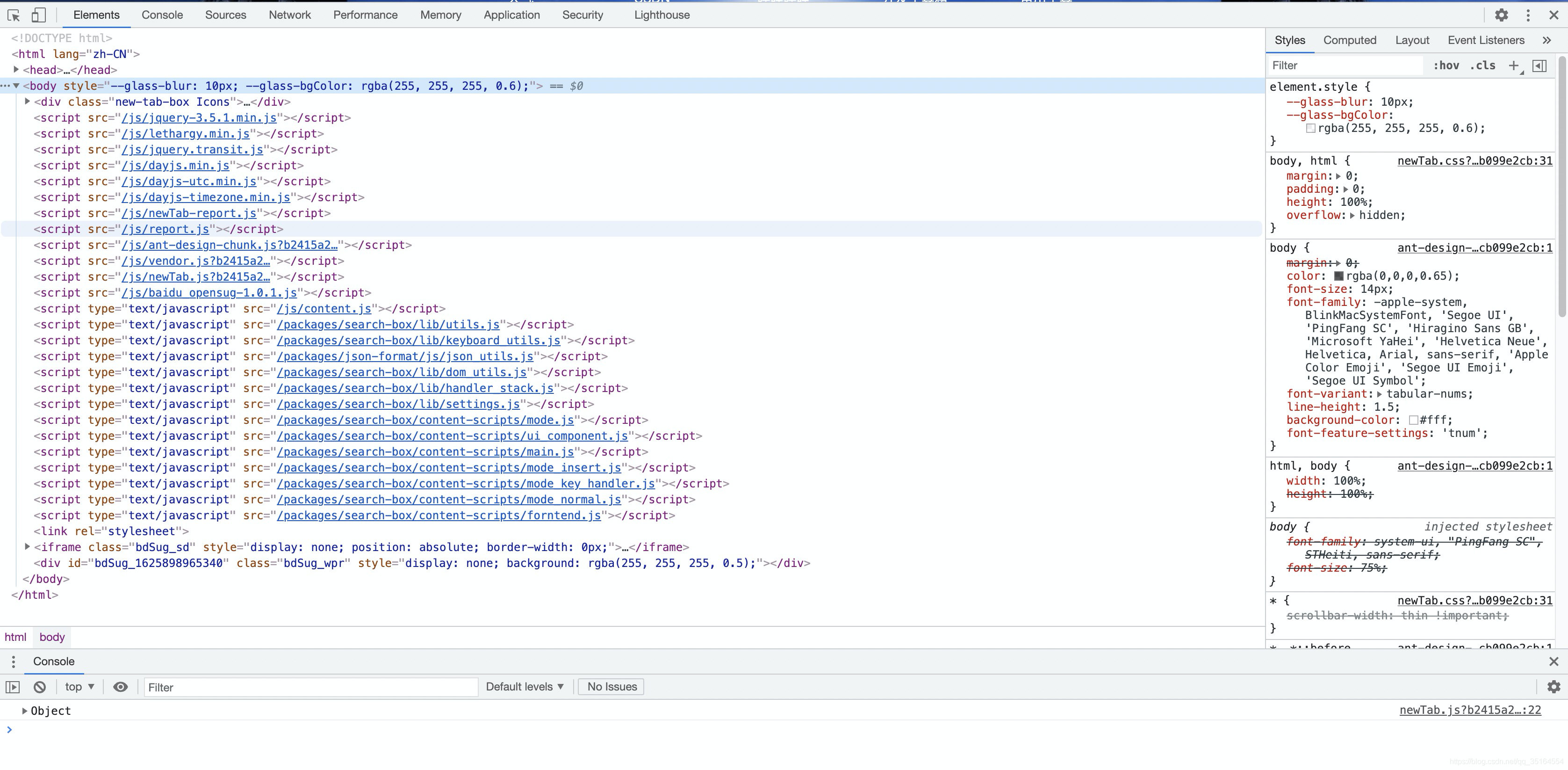
点击如下图所示的Network按钮

按键盘Ctrl+R(MAC:Command+R)进行抓包
操作完上一步之后,随便点击右侧name中的一项,即可出现下面的页面,红框中的内容就是我们要找的浏览器信息了。
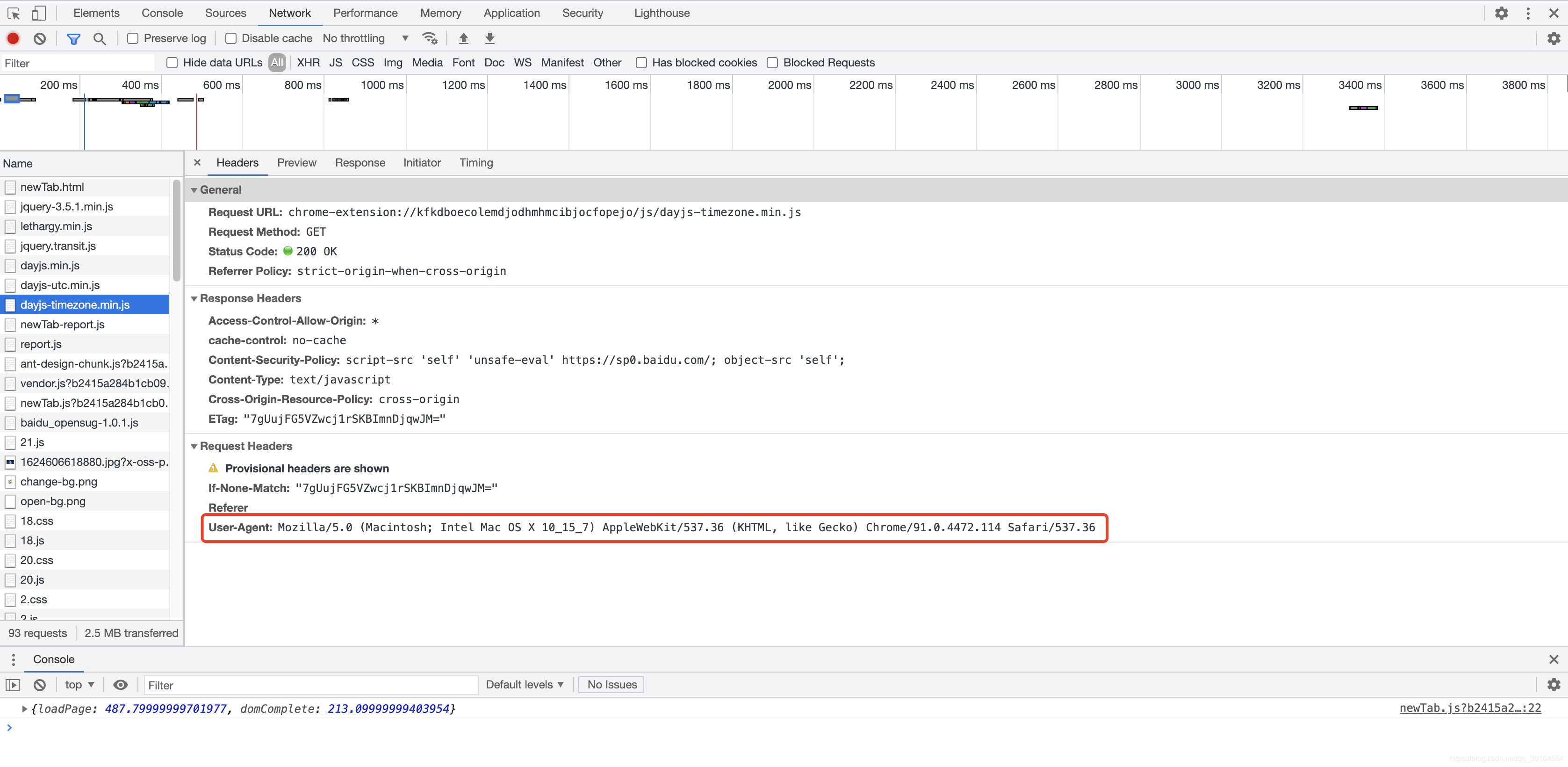
备注:有一些网站会带有Referer信息,这里的作用主要是在于告诉浏览器你是从哪个网址跳转过来的,类似于P站这种站点就会进行相应的检查,所以我们可以通过上述同样的方式找到浏览器的Referer信息。如下图红框所示:
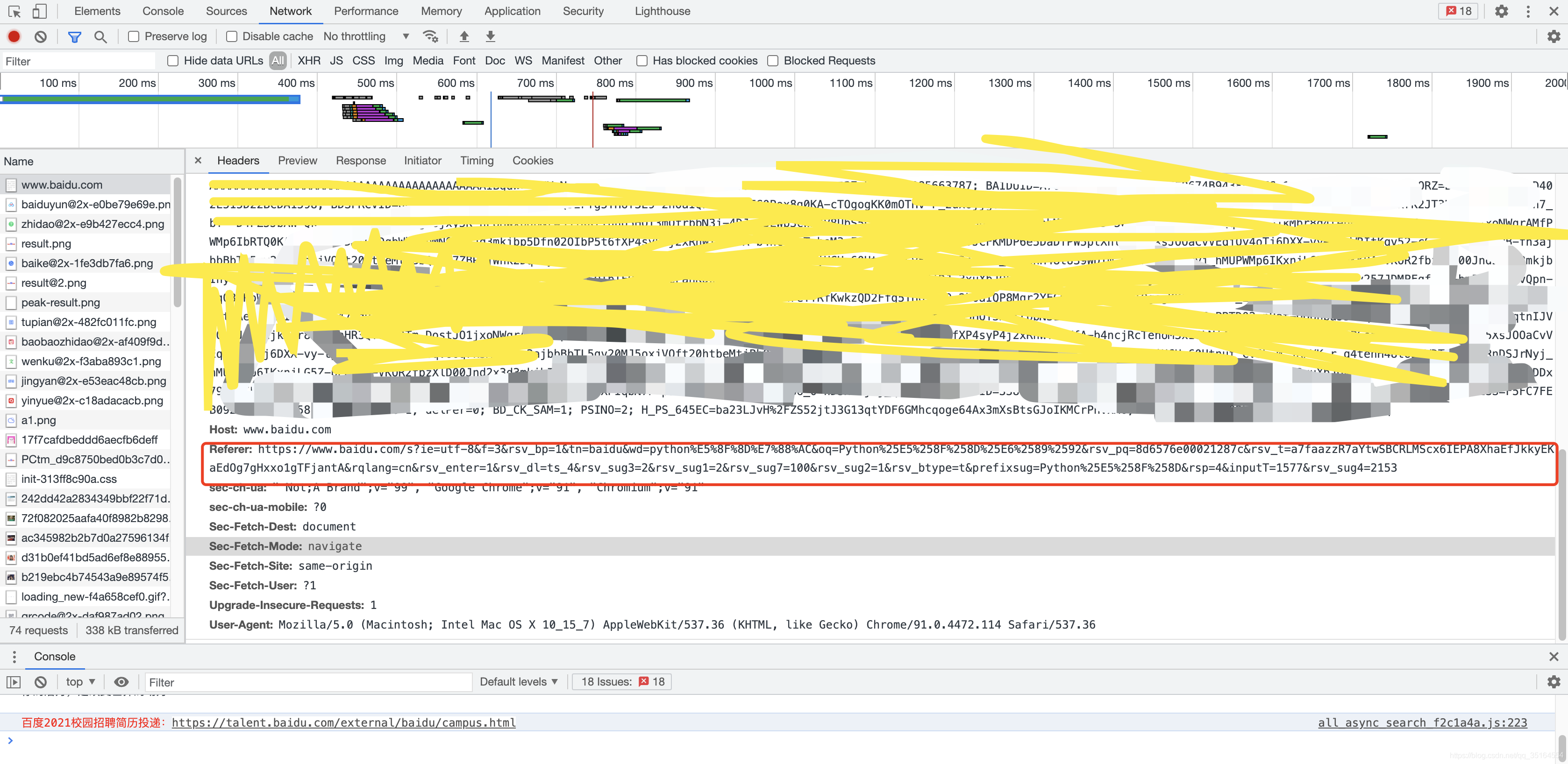
通过上面的步骤,我们就能够成功的得到浏览器的版本信息了,如果能够获得不同的版本信息我们就能够模拟不同的浏览器进行操作了。
在Python中使用user-agent的方式如下:
headers = {
'Referer': '具体的Referer',
'User-Agent': '具体的user-agent'
}
requests.get(url,headers=headers)
常用的请求头(模拟浏览器)信息如下:
User_Agent = [
"Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_2 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8H7 Safari/6533.18.5",
"Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_2 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8H7 Safari/6533.18.5",
"MQQBrowser/25 (Linux; U; 2.3.3; zh-cn; HTC Desire S Build/GRI40;480*800)",
"Mozilla/5.0 (Linux; U; Android 2.3.3; zh-cn; HTC_DesireS_S510e Build/GRI40) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Mozilla/5.0 (SymbianOS/9.3; U; Series60/3.2 NokiaE75-1 /110.48.125 Profile/MIDP-2.1 Configuration/CLDC-1.1 ) AppleWebKit/413 (KHTML, like Gecko) Safari/413",
"Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Mobile/8J2",
"Mozilla/5.0 (Windows NT 5.2) AppleWebKit/534.30 (KHTML, like Gecko) Chrome/12.0.742.122 Safari/534.30",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.202 Safari/535.1",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/534.51.22 (KHTML, like Gecko) Version/5.1.1 Safari/534.51.22",
"Mozilla/5.0 (iPhone; CPU iPhone OS 5_0 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A5313e Safari/7534.48.3",
"Mozilla/5.0 (iPhone; CPU iPhone OS 5_0 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A5313e Safari/7534.48.3",
"Mozilla/5.0 (iPhone; CPU iPhone OS 5_0 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A5313e Safari/7534.48.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.202 Safari/535.1",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; SAMSUNG; OMNIA7)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; XBLWP7; ZuneWP7)",
"Mozilla/5.0 (Windows NT 5.2) AppleWebKit/534.30 (KHTML, like Gecko) Chrome/12.0.742.122 Safari/534.30",
"Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.2; Trident/4.0; .NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET4.0E; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET4.0E; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C)",
"Mozilla/4.0 (compatible; MSIE 60; Windows NT 5.1; SV1; .NET CLR 2.0.50727)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Opera/9.80 (Windows NT 5.1; U; zh-cn) Presto/2.9.168 Version/11.50",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022; .NET4.0E; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/533.21.1 (KHTML, like Gecko) Version/5.0.5 Safari/533.21.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; ) AppleWebKit/534.12 (KHTML, like Gecko) Maxthon/3.0 Safari/534.12",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; TheWorld)",
"Opera/9.80 (X11; Linux i686; Ubuntu/14.10) Presto/2.12.388 Version/12.16",
"Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14",
"Mozilla/5.0 (Windows NT 6.0; rv:2.0) Gecko/20100101 Firefox/4.0 Opera 12.14",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0) Opera 12.14",
"Opera/12.80 (Windows NT 5.1; U; en) Presto/2.10.289 Version/12.02",
"Opera/9.80 (Windows NT 6.1; U; es-ES) Presto/2.9.181 Version/12.00",
"Opera/9.80 (Windows NT 5.1; U; zh-sg) Presto/2.9.181 Version/12.00",
"Opera/12.0(Windows NT 5.2;U;en)Presto/22.9.168 Version/12.00",
"Opera/12.0(Windows NT 5.1;U;en)Presto/22.9.168 Version/12.00",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1",
"Mozilla/5.0 (Windows NT 6.3; rv:36.0) Gecko/20100101 Firefox/36.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10; rv:33.0) Gecko/20100101 Firefox/33.0",
"Mozilla/5.0 (X11; Linux i586; rv:31.0) Gecko/20100101 Firefox/31.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:31.0) Gecko/20130401 Firefox/31.0",
"Mozilla/5.0 (Windows NT 5.1; rv:31.0) Gecko/20100101 Firefox/31.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:29.0) Gecko/20120101 Firefox/29.0",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:25.0) Gecko/20100101 Firefox/29.0",
"Mozilla/5.0 (X11; OpenBSD amd64; rv:28.0) Gecko/20100101 Firefox/28.0",
"Mozilla/5.0 (X11; Linux x86_64; rv:28.0) Gecko/20100101 Firefox/28.0",
"Mozilla/5.0 (Windows NT 6.1; rv:27.3) Gecko/20130101 Firefox/27.3",
"Mozilla/5.0 (Windows NT 6.2; Win64; x64; rv:27.0) Gecko/20121011 Firefox/27.0",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:25.0) Gecko/20100101 Firefox/25.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:25.0) Gecko/20100101 Firefox/25.0",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:24.0) Gecko/20100101 Firefox/24.0",
"Mozilla/5.0 (Windows NT 6.0; WOW64; rv:24.0) Gecko/20100101 Firefox/24.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:24.0) Gecko/20100101 Firefox/24.0"
]
二、IP代理
除了通过同一个浏览器进行访问,还可能出现的情况就是通过同一个IP不断的访问网址,这样很容易造成整个IP被封,个人的IP还好,如果一个公司的IP都不能访问某个网站,那将会是怎样的效果就不用多说了吧。
对于IP来说除了需要控制IP地址的变更之外,还要控制访问速度,毕竟程序快起来是不眨眼的。
Python使用IP代理的方式如下:
import requests
proxies = {"http": 'IP地址'}
requests.get(url, headers=headers, proxies=proxies)
注:关于代理IP去哪找的问题,网上一搜一大把,我们放心大胆的使用就可以了。
控制访问频率使用time模块即可:
import time time.sleep(5)
三、Cookies模拟
有很多时候我们访问网址会遇到403错误,一般这种情况表示无权访问请求的资源,通常在没有设置cookie或是没有设置正确的cookie会导致这个错误。cookie的存在就像是一个网址的通行证,你会发现在你登陆和未登陆网页的时候cookie是会发生变化的。
手动获取cookie
我们可以通过和获取user-agent一样的方式来手动获取cookie:

自动获取cookie
我们使用session方法就能够实现自动获取cookie了
示例代码如下:
import requests
session = requests.session()
session.cookies = LWPCookieJar(filename='Cookies.txt')
def login():
name = input("输入账户:")
password = input("输入密码:")
url = "url"
data = {
"ck": "",
"name": name,
"password": password,
"remember": "True",
"ticket": "",
}
response = session.post(url, data=data)
print(response.text)
session.cookies.save() # 保存 cookie
这样我们的cookie就能够得以保存了。
使用session加载cookie的方式如下:
session.cookies = LWPCookieJar(filename='Cookies.txt') session.cookies.load(ignore_discard=True)
使用cookies
当我们有了cookies时,使用起来就简单很多了,直接使用和加载user-agent一样的方式即可。
headers = {
'Referer': '具体的Referer',
'User-Agent': '具体的user-agent',
'Cookie': 'cookie'
}
requests.get(url,headers=headers)
对于反爬的一些基础操作就介绍完了更多关于Python爬虫和反爬技术的资料请关注我们其它相关文章!
相关推荐
-
python中绕过反爬虫的方法总结
我们在登山的途中,有不同的路线可以到达终点.因为选择的路线不同,上山的难度也有区别.就像最近几天教大家获取数据的时候,断断续续的讲过header.地址ip等一些的方法.具体的爬取方法相信大家已经掌握住,本篇小编主要是给大家进行应对反爬虫方法的一个梳理,在进行方法回顾的同时查漏补缺,建立系统的爬虫知识框架. 首先分析要爬的网站,本质是一个信息查询系统,提供了搜索页面.例如我想获取某个case,需要利用这个case的id或者name字段,才能搜索到这个case的页面. 出于对安全的考虑,有些网站会做
-

Python反爬虫技术之防止IP地址被封杀的讲解
在使用爬虫爬取别的网站的数据的时候,如果爬取频次过快,或者因为一些别的原因,被对方网站识别出爬虫后,自己的IP地址就面临着被封杀的风险.一旦IP被封杀,那么爬虫就再也爬取不到数据了. 那么常见的更改爬虫IP的方法有哪些呢? 1,使用动态IP拨号器服务器. 动态IP拨号服务器的IP地址是可以动态修改的.其实动态IP拨号服务器并不是什么高大上的服务器,相反,属于配置很低的一种服务器.我们之所以使用动态IP拨号服务器,不是看中了它的计算能力,而是能够实现秒换IP. 动态IP拨号服务器有一个特点,就是每
-
python 常见的反爬虫策略
1.判断请求头来进行反爬 这是很早期的网站进行的反爬方式 User-Agent 用户代理 referer 请求来自哪里 cookie 也可以用来做访问凭证 解决办法:请求头里面添加对应的参数(复制浏览器里面的数据) 2.根据用户行为来进行反爬 请求频率过高,服务器设置规定时间之内的请求阈值 解决办法:降低请求频率或者使用代理(IP代理) 网页中设置一些陷阱(正常用户访问不到但是爬虫可以访问到) 解决办法:分析网页,避开这些特殊陷阱 请求间隔太短,返回相同的数据 解决办法:增加请求间隔 3.js加
-
python解决网站的反爬虫策略总结
本文详细介绍了网站的反爬虫策略,在这里把我写爬虫以来遇到的各种反爬虫策略和应对的方法总结一下. 从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分.这里我们只讨论数据采集部分. 一般网站从三个方面反爬虫:用户请求的Headers,用户行为,网站目录和数据加载方式.前两种比较容易遇到,大多数网站都从这些角度来反爬虫.第三种一些应用ajax的网站会采用,这样增大了爬取的难度(防止静态爬虫使用ajax技术动态加载页面). 1.从用户请求的Headers反爬虫是最常见的反爬虫策略. 伪装header
-
Python常见反爬虫机制解决方案
1.使用代理 适用情况:限制IP地址情况,也可解决由于"频繁点击"而需要输入验证码登陆的情况. 这种情况最好的办法就是维护一个代理IP池,网上有很多免费的代理IP,良莠不齐,可以通过筛选找到能用的.对于"频繁点击"的情况,我们还可以通过限制爬虫访问网站的频率来避免被网站禁掉. proxies = {'http':'http://XX.XX.XX.XX:XXXX'} Requests: import requests response = requests.get(u
-
Python中常见的反爬机制及其破解方法总结
一.常见反爬机制及其破解方式 封禁IP,使用cookie等前面文章已经讲过 现在主要将下面的: ~ 验证码 -> 文字验证码 -> OCR(光学文字识别)-> 接口 / easyocr 程序自己解决不了的问题就可以考虑使用三方接口(付费/免费) -> 行为验证码 -> 超级鹰 ~ 手机号+短信验证码 -> 接码平台 ~ 动态内容 -> JavaScript逆向 -> 找到提供数据的API接口 -> 手机抓接口 -&g
-
Python爬虫和反爬技术过程详解
目录 一.浏览器模拟(Headers) 如何找到浏览器信息 打开浏览器,按F12(或者鼠标右键+检查) 点击如下图所示的Network按钮 按键盘Ctrl+R(MAC:Command+R)进行抓包 在Python中使用user-agent的方式如下: 常用的请求头(模拟浏览器)信息如下: 二.IP代理 Python使用IP代理的方式如下: 控制访问频率使用time模块即可: 三.Cookies模拟 手动获取cookie 自动获取cookie 使用cookies 一.浏览器模拟(Headers)
-
python爬虫破解字体加密案例详解
本次案例以爬取起小点小说为例 案例目的: 通过爬取起小点小说月票榜的名称和月票数,介绍如何破解字体加密的反爬,将加密的数据转化成明文数据. 程序功能: 输入要爬取的页数,得到每一页对应的小说名称和月票数. 案例分析: 找到目标的url: (右键检查)找到小说名称所在的位置: 通过名称所在的节点位置,找到小说名称的xpath语法: (右键检查)找到月票数所在的位置: 由上图发现,检查月票数据的文本,得到一串加密数据. 我们通过xpathhelper进行调试发现,无法找到加密数据的语法.因此,需要通
-
python爬虫系列网络请求案例详解
学习了之前的基础和爬虫基础之后,我们要开始学习网络请求了. 先来看看urllib urllib的介绍 urllib是Python自带的标准库中用于网络请求的库,无需安装,直接引用即可. 主要用来做爬虫开发,API数据获取和测试中使用. urllib库的四大模块: urllib.request: 用于打开和读取url urllib.error : 包含提出的例外,urllib.request urllib.parse:用于解析url urllib.robotparser:用于解析robots.tx
-
python爬虫---requests库的用法详解
requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多 因为是第三方库,所以使用前需要cmd安装 pip install requests 安装完成后import一下,正常则说明可以开始使用了. 基本用法: requests.get()用于请求目标网站,类型是一个HTTPresponse类型 import requests response = requests.get('http://www.baidu.com')print(response.status_c
-
python爬虫中多线程的使用详解
queue介绍 queue是python的标准库,俗称队列.可以直接import引用,在python2.x中,模块名为Queue.python3直接queue即可 在python中,多个线程之间的数据是共享的,多个线程进行数据交换的时候,不能够保证数据的安全性和一致性,所以当多个线程需要进行数据交换的时候,队列就出现了,队列可以完美解决线程间的数据交换,保证线程间数据的安全性和一致性. #多线程实战栗子(糗百) #用一个队列Queue对象, #先产生所有url,put进队列: #开启多线程,把q
-
python爬虫泛滥的解决方法详解
我们可以把互联网上搬运数据的程序看成小蚂蚁,它们需要采集不同的食物带回洞里存储.但是大家也知道白蚁泛滥的事件,在我们的网络环境里,如果爬虫都集中在某几个位置,最直接的结果就是这个网站的拥挤.对于我们这些网站访问者而言也不是好事情,首先网页的页面会被卡住.网站的管理人员面对爬虫过多,这时候就要进行一系列的限制措施了,这里小编分了两个大的应对方向,从不同的角度进 行分析爬虫过多的解决思路. 一.识别爬虫 1. HTTP请求头 这算是最基础的网络爬虫识别了,正常的网络访问者都是通过浏览器对网站进行访问
-
Python爬虫 urllib2的使用方法详解
所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地.在Python中有很多库可以用来抓取网页,我们先学习urllib2. urllib2是Python2.x自带的模块(不需要下载,导入即可使用) urllib2官网文档:https://docs.python.org/2/library/urllib2.html urllib2源码 urllib2在python3.x中被改为urllib.request urlopen 我们先来段代码: #-*- coding:utf-8
-
Python实现微博动态图片爬取详解
由于微博的网页端有反爬虫,需要登录,所以我们换个思路,曲线救国. 我们找到微博在浏览器上面用于手机端的调试的APL,如何找到呢? 我这边直接附上微博的手机端的地址:https://m.weibo.cn/ 1.模拟搜索用户 搜索一个用户获取到的api: https://m.weibo.cn/api/container/getIndex?containerid=100103type=1&q=半半子&page_type=searchall 1.1 对api内参数进行处理 containerid=
-
python分布式爬虫中消息队列知识点详解
当排队等待人数过多的时候,我们需要设置一个等待区防止秩序混乱,同时再有新来的想要排队也可以呆在这个地方.那么在python分布式爬虫中,消息队列就相当于这样的一个区域,爬虫要进入这个区域找寻自己想要的资源,当然这个是一定的次序的,不然数据获取就会出现重复.就下来我们就python分布式爬虫中的消息队列进行详细解释,小伙伴们可以进一步了解一下. 实现分布式爬取的关键是消息队列,这个问题以消费端为视角更容易理解.你的爬虫程序部署到很多台机器上,那么他们怎么知道自己要爬什么呢?总要有一个地方存储了他们
-
Python中Pyspider爬虫框架的基本使用详解
1.pyspider介绍 一个国人编写的强大的网络爬虫系统并带有强大的WebUI.采用Python语言编写,分布式架构,支持多种数据库后端,强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器. 用Python编写脚本 功能强大的WebUI,包含脚本编辑器,任务监视器,项目管理器和结果查看器 MySQL,MongoDB,Redis,SQLite,Elasticsearch; PostgreSQL与SQLAlchemy作为数据库后端 RabbitMQ,Beanstalk,Redis