Java数据结构中图的进阶详解
目录
- 有向图
- 有向图API设计
- 有向图的实现
- 拓扑排序
- 拓扑排序图解
- 检测有向图中的环
- 检测有向环的API设计
- 检测有向环实现
- 代码
- 基于深度优先的顶点排序
- 顶点排序API设计
- 顶点排序实现
- 代码:
有向图
有向图的定义及相关术语
定义∶ 有向图是一副具有方向性的图,是由一组顶点和一组有方向的边组成的,每条方向的边都连着 一对有序的顶点。
出度∶ 由某个顶点指出的边的个数称为该顶点的出度。
入度: 指向某个顶点的边的个数称为该顶点的入度。
有向路径︰ 由一系列顶点组成,对于其中的每个顶点都存在一条有向边,从它指向序列中的下一个顶点。
有向环∶ —条至少含有一条边,且起点和终点相同的有向路径。
一副有向图中两个顶点v和w可能存在以下四种关系:
1.没有边相连;
⒉存在从v到w的边v—>w;
3.存在从w到v的边w—>V;
4.既存在w到v的边,也存在v到w的边,即双向连接;
理解有向图是一件比较简单的,但如果要通过眼睛看出复杂有向图中的路径就不是那么容易了。
有向图API设计
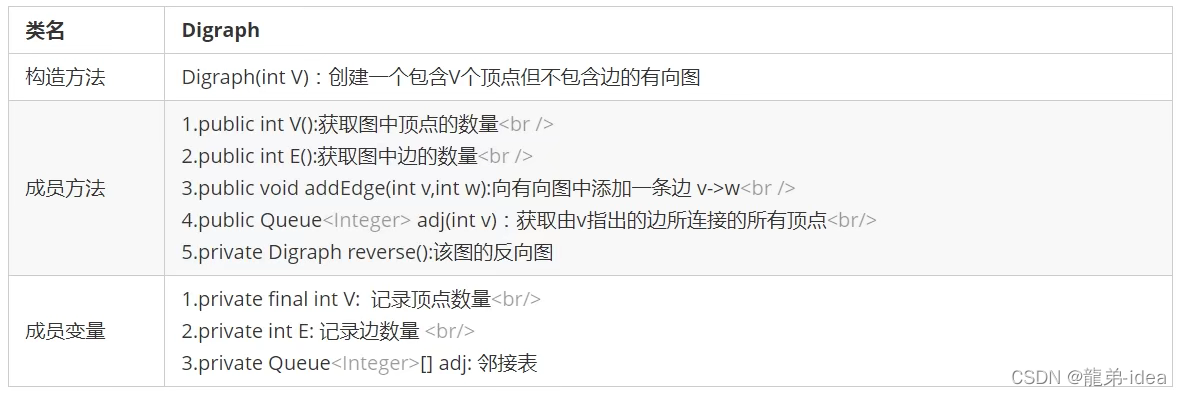
在api中设计了一个反向图,其因为有向图的实现中,用adj方法获取出来的是由当前顶点v指向的其他顶点,如果能得到其反向图,就可以很容易得到指向v的其他顶点。
有向图的实现
// 有向图
public class Digraph {
// 记录顶点的数量
private final int V;
//记录边的数量
private int E;
//定义有向图的邻接表
private Queue <Integer>[] adj;
public Digraph (int v) {
//初始化顶点数量
this.V = v;
//初始化边的数量
this.E = 0;
//初始化邻接表
adj = new LinkedList[v];
//初始化邻接表的空队列
for (int i = 0; i < v; i++) {
adj[i] = new LinkedList<>();
}
}
public int V () {
return V;
}
public int E () {
return E;
}
//添加一条 v -> w的有向边
public void addEage (int v , int w) {
adj[v].add(w);
++E;
}
//获取顶点v 指向的 所有顶点
public Queue<Integer> adj (int v) {
return adj[v];
}
//将有向图 反转 后返回
public Digraph reverse () {
//创建一个反向图
Digraph reverseDigraph = new Digraph(V);
//获取原来有向图的每个结点
for (int i = 0; i < V; i++) {
//获取每个结点 邻接表的所有结点
for (Integer w : adj[i]) {
//反转图记录下 w -> v
reverseDigraph.adj(w).add(i);
}
}
return reverseDigraph;
}
}
拓扑排序
在现实生活中,我们经常会同一时间接到很多任务去完成,但是这些任务的完成是有先后次序的。以我们学习java学科为例,我们需要学习很多知识,但是这些知识在学习的过程中是需要按照先后次序来完成的。从java基础,到jsp/servlet,到ssm,到springboot等是个循序渐进且有依赖的过程。在学习jsp前要首先掌握java基础和html基础,学习ssm框架前要掌握jsp/servlet之类才行。
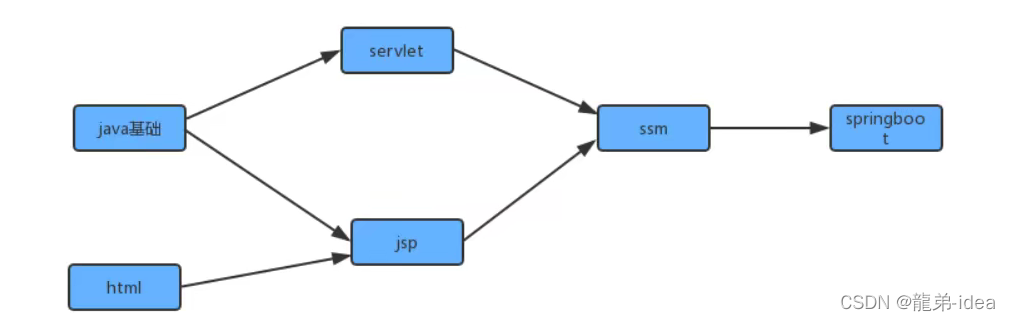
为了简化问题,我们使用整数为顶点编号的标准模型来表示这个案例:
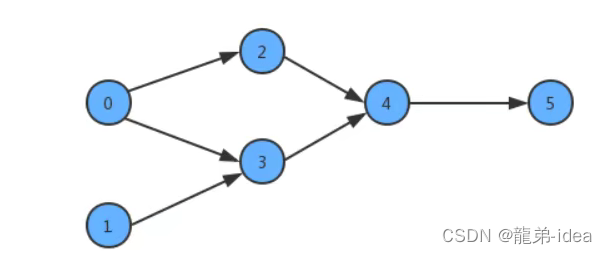
此时如果某个同学要学习这些课程,就需要指定出一个学习的方案,我们只需要对图中的顶点进行排序,让它转换为一个线性序列,就可以解决问题,这时就需要用到一种叫拓扑排序的算法。
拓扑排序图解
给定一副有向图,将所有的顶点排序,使得所有的有向边均从排在前面的元素指向排在后面的元素,此时就可以明确的表示出每个顶点的优先级。下列是一副拓扑排序后的示意图︰
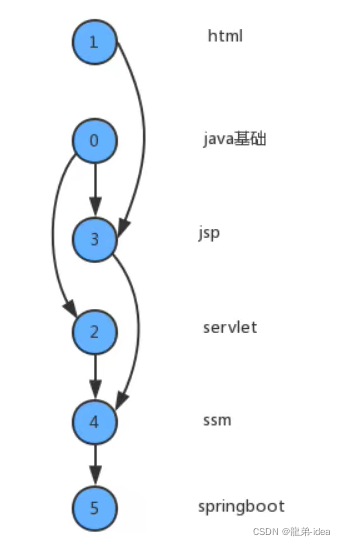
检测有向图中的环
如果学习x课程前必须先学习y课程,学习y课程前必须先学习z课程,学习z课程前必须先学习x课程,那么一定是有问题了,我们就没有办法学习了,因为这三个条件没有办法同时满足。其实这三门课程x、y、z的条件组成了一个环︰
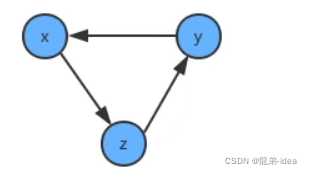
因此,如果我们要使用拓扑排序解决优先级问题,首先得保证图中没有环的存在。
检测有向环的API设计
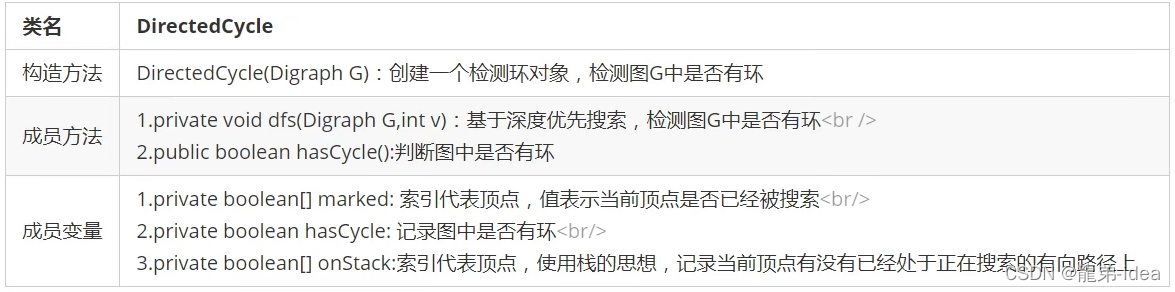
检测有向环实现
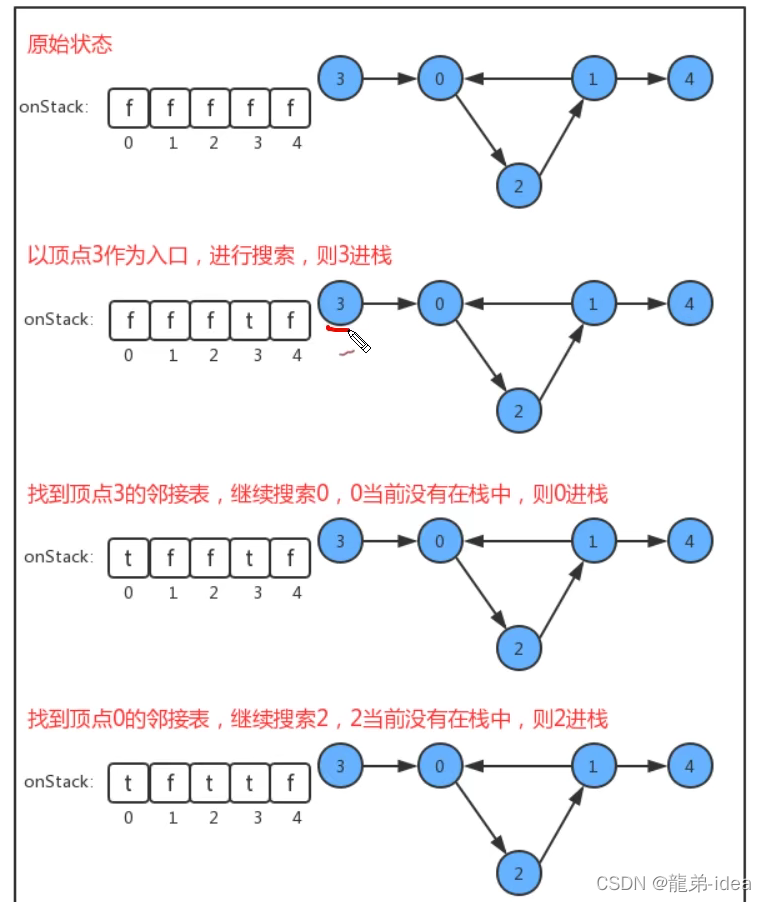
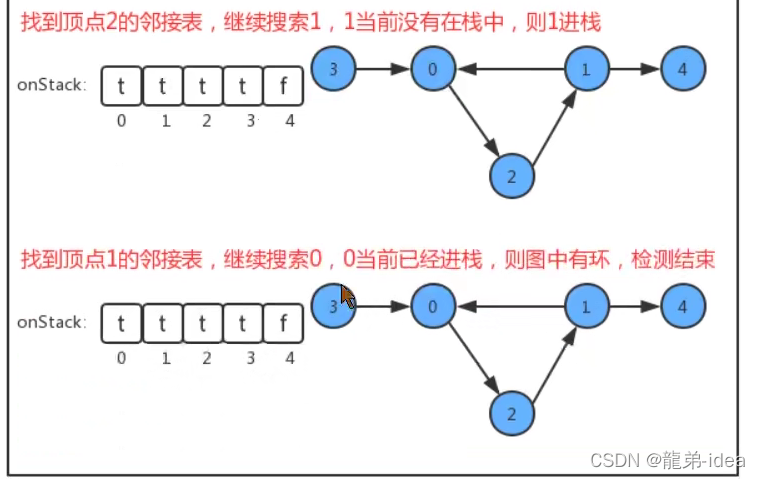
在API中添加了onStack[]布尔数组,索引为图的顶点,当我们深度搜索时︰
1.在如果当前顶点正在搜索,则把对应的onStack数组中的值改为true,标识进栈;
2.如果当前顶点搜索完毕,则把对应的onStack数组中的值改为false,标识出栈;
3.如果即将要搜索某个顶点,但该顶点已经在栈中,则图中有环;
代码
/**
* 检查图中是否存在环
*/
public class DirectedCycle {
/**
* 索引代表顶点,用来记录顶点是否被搜索过
*/
private boolean[] marked;
/**
* 判断图中是否有环
*/
private boolean hasCycle;
/**
* 采用栈的思想,记录当前顶点是否已经存在 当前搜索的的路径上
* 存在则可以判断 图中是存在环的
*/
private boolean[] onStack;
/**
* 判断传入的有向图 是否存在环
* @param G
*/
public DirectedCycle (Digraph G) {
marked = new boolean[G.V()];
onStack = new boolean[G.V()];
hasCycle = false;
//因为不知道从那个点出发 可能存在环
//所以需要从所有的顶点都出发搜索 判断是否存在环
for (int i = 0; i < G.V(); i++) {
dfs(G,i);
}
}
/**
* 采用深度搜索 判断有向图是否存在环
* onStack 入栈出栈 然后判断当前搜索的顶点是否已经在搜索路径上
*
* @param G
* @param v
*/
private void dfs (Digraph G,int v) {
//标记顶点已经搜索过
marked[v] = true;
for (Integer adj : G.adj(v)) {
//判断v 是否已经在搜索的路径上了
if(marked[adj] && onStack[adj]) {
//存在环
hasCycle = true;
}else {
//采用回溯的思路
//让顶点入栈
onStack[adj] = true;
dfs(G,adj);
//回溯 顶点出栈
onStack[adj] = false;
}
}
}
/**
* 判断是否存在环
* @return
*/
public boolean hasCycle(){
return hasCycle;
}
}
基于深度优先的顶点排序
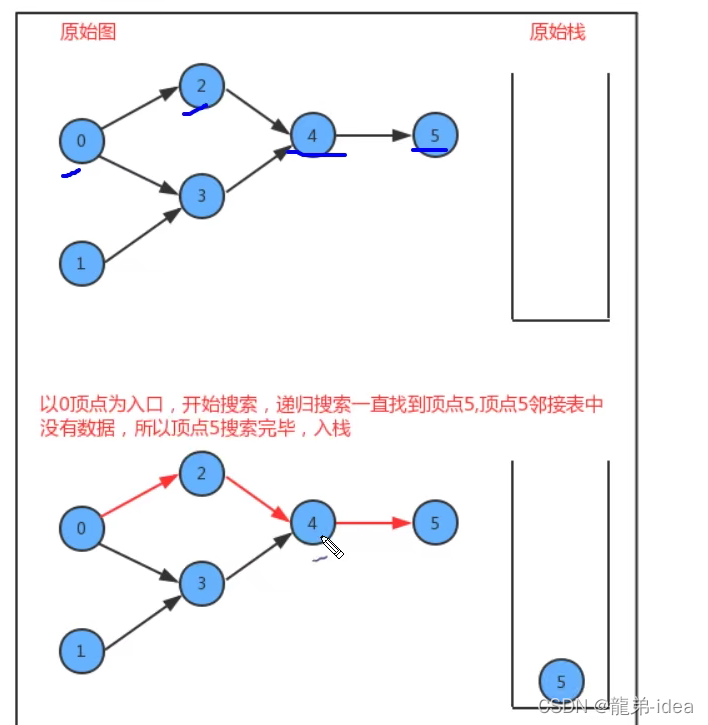
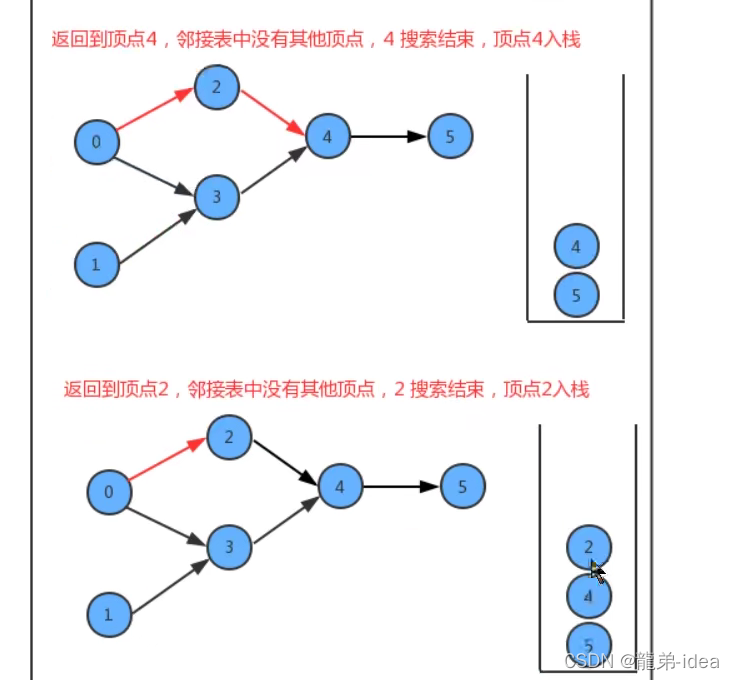
如果要把图中的顶点生成线性序列其实是一件非常简单的事,之前我们学习并使用了多次深度优先搜索,我们会发现其实深度优先搜索有一个特点,那就是在一个连通子图上,每个顶点只会被搜索一次,如果我们能在深度优先搜索的基础上,添加一行代码,只需要将搜索的顶点放入到线性序列的数据结构中,我们就能完成这件事。
顶点排序API设计

顶点排序实现
在API的设计中,我们添加了一个栈reversePost用来存储顶点,当我们深度搜索图时,每搜索完毕一个顶点,把该顶点放入到reversePost中,这样就可以实现顶点排序。
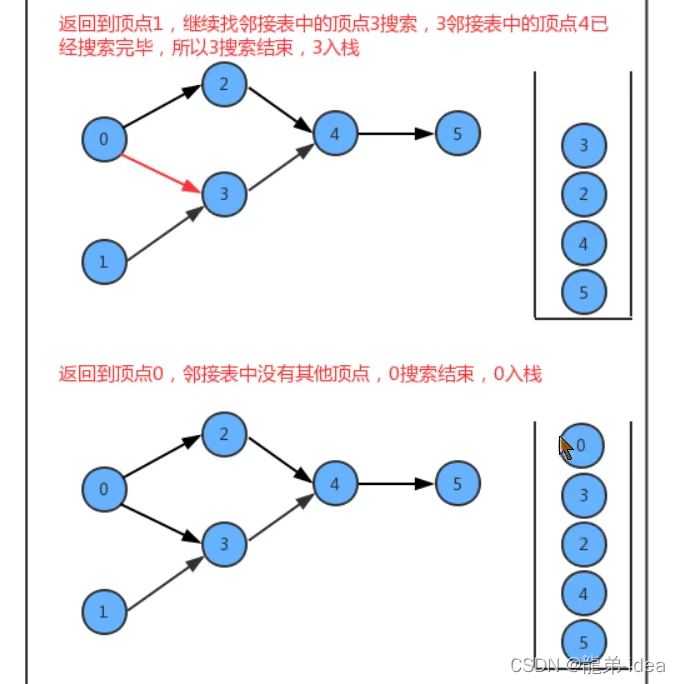
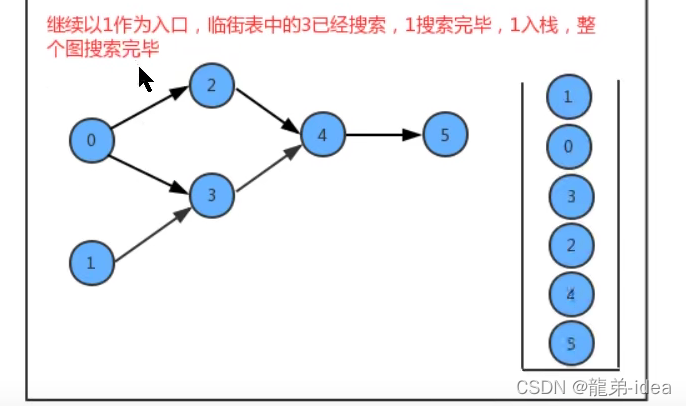
代码:
/**
* 深度优先搜索 的顶点排序
*/
public class DepthFirstOrder {
/**
* 索引代表顶点 ,用来记录顶点是否已经被搜索过了
*/
private boolean[] marked;
/**
* 使用栈记录深度优先搜索下的顶点
*/
private Stack<Integer> reversePost;
public DepthFirstOrder (Digraph G) {
marked = new boolean[G.V()];
reversePost = new Stack<>();
for (int i = 0; i < G.V(); i++) {
//如果顶点已经被搜索过则不用
if(!marked[i])
dfs(G,i);
}
}
/**
* 基于深度优先搜索,生成顶点线性序列
* @param G
* @param v
*/
private void dfs (Digraph G, int v) {
//标记顶点已经被搜索过
marked[v] = true;
for (Integer w : G.adj(v)) {
if(!marked[w])
dfs(G,w);
}
//记录到线性序列中
reversePost.push(v);
}
/**
* 获取顶点线性序列
* @return
*/
private Stack<Integer> ReversePost() {
return reversePost;
}
}
到此这篇关于Java数据结构中图的进阶详解的文章就介绍到这了,更多相关Java 图的进阶内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Java数据结构之图(动力节点Java学院整理)
1,摘要: 本文章主要讲解学习如何使用JAVA语言以邻接表的方式实现了数据结构---图(Graph).从数据的表示方法来说,有二种表示图的方式:一种是邻接矩阵,其实是一个二维数组:一种是邻接表,其实是一个顶点表,每个顶点又拥有一个边列表.下图是图的邻接表表示. 从图中可以看出,图的实现需要能够表示顶点表,能够表示边表.邻接表指是的哪部分呢?每个顶点都有一个邻接表,一个指定顶点的邻接表中,起始顶点表示边的起点,其他顶点表示边的终点.这样,就可以用邻接表来实现边的表示了.如顶点V0的邻接表如下: 与
-
Java数据结构之图的领接矩阵详解
目录 1.图的领接矩阵(Adjacency Matrix)存储结构 2.图的接口类 3.图的类型,用枚举类表示 4.图的领接矩阵描述 测试类 结果 1.图的领接矩阵(Adjacency Matrix)存储结构 图的领接矩阵(Adjacency Matrix)存储方式是用两个数组来表示图.一个一位数组存储图中顶点信息,一个二维数组(称为领接矩阵)存储图中的边或弧的信息. 举例 无向图 无向图的领接矩阵的第i行或第i列的非零元素个数正好是第i个顶点的度. 有向图 有向图的领接矩阵的第i行的非零元素个
-
Java数据结构之图的原理与实现
目录 1 图的定义和相关概念 2 图的存储结构 2.1 邻接矩阵 2.2 邻接表 3 图的遍历 3.1 深度优先遍历 3.2 广度优先遍历 4 图的实现 4.1 无向图的邻接表实现 4.2 有向图的邻接表实现 4.3 无向图的邻接矩阵实现 4.4 有向图的邻接矩阵实现 5 总结 首先介绍了图的入门概念,然后介绍了图的邻接矩阵和邻接表两种存储结构.以及深度优先遍历和广度优先遍历的两种遍历方式,最后提供了Java代码的实现. 图,算作一种比较复杂的数据结构,因此建议有一定数据结构基础的人再来学习!
-
Java数据结构最清晰图解二叉树前 中 后序遍历
目录 一,前言 二,树 ①概念 ②树的基础概念 三,二叉树 ①概念 ②两种特殊的二叉树 ③二叉树的性质 四,二叉树遍历 ①二叉树的遍历 ②前序遍历 ③中序遍历 ④后序遍历 五,完整代码 一,前言 二叉树是数据结构中重要的一部分,它的前中后序遍历始终贯穿我们学习二叉树的过程,所以掌握二叉树三种遍历是十分重要的.本篇主要是图解+代码Debug分析,概念的部分讲非常少,重中之重是图解和代码Debug分析,我可以保证你看完此篇博客对于二叉树的前中后序遍历有一个新的认识!!废话不多说,让我们学起来吧!!
-
java数据结构图论霍夫曼树及其编码示例详解
目录 霍夫曼树 一.基本介绍 二.霍夫曼树几个重要概念和举例说明 构成霍夫曼树的步骤 霍夫曼编码 一.基本介绍 二.原理剖析 注意: 霍夫曼编码压缩文件注意事项 霍夫曼树 一.基本介绍 二.霍夫曼树几个重要概念和举例说明 构成霍夫曼树的步骤 举例:以arr = {1 3 6 7 8 13 29} public class HuffmanTree { public static void main(String[] args) { int[] arr = { 13, 7, 8
-
带你了解Java数据结构和算法之无权无向图
目录 1.图的定义 ①.邻接: ②.路径: ③.连通图和非连通图: ④.有向图和无向图: ⑤.有权图和无权图: 2.在程序中表示图 ①.顶点: ②.边: 3.搜索 ①.深度优先搜索(DFS) ②.广度优先搜索(BFS) ③.程序实现 4.最小生成树 5.总结 1.图的定义 我们知道,前面讨论的数据结构都有一个框架,而这个框架是由相应的算法实现的,比如二叉树搜索树,左子树上所有结点的值均小于它的根结点的值,右子树所有结点的值均大于它的根节点的值,类似这种形状使得它容易搜索数据和插入数据,树的边表示
-
Java数据结构中图的进阶详解
目录 有向图 有向图API设计 有向图的实现 拓扑排序 拓扑排序图解 检测有向图中的环 检测有向环的API设计 检测有向环实现 代码 基于深度优先的顶点排序 顶点排序API设计 顶点排序实现 代码: 有向图 有向图的定义及相关术语 定义∶ 有向图是一副具有方向性的图,是由一组顶点和一组有方向的边组成的,每条方向的边都连着 一对有序的顶点. 出度∶ 由某个顶点指出的边的个数称为该顶点的出度. 入度: 指向某个顶点的边的个数称为该顶点的入度. 有向路径︰ 由一系列顶点组成,对于其中的每个顶点都存在一
-
Python数据可视化图实现过程详解
python画分布图代码示例: # encoding=utf-8 import matplotlib.pyplot as plt from pylab import * # 支持中文 mpl.rcParams['font.sans-serif'] = ['SimHei'] # 'mentioned0cluster', names = ['mentioned1cluster','mentioned2cluster', 'mentioned3cluster', 'mentioned4cluster'
-
java 数据结构中栈和队列的实例详解
java 数据结构中栈和队列的实例详解 栈和队列是两种重要的线性数据结构,都是在一个特定的范围的存储单元中的存储数据.与线性表相比,它们的插入和删除操作收到更多的约束和限定,又被称为限定性的线性表结构.栈是先进后出FILO,队列是先进先出FIFO,但是有的数据结构按照一定的条件排队数据的队列,这时候的队列属于特殊队列,不一定按照上面的原则. 实现栈:采用数组和链表两种方法来实现栈 链表方法: package com.cl.content01; /* * 使用链表来实现栈 */ public cl
-
Java 数据结构中二叉树前中后序遍历非递归的具体实现详解
目录 一.前序遍历 1.题目描述 2.输入输出示例 3.解题思路 4.代码实现 二.中序遍历 1.题目描述 2.输入输出示例 3.解题思路 4.代码实现 三.后序遍历 1.题目描述 2.输入输出示例 3.解题思路 4.代码实现 一.前序遍历 1.题目描述 给你二叉树的根节点 root ,返回它节点值的 前序 遍历. 2.输入输出示例 示例 1: 输入:root = [1,null,2,3] 输出:[1,2,3] 示例2: 输入:root = [] 输出:[] 示例 3: 输入:root = [1
-
使用Java构造和解析Json数据的两种方法(详解二)
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,采用完全独立于语言的文本格式,是理想的数据交换格式.同时,JSON是 JavaScript 原生格式,这意味着在 JavaScript 中处理 JSON数据不须要任何特殊的 API 或工具包. 在www.json.org上公布了很多JAVA下的json构造和解析工具,其中org.json和json-lib比较简单,两者使用上差不多但还是有些区别.下面接着介绍用org.json构造和解析Json数据的方法
-
使用Java构造和解析Json数据的两种方法(详解一)
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,采用完全独立于语言的文本格式,是理想的数据交换格式.同时,JSON是 JavaScript 原生格式,这意味着在 JavaScript 中处理 JSON数据不须要任何特殊的 API 或工具包. 在www.json.org上公布了很多JAVA下的json构造和解析工具,其中org.json和json-lib比较简单,两者使用上差不多但还是有些区别.下面首先介绍用json-lib构造和解析Json数据的方法
-
Java编程Post数据请求和接收代码详解
这两天在做http服务端请求操作,客户端post数据到服务端后,服务端通过request.getParameter()进行请求,无法读取到数据,搜索了一下发现是因为设置为text/plain模式才导致读取不到数据 urlConn.setRequestProperty("Content-Type","text/plain; charset=utf-8"); 若设置为以下方式,则通过request.getParameter()可以读取到数据 urlConn.setReq
-
Java设计模式之23种设计模式详解
一.什么是设计模式 设计模式(Design pattern)是一套被反复使用.多数人知晓的.经过分类编目的.代码设计经验的总结.使用设计模式是为了可重用代码.让代码更容易被他人理解.保证代码可靠性. 毫无疑问,设计模式于己于他人于系统都是多赢的,设计模式使代码编制真正工程化,设计模式是软件工程的基石,如同大厦的一块块砖石一样.项目中合理的运用设计模式可以完美的解决很多问题,每种模式在现在中都有相应的原理来与之对应,每一个模式描述了一个在我们周围不断重复发生的问题,以及该问题的核心解决方案,这也是
-
Java Web请求与响应实例详解
Servlet最主要作用就是处理客户端请求并作出回应,为此,针对每次请求,Web容器在调用service()之前都会创建两个对象,分别是HttpServletRequest和HttpServletResponse.其中HttpServletRequest封装HTTP请求消息,HttpServletResponse封装HTTP响应消息.需要注意的是,Web服务器运行过程中,每个Servlet都会只创建一个实例对象,不过每次请求都会调用Servlet实例的service(ServletRequest
-
Java 存储模型和共享对象详解
Java 存储模型和共享对象详解 很多程序员对一个共享变量初始化要注意可见性和安全发布(安全地构建一个对象,并其他线程能正确访问)等问题不是很理解,认为Java是一个屏蔽内存细节的平台,连对象回收都不需要关心,因此谈到可见性和安全发布大多不知所云.其实关键在于对Java存储模型,可见性和安全发布的问题是起源于Java的存储结构. Java存储模型原理 有很多书和文章都讲解过Java存储模型,其中一个图很清晰地说明了其存储结构: 由上图可知, jvm系统中存在一个主内存(Main Memory或J