详解用Python把PDF转为Word方法总结
先讲一下为啥要写这个文章,网上其实很多这种PDF转化的代码和软件。我一直想用Python做,但是网上搜到的代码很多都不能用,很多是2.7版本的代码,再就是PDF需要用到的库在导入的时候,很多的报错,解决起来特别费劲,而且自从2021年初以来,似乎网上很少有关PDF转化的代码出现了。我在研究了很多代码和pdfminer的用法后,总结了几个方法,目前这几种方法可以解决大多数格式的转化,后面我也专门放了提取PDF表格的代码,文末有高效的免费在线工具推荐。
下面这个是我最最推荐的方法 ,简单高效 ,只要是标准PDF文档,里面的图片和表格都可以保留格式

# pip install pdf2docx #安装依赖库 from pdf2docx import Converter pdf_file = r'C:\Users\Administrator\Desktop\新建文件夹\mednine.pdf' docx_file = r'C:\Users\Administrator\Desktop\Python教程\02.docx' # convert pdf to docx cv = Converter(pdf_file) cv.convert(docx_file, start=0, end=None) cv.close()
下面是另外三种常用方法
1 把标准格式的PDF转为Word,测试环境Python3.6.5和3.6.6(注意PDF内容仅仅是文字为主的里面没有图片图表的适用,不适合扫描版PDF,因为那只能用图片识别的方式进行)
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFPage
from io import StringIO
import sys
import string
from docx import Document
def convert_pdf_2_text(path):
rsrcmgr = PDFResourceManager()
retstr = StringIO()
device = TextConverter(rsrcmgr, retstr, codec='utf-8', laparams=LAParams())
interpreter = PDFPageInterpreter(rsrcmgr, device)
with open(path, 'rb') as fp:
for page in PDFPage.get_pages(fp, set()):
interpreter.process_page(page)
#print(retstr.getvalue())
text = retstr.getvalue()
device.close()
retstr.close()
return text
def pdf2txt():
text=convert_pdf_2_text(path)
with open('real.txt','a',encoding='utf-8') as f:
for line in text.split('\n'):
f.write(line+'\n')
def remove_control_characters(content):
mpa = dict.fromkeys(range(32))
return content.translate(mpa)
def save_text_to_word(content, file_path):
doc = Document()
for line in content.split(''):
print(line)
paragraph = doc.add_paragraph()
paragraph.add_run(remove_control_characters(line))
doc.save(file_path)
if __name__ == '__main__':
path = r'C:\Users\mayn\Desktop\程序临时\培训教材.pdf' # 你自己的pdf文件路径及文件名 不适合扫描版 只适合标准PDF文件
text = convert_pdf_2_text(path)
save_text_to_word(text, 'output.doc') #PDF转为word方法
#pdf2txt() #PDF转为txt方法
2专门提取PDF里面的表格,使用pdfplumber适合标准格式的PDF
import pdfplumber
import pandas as pd
import time
from time import ctime
import psutil as ps
#import threading
import gc
pdf = pdfplumber.open(r"C:\Users\Administrator\Desktop\新建文件夹\mednine.pdf")
N=len(pdf.pages)
print('总共有',N,'页')
def pdf2exl(i): # 读取了第i页,第i页是有表格的,
print('********************************************************************************************************************************************************')
print('正在输出第',str(i+1),'页表格')
print('********************************************************************************************************************************************************')
p0 = pdf.pages[i]
try:
table = p0.extract_table()
print(table)
df = pd.DataFrame(table[1:], columns=table[0])
#print(df)
df.to_excel(r"C:\Users\Administrator\Desktop\新建文件夹\Model"+str(i+1)+".xlsx")
#df.info(memory_usage='deep')
except Exception as e:
print('第'+str(i+1)+'页无表格,或者检查是否存在表格')
pass
#print('目前内存占用率是百分之',str(ps.virtual_memory().percent),' 第',str(i+1),'页输出完毕')
print('**********************************************************************************************************************************************************')
print('\n\n\n')
time.sleep(5)
def dojob1(): #此函数 直接循环提取PDF里面各个页面的表格
print('*********************')
for i in range(0,N):
pdf2exl(i)
3也可以提取PDF里面的表格,使用camelot(camelot的安装可能需要点耐心,反正用的人不多)
import camelot
import wand
# 从PDF文件中提取表格
def output(i):
#print(tables)
#for i in range(5):
tables = camelot.read_pdf(r'C:\Users\Administrator\Desktop\新建文件夹\mednine.pdf', pages=str(i), flavor='stream')
print(tables[i])
# 表格数据
print(tables[i].data)
tables[i].to_csv(r'C:\Users\Administrator\Desktop\新建文件夹\002'+str(i)+r'.csv')
def plotpdf():
# 这个是画pdf 结构的函数 现在不能用 不要打开
#print(tables[0])
tables = camelot.read_pdf(r'C:\Users\mayn\Desktop\vcode工作区\11\路基.pdf', pages='200', flavor='stream')
camelot.plot(tables[0], kind='text')
print(tables[0])
plt.show()
# 绘制PDF文档的坐标,定位表格所在的位置
#plt = camelot.plot(tables[0],kind='text')
#plt.show()
#table_df = tables[0].df
#plotpdf()
#i=3
#output(i)
for i in range(0,2):
try:
output(i)
except Exception as e:
print('第'+str(i)+'页没找到表格啊啊啊')
pass
continue
以下是pdfplumber测试效果
源文件如下
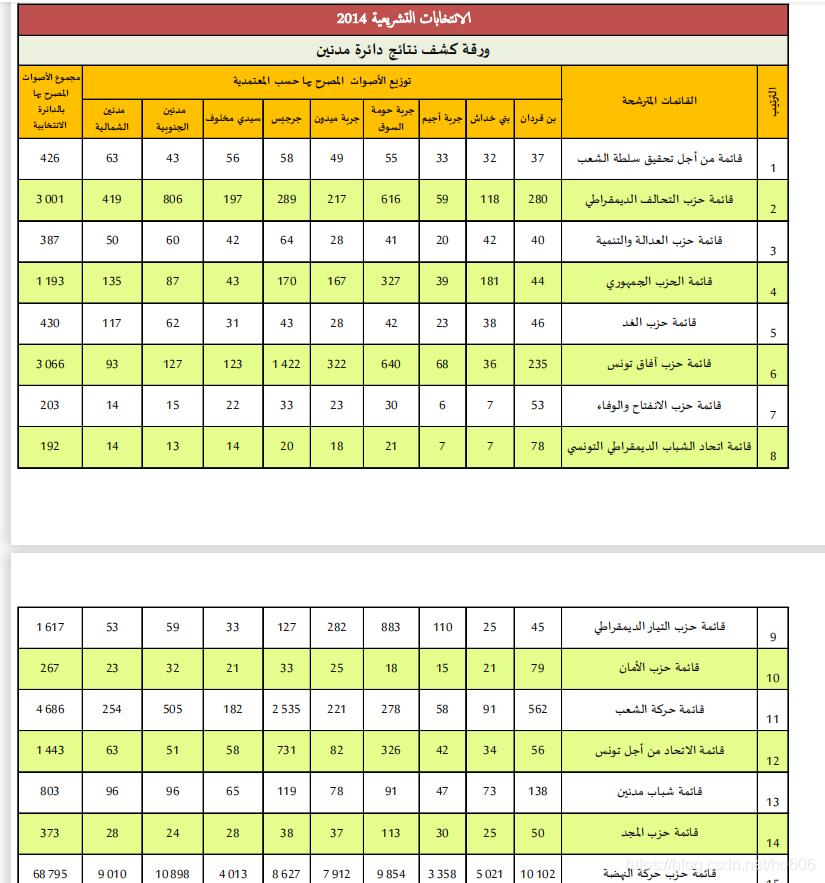
提取结果

最后补充2个免费转换的网站感觉还比较好用,关键是免费
http://pdfdo.com/pdf-to-word.aspx
http://app.xunjiepdf.com/pdf2word/
到此这篇关于详解用Python把PDF转为Word方法总结的文章就介绍到这了,更多相关Python把PDF转为Word内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python实现word 2007文档转换为pdf文件
在开发过程中,会遇到在命令行下将DOC文档(或者是其他Office文档)转换为PDF的要求.比如在项目中如果手册是DOC格式的,在项目发布时希望将其转换为PDF格式,并且保留DOC中的书签,链接等.将该过程整合到构建过程中就要求命令行下进行转换. Michael Suodenjoki展示了使用Office的COM接口进行命令行下的转换.但其导出的PDF文档没有书签.在Office 2007 SP2中,微软加入了该功能,对应的接口是ExportAsFixedFormat.该方法不仅适用于Word,
-
python实现pdf转换成word/txt纯文本文件
本文实例为大家分享了python实现pdf转word/txt,供大家参考,具体内容如下 依赖包:pdfminer3k 可以通过pip安装:也可以到官网下载,解压,进入文件夹,输入命令setup.py install安装软件. 源代码: #!/usr/bin/python # -*- coding: utf-8 -*- import sys import importlib importlib.reload(sys) from pdfminer.pdfparser import PDFParser
-
Python 实现加密过的PDF文件转WORD格式
实现方法简介 许多文件都支持转换为PDF格式,诸如Word,Excel,PowerPoint,Cad以及图片格式.所以pdf从学校到职场,都可以看到pdf文件的身影. 为了保证了文件的安全性,正常情况下无法对pdf的内容进行编辑.但是相应的我们就无法修改pdf的内容,也不便于pdf资料的使用.虽然现在市面上有很多 pdf 转 word 软件,比如 wps,但大多数的软件是要收费的,并且价格不菲.前些天就有人叫我帮她把 pdf 文档转成 word 的文档.因为写尽调报告需要去查看各种信评资料,往往
-

python批量实现Word文件转换为PDF文件
本文为大家分享了python批量转换Word文件为PDF文件的具体方法,供大家参考,具体内容如下 1.目的 通过万能的Python把一个目录下的所有Word文件转换为PDF文件. 2.遍历目录 作者总结了三种遍历目录的方法,分别如下. 2.1.调用glob 遍历指定目录下的所有文件和文件夹,不递归遍历,需要手动完成递归遍历功能. import glob as gb path = gb.glob('d:\\2\\*') for path in path: print path 2.2.调用os.w
-
利用python程序生成word和PDF文档的方法
一.程序导出word文档的方法 将web/html内容导出为world文档,再java中有很多解决方案,比如使用Jacob.Apache POI.Java2Word.iText等各种方式,以及使用freemarker这样的模板引擎这样的方式.php中也有一些相应的方法,但在python中将web/html内容生成world文档的方法是很少的.其中最不好解决的就是如何将使用js代码异步获取填充的数据,图片导出到word文档中. 1. unoconv 功能: 1.支持将本地html文档转换为docx
-
python word转pdf代码实例
原理 使用python win32 库 调用word底层vba,将word转成pdf 安装pywin32 pip install pywin32 python代码 from win32com.client import gencache from win32com.client import constants, gencache def createPdf(wordPath, pdfPath): """ word转pdf :param wordPath: word文件路径
-
详解用Python把PDF转为Word方法总结
先讲一下为啥要写这个文章,网上其实很多这种PDF转化的代码和软件.我一直想用Python做,但是网上搜到的代码很多都不能用,很多是2.7版本的代码,再就是PDF需要用到的库在导入的时候,很多的报错,解决起来特别费劲,而且自从2021年初以来,似乎网上很少有关PDF转化的代码出现了.我在研究了很多代码和pdfminer的用法后,总结了几个方法,目前这几种方法可以解决大多数格式的转化,后面我也专门放了提取PDF表格的代码,文末有高效的免费在线工具推荐. 下面这个是我最最推荐的方法 ,简单高效 ,只要
-
详解在Python程序中自定义异常的方法
通过创建一个新的异常类,程序可以命名它们自己的异常.异常应该是典型的继承自Exception类,通过直接或间接的方式. 以下为与RuntimeError相关的实例,实例中创建了一个类,基类为RuntimeError,用于在异常触发时输出更多的信息. 在try语句块中,用户自定义的异常后执行except块语句,变量 e 是用于创建Networkerror类的实例. class Networkerror(RuntimeError): def __init__(self, arg): self.arg
-
Python实现PDF转Word的方法详解
由于PDF的文件大多都是只读文件,有时候为了满足可以编辑的需要通常可以将PDF文件直接转换成Word文件进行操作. 看了网络上面的python转换PDF文件为Word的相关文章感觉都比较复杂,并且关于一些图表的使用还要进行特殊的处理. 本篇文章主要讲解关于如何使用python是实现将PDF转换成Word的业务过程,这次没有使用GUI应用的操作. 由于可能存在版本冲突的问题,这里将开发过程中需要使用的python非标准库的版本列举出来. python内核版本:3.6.8 PyMuPDF版本:1.1
-
详解让Python性能起飞的15个技巧
目录 前言 如何测量程序的执行时间 1.使用map()进行函数映射 2.使用set()求交集 3.使用sort()或sorted()排序 4.使用collections.Counter()计数 5.使用列表推导 6.使用join()连接字符串 7.使用x,y=y,x交换变量 8.使用while1取代whileTrue 9.使用装饰器缓存 10.减少点运算符(.)的使用 11.使用for循环取代while循环 12.使用Numba.jit加速计算 13.使用Numpy矢量化数组 14.使用in检查
-
基于YUV 数据格式详解及python实现方式
YUV 数据格式概览 YUV 的原理是把亮度与色度分离,使用 Y.U.V 分别表示亮度,以及蓝色通道与亮度的差值和红色通道与亮度的差值.其中 Y 信号分量除了表示亮度 (luma) 信号外,还含有较多的绿色通道量,单纯的 Y 分量可以显示出完整的黑白图像.U.V 分量分别表示蓝 (blue).红 (red) 分量信号,它们只含有色彩 (chrominance/color) 信息,所以 YUV 也称为 YCbCr,C 意思可以理解为 (component 或者 color). 维基百科上的 RGB
-
详解运行Python的神器Jupyter Notebook
Jupyter Notebook Jupyter项目是从Ipython项目中分出去的,在Ipython3.x之前,他们两个是在一起发布的.在Ipython4.x之后,Jupyter作为一个单独的项目进行开发和管理.因为Jupyter不仅仅可以运行Python程序,它还可以执行其他流程编程语言的运行. Jupyter Notebook包括三个部分,第一个部分是一个web应用程序,提供交互式界面,可以在交互式界面中运行相应的代码. 上图是NoteBook的交互界面,我们可以对文档进行编辑,运行等操作
-
Java实现PDF转为Word文档的示例代码
目录 代码编译环境 将 PDF 转换为固定布局的 Doc/Docx 文档 完整代码 将 PDF 转换为流动形态的 Doc/Docx 文档 完整代码 效果图 众所周知,PDF文档除了具有较强稳定性和兼容性外, 还具有较强的安全性,在工作中可以有效避免别人无意中对文档内容进行修改.但与此同时,也妨碍了对文档的正常的修改.这时我们可以将PDF转为Word文档进行修改或再编辑.使用软件将 PDF 文档转换为 Word 文档十分简单,然而要在转换时保持布局甚至字体格式却并不容易.本文将分为以下两部分介绍如
-
详解使用python的logging模块在stdout输出的两种方法
详解使用python的logging模块在stdout输出 前言: 使用python的logging模块时,除了想将日志记录在文件中外,还希望在前台执行python脚本时,可以将日志直接输出到标准输出std.out中. 实现 logging模块可以有两种方法实现该功能: 方案一:basicconfig import sys import logging logging.basicConfig(stream=sys.stdout, level=logging.DEBUG) 方案二:handler
-
详解用Python进行时间序列预测的7种方法
数据准备 数据集(JetRail高铁的乘客数量)下载. 假设要解决一个时序问题:根据过往两年的数据(2012 年 8 月至 2014 年 8月),需要用这些数据预测接下来 7 个月的乘客数量. import pandas as pd import numpy as np import matplotlib.pyplot as plt df = pd.read_csv('train.csv') df.head() df.shape 依照上面的代码,我们获得了 2012-2014 年两年每个小时的乘
-
详解用Python爬虫获取百度企业信用中企业基本信息
一.背景 希望根据企业名称查询其经纬度,所在的省份.城市等信息.直接将企业名称传给百度地图提供的API,得到的经纬度是非常不准确的,因此希望获取企业完整的地理位置,这样传给API后结果会更加准确. 百度企业信用提供了企业基本信息查询的功能.希望通过Python爬虫获取企业基本信息.目前已基本实现了这一需求. 本文最后会提供具体的代码.代码仅供学习参考,希望不要恶意爬取数据! 二.分析 以苏宁为例.输入"江苏苏宁"后,查询结果如下: 经过分析,这里列示的企业信息是用JavaScript动