.NET性能优化之为集合类型设置初始大小的方法
目录
- 前言
- 集合类型
- List源码
- Queue、Stack源码
- HashSet、Dictionary源码
- 总结
- 附录
前言
计划开一个新的系列,来讲一讲在工作中经常用到的性能优化手段、思路和如何发现性能瓶颈,后续有时间的话应该会整理一系列的博文出来。
今天要谈的一个性能优化的Tips是一个老生常谈的点,但是也是很多人没有注意的一个点。在使用集合类型是,你应该设置一个预估的初始大小,那么为什么需要这样做?我们一起来从源码的角度说一说。
集合类型
我们先来聊一聊.NET BCL库中提供的集合类型,对于这个大家肯定都不陌生,比如List、HashSet、Dictionary、Queue、Stack等等,这些都是大家每天都用到,非常熟悉的类型了,那么大家在使用的时候有没有注意过它们有一个特殊构造函数呢?像下面代码块中的那样。
public Stack (int capacity) public List (int capacity) public Queue (int capacity) public HashSet (int capacity) public Dictionary (int capacity)
哎?为什么这些构造函数都有一个叫capacity的参数呢?我们来看看这个参数的注释。初始化类的新实例,该实例为空并且具有指定的初始容量或默认初始容量。
这就很奇怪了不是吗?在我们印象里面只有数组之类的才需要指定固定的长度,为什么这些可以无限添加元素的集合类型也要设置初始容量呢?这其实和这些集合类型的实现方式有关,废话不多说,我们直接看源码。
List源码
首先来看比较简单的List的源码(源码地址在文中都做了超链接,可以直接点击过去,在文末也会附上链接地址)。下面是List的私有变量。
// 用于存在实际的数据,添加进List的元素都由存储在_items数组中 internal T[] _items; // 当前已经存储了多少元素 internal int _size; // 当前的版本号,List每发生一次元素的变更,版本号都会+1 private int _version;
从上面的源码中,我们可以看到虽然List是动态集合,可以无限的往里面添加元素,但是它底层存储数据的还是使用的数组,那么既然使用的数组那它是怎么实现能无限的往里面添加元素的?我们来看看Add方法。
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public void Add(T item)
{
// 版本号+1
_version++;
T[] array = _items;
int size = _size;
// 如果当前已经使用的空间 小于数组大小那么直接存储 size+1
if ((uint)size < (uint)array.Length)
{
_size = size + 1;
array[size] = item;
}
else
{
// 注意!! 如果已经使用的空间等于数组大小,那么走AddWithResize方法
AddWithResize(item);
}
}
从上面的源码可以看到,如果内部_item数组有足够的空间,那么元素直接往里面加就好了,但是如果内部已存放的元素_size等于_item数组大小时,会调用AddWithResize方法,我们来看看里面做了啥。
// AddWithResize方法
[MethodImpl(MethodImplOptions.NoInlining)]
private void AddWithResize(T item)
{
Debug.Assert(_size == _items.Length);
int size = _size;
// 调用Grow方法,并且把size+1,至少需要size+1的空间才能完成Add操作
Grow(size + 1);
_size = size + 1;
_items[size] = item;
}
// Grow方法
private void Grow(int capacity)
{
Debug.Assert(_items.Length < capacity);
// 如果内部数组长度等于0,那么赋值为DefaultCapacity(大小为4),否则就赋值两倍当前长度
int newcapacity = _items.Length == 0 ? DefaultCapacity : 2 * _items.Length;
// 这里做了一个判断,如果newcapacity大于Array.MaxLength(大小是2^31元素)
// 也就是说一个List最大能存储2^32元素
if ((uint)newcapacity > Array.MaxLength) newcapacity = Array.MaxLength;
// 如果newpapacity小于预算需要的容量,也就是说元素数量大于Array.MaxLength
// 后面Capacity会抛出异常
if (newcapacity < capacity) newcapacity = capacity;
// 为Capacity属性设置值
Capacity = newcapacity;
}
// Capacity属性
public int Capacity
{
// 获取容量,直接返回_items的容量
get => _items.Length;
set
{
// 如果value值还小于当前元素个数
// 直接抛异常
if (value < _size)
{
ThrowHelper.ThrowArgumentOutOfRangeException(ExceptionArgument.value, ExceptionResource.ArgumentOutOfRange_SmallCapacity);
}
// 如果value值和当前数组长度不匹配
// 那么走扩容逻辑
if (value != _items.Length)
{
// value大于0新建一个新的数组
// 将原来的数组元素拷贝过去
if (value > 0)
{
T[] newItems = new T[value];
if (_size > 0)
{
Array.Copy(_items, newItems, _size);
}
_items = newItems;
}
// value小于0 那么直接把_items赋值为空数组
// 原本的数组可以被gc回收了
else
{
_items = s_emptyArray;
}
}
}
通过上面的代码我们可以得到两个有意思的结论。
- 一个List元素最大能存放2^31个元素.
- 不设置Capacity的话,默认初始大小为4,后面会以2倍的空间扩容。
List底层是通过数组来存放元素的,如果空间不够会按照2倍大小来扩容,但是它并不能无限制的存放数据。
在元素低于4个的情况下,不设置Capacity不会有任何影响;如果大于4个,那么就会走扩容流程,不仅需要申请新的数组,而且还要发生内存复制和需要GC回收原来的数组。
大家必须知道分配内存、内存复制和GC回收内存的代价是巨大的,下面有个示意图,举了一个从4扩容到8的例子。

上面列举了我们从源码中看到的情况,那么不设置初始化的容量,对性能影响到底有多大呢?所以构建了一个Benchmark,来看看在不同量级下的影响,下面的Benchmark主要是探究两个问题。
- 设置初始值容量和不设置有多大的差别
- 要多少设置多少比较好,还是可以随意设置一些值
public class ListCapacityBench
{
// 宇宙的真理 42
private static readonly Random OriginRandom = new(42);
// 整一个数列模拟常见的集合大小 最大12万
private static readonly int[] Arrays =
{
3, 5, 8, 13, 21, 34, 55, 89, 100, 120, 144, 180, 200, 233,
250, 377, 500, 550, 610, 987, 1000, 1500, 1597, 2000, 2584,
4181, 5000, 6765, 10946, 17711, 28657, 46368, 75025, 121393
};
// 生成一些随机数
private static readonly int[] OriginArrays = Enumerable.Range(0, Arrays.Max()).Select(c => OriginRandom.Next()).ToArray();
// 不设置容量
[Benchmark(Baseline = true)]
public int WithoutCapacity()
{
return InnerTest(null);
}
// 刚好设置需要的容量
[Benchmark]
public int SetArrayLengthCapacity()
{
return InnerTest(null, true);
}
// 设置为8
[Benchmark]
public int Set8Capacity()
{
return InnerTest(8);
}
// 设置为16
[Benchmark]
public int Set16Capacity()
{
return InnerTest(16);
}
// 设置为32
[Benchmark]
public int Set32Capacity()
{
return InnerTest(32);
}
// 设置为64
[Benchmark]
public int Set64Capacity()
{
return InnerTest(64);
}
// 实际的测试方法
// 不使用JIT优化,模拟集合的实际使用场景
[MethodImpl(MethodImplOptions.NoOptimization)]
private static int InnerTest(int? capacity, bool setLength = false)
{
var list = new List<int>();
foreach (var length in Arrays)
{
List<int> innerList;
if (capacity == null)
{
innerList = setLength ? new List<int>(length) : new List<int>();
}
else
{
innerList = new List<int>(capacity.Value);
}
// 真正的测试方法 简单的填充数据
foreach (var item in OriginArrays.AsSpan()[..length])
{
innerList.Add(item);
}
list.Add(innerList.Count);
}
return list.Count;
}
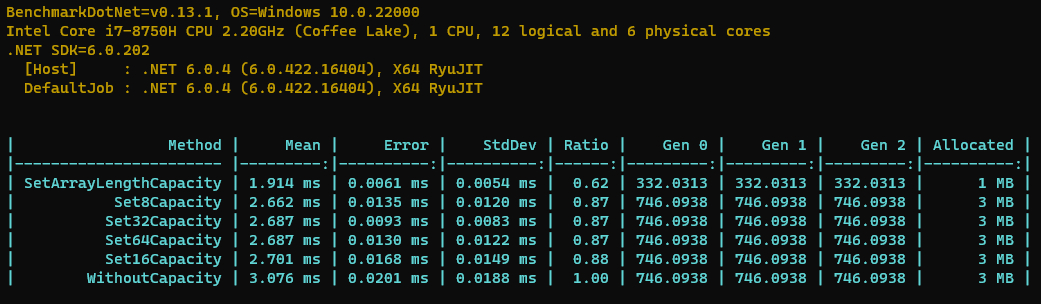
从上面的Benchmark结果可以看出来,设置刚好需要的初始容量最快(比不设置快40%)、GC次数最少(50%+)、分配的内存也最少(节约60%),另外不建议不设置初始大小,它是最慢的。
要是实在不能预估大小,那么可以无脑设置一个8表现稍微好一点点。如果能预估大小,因为它是2倍扩容,可以在2的N次方中找一个接近的。
8 16 32 64 128 512 1024 2048 4096 8192 ......
Queue、Stack源码
接下来看看Queue和Stack,看看它的扩容逻辑是怎么样的。
private void Grow(int capacity)
{
Debug.Assert(_array.Length < capacity);
const int GrowFactor = 2;
const int MinimumGrow = 4;
int newcapacity = GrowFactor * _array.Length;
if ((uint)newcapacity > Array.MaxLength) newcapacity = Array.MaxLength;
newcapacity = Math.Max(newcapacity, _array.Length + MinimumGrow);
if (newcapacity < capacity) newcapacity = capacity;
SetCapacity(newcapacity);
}
基本一样,也是2倍扩容,所以按照我们上面的规则就好了。
HashSet、Dictionary源码
HashSet和Dictionary的逻辑实现类似,只是一个Key就是Value,另外一个是Key对应Value。不过它们的扩容方式有所不同,具体可以看我之前的博客,来看看扩容的源码,这里以HashSet为例。
private void Resize() => Resize(HashHelpers.ExpandPrime(_count), forceNewHashCodes: false);
private void Resize(int newSize, bool forceNewHashCodes)
{
// Value types never rehash
Debug.Assert(!forceNewHashCodes || !typeof(T).IsValueType);
Debug.Assert(_entries != null, "_entries should be non-null");
Debug.Assert(newSize >= _entries.Length);
var entries = new Entry[newSize];
int count = _count;
Array.Copy(_entries, entries, count);
if (!typeof(T).IsValueType && forceNewHashCodes)
{
Debug.Assert(_comparer is NonRandomizedStringEqualityComparer);
_comparer = (IEqualityComparer<T>)((NonRandomizedStringEqualityComparer)_comparer).GetRandomizedEqualityComparer();
for (int i = 0; i < count; i++)
{
ref Entry entry = ref entries[i];
if (entry.Next >= -1)
{
entry.HashCode = entry.Value != null ? _comparer!.GetHashCode(entry.Value) : 0;
}
}
if (ReferenceEquals(_comparer, EqualityComparer<T>.Default))
{
_comparer = null;
}
}
// Assign member variables after both arrays allocated to guard against corruption from OOM if second fails
_buckets = new int[newSize];
#if TARGET_64BIT
_fastModMultiplier = HashHelpers.GetFastModMultiplier((uint)newSize);
#endif
for (int i = 0; i < count; i++)
{
ref Entry entry = ref entries[i];
if (entry.Next >= -1)
{
ref int bucket = ref GetBucketRef(entry.HashCode);
entry.Next = bucket - 1; // Value in _buckets is 1-based
bucket = i + 1;
}
}
_entries = entries;
}
从上面的源码中可以看到Resize的步骤如下所示。
- 通过
HashHelpers.ExpandPrime获取新的Size - 创建新的数组,使用数组拷贝将原数组元素拷贝过去
- 对所有元素进行重新Hash,重建引用
从这里大家就可以看出来,如果不指定初始大小的话,HashSet和Dictionary这样的数据结构扩容的成本更高,因为还需要ReHash这样的操作。
那么HashHelpers.ExpandPrime是一个什么样的方法呢?究竟每次会扩容多少空间呢?我们来看HashHelpers源码。
public const uint HashCollisionThreshold = 100;
// 这是比Array.MaxLength小最大的素数
public const int MaxPrimeArrayLength = 0x7FFFFFC3;
public const int HashPrime = 101;
public static int ExpandPrime(int oldSize)
{
// 新的size等于旧size的两倍
int nwSize = 2 * oldSize;
// 和List一样,如果大于了指定最大值,那么直接返回最大值
if ((uint)newSize > MaxPrimeArrayLength && MaxPrimeArrayLength > oldSize)
{
Debug.Assert(MaxPrimeArrayLength == GetPrime(MaxPrimeArrayLength), "Invalid MaxPrimeArrayLength");
return MaxPrimeArrayLength;
}
// 获取大于newSize的第一素数
return GetPrime(newSize);
}
public static int GetPrime(int min)
{
if (min < 0)
throw new ArgumentException(SR.Arg_HTCapacityOverflow);
// 获取大于min的第一个素数
foreach (int prime in s_primes)
{
if (prime >= min)
return prime;
}
// 如果素数列表里面没有 那么计算
for (int i = (min | 1); i < int.MaxValue; i += 2)
{
if (IsPrime(i) && ((i - 1) % HashPrime != 0))
return i;
}
return min;
}
// 用于扩容的素数列表
private static readonly int[] s_primes =
{
3, 7, 11, 17, 23, 29, 37, 47, 59, 71, 89, 107, 131, 163, 197, 239, 293, 353, 431, 521, 631, 761, 919,
1103, 1327, 1597, 1931, 2333, 2801, 3371, 4049, 4861, 5839, 7013, 8419, 10103, 12143, 14591,
17519, 21023, 25229, 30293, 36353, 43627, 52361, 62851, 75431, 90523, 108631, 130363, 156437,
187751, 225307, 270371, 324449, 389357, 467237, 560689, 672827, 807403, 968897, 1162687, 1395263,
1674319, 2009191, 2411033, 2893249, 3471899, 4166287, 4999559, 5999471, 7199369
};
// 当容量大于7199369时,需要计算素数
public static bool IsPrime(int candidate)
{
if ((candidate & 1) != 0)
{
int limit = (int)Math.Sqrt(candidate);
for (int divisor = 3; divisor <= limit; divisor += 2)
{
if ((candidate % divisor) == 0)
return false;
}
return true;
}
return candidate == 2;
}
从上面的代码我们就可以得出HashSet和Dictionary每次扩容后的大小就是大于二倍Size的第一个素数,和List直接扩容2倍还是有差别的。
至于为什么要使用素数来作为扩容的大小,简单来说是使用素数能让数据在Hash以后更均匀的分布在各个桶中(素数没有其它约数),这不在本文的讨论范围,具体可以戳链接1、链接2、链接3了解更多。
总结
从性能的角度来说,强烈建议大家在使用集合类型时指定初始容量,总结了下面的几个点。
从性能的角度来说,强烈建议大家在使用集合类型时指定初始容量,总结了下面的几个点。
- 如果你知道集合将要存放的元素个数,那么就直接设置那个大小,那样性能最高.
- 比如那种分页接口,页大小只可能是50、100
- 或者做Map操作,前后的元素数量是一致的,那就可以直接设置
- 如果你不知道,那么可以预估一下个数,在2的次方中找一个合适的就可以了.
可以尽量的预估多一点点,能避免Resize操作就避免
附录
浅析 C# Dictionary:https://www.cnblogs.com/InCerry/p/10325290.html
到此这篇关于.NET性能优化之为集合类型设置初始大小的方法的文章就介绍到这了,更多相关.NET性能优化集合类型设置初始大小内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

asp.net性能优化之使用Redis缓存(入门)
1:使用Redis缓存的优化思路 redis的使用场景很多,仅说下本人所用的一个场景: 1.1对于大量的数据读取,为了缓解数据库的压力将一些不经常变化的而又读取频繁的数据存入redis缓存 大致思路如下:执行一个查询 1.2首先判断缓存中是否存在,如存在直接从Redis缓存中获取. 1.3如果Redis缓存中不存在,实时读取数据库数据,同时写入缓存(并设定缓存失效的时间). 1.4缺点,如果直接修改了数据库的数据而又没有更新缓存,在缓存失效的时间内将导致读取的Redis缓存是错误的数据. 2:R
-
ASP.NET比较常用的26个性能优化技巧
本篇文章主要介绍了"ASP.NET中常用的26个优化性能方法",主要涉及到ASP.NET中常用的26个优化性能方法方面的内容,对于ASP.NET中常用的26个优化性能方法感兴趣的同学可以参考一下. 现在很多客户也慢慢开始注重网站的性能了,同时有很多运营网站的公司也不像以前那样特别在意网站是否非常漂亮,而把更多的精力放在了网站性能优化上面,提供更快更稳定的浏览速度,在这个基础上面进行网站功能上的扩充和完善,那么在asp.net中如何优化性能呢? 1. 数据库访问性能优化 数据库的连接和关
-
.NET使用Collections.Pooled提升性能优化的方法
目录 简介 Collections.Pooled 如何使用 性能对比 PooledList<T> PooledDictionary<TKey, TValue> PooledSet<T> PooledStack<T> PooledQueue<T> 未手动释放场景 原理解析 总结 简介 性能优化就是如何在保证处理相同数量的请求情况下占用更少的资源,而这个资源一般就是CPU或者内存,当然还有操作系统IO句柄.网络流量.磁盘占用等等.但是绝大多数时候,我
-
.NET性能优化之为结构体数组使用StructLinq的问题解析
目录 前言 Linq是值传递 使用StructLinq 引入StructLinq 简单使用 性能 在上文场景中使用 总结 前言 本系列的主要目的是告诉大家在遇到性能问题时,有哪些方案可以去优化:并不是要求大家一开始就使用这些方案来提升性能.在之前几篇文章中,有很多网友就有一些非此即彼的观念,在实际中,处处都是开发效率和性能之间取舍的艺术.<计算机编程艺术>一书中提到过早优化是万恶之源,在进行性能优化时,你必须要问自己几个问题,看需不要进行性能优化. 优化的成本高么? 如果立刻开始优化会带来什么
-
.NET使用结构体替代类提升性能优化的技巧
目录 前言 现实的案例 内存占用 计算速度 总结 附录 前言 我们知道在C#和Java明显的一个区别就是C#可以自定义值类型,也就是今天的主角struct,我们有了更加方便的class为什么微软还加入了struct呢?这其实就是今天要谈到的一个优化性能的Tips使用结构体替代类.那么使用结构体替代类有什么好处呢?在什么样的场景需要使用结构体来替代类呢?今天的文章为大家一一解答.注意:本文全部都以x64位平台为例 现实的案例 举一个现实系统的例子,大家都知道机票购票的流程,开始选择起抵城市和机场(
-
.NET性能优化之为集合类型设置初始大小的方法
目录 前言 集合类型 List源码 Queue.Stack源码 HashSet.Dictionary源码 总结 附录 前言 计划开一个新的系列,来讲一讲在工作中经常用到的性能优化手段.思路和如何发现性能瓶颈,后续有时间的话应该会整理一系列的博文出来.今天要谈的一个性能优化的Tips是一个老生常谈的点,但是也是很多人没有注意的一个点.在使用集合类型是,你应该设置一个预估的初始大小,那么为什么需要这样做?我们一起来从源码的角度说一说. 集合类型 我们先来聊一聊.NET BCL库中提供的集合类型,对于
-
php使用 readfile() 函数设置文件大小大小的方法
使用PHP ZipArchive生成的压缩包,小的压缩包都能下载,今天遇到个150M以上的就报404错误,第一想到的就是文件大小超出了PHP默认设置,修改方法有两个: php.ini:memory_limit memory_limit是设置内存限制的,如果使用readfile()读取文件就会和这个有关,直接修改这个值保存后重启php-fpm即可. memory_limit = 128M 最后记得:service php-fpm restart ini_set PHP ini_set用来设置php
-
Android TextView 设置字体大小的方法
废话不多说了,直接给大家贴代码了,具体代码如下所示: package com.example.yanlei.yl4; import android.graphics.Color; import android.os.Bundle; import android.support.v7.app.AppCompatActivity; import android.text.Spannable; import android.text.style.AbsoluteSizeSpan; import and
-
微信小程序动态设置图片大小的方法
我们都知道微信小程序的组件image是用来显示图片的,它有一下几个属性: 1.src 图片资源地址 2.mode 图片裁剪.缩放的模式 3.binderror 当错误发生时,发布到 AppService 的事件名,事件对象event.detail = {errMsg: 'something wrong'} 4.bindload 当图片载入完毕时,发布到 AppService 的事件名,事件对象event.detail = {height
-
浅析Linux root设置初始值的方法
ubuntu默认不允许使用root登录,因此初始root账户是不能使用的,需要在普通账户下利用sudo权限修改root密码. 在终端输入sudo passwd root,按回车,然后系统会提示你输入普通用户的密码(终端输入的密码都是不显示的). 输入后,按回车,然后重复输入两次新的root密码即可激活root用户. 首先登录普通用户,输入下面命令>>> ~$ sudo passwd root [sudo] passwd for you:******(输入用户密码,输入密码不显示) Ent
-
IntelliJ IDEA设置显示内存指示器和设置内存大小的方法
一.设置显示内存指示器 idea默认情况下,是不显示当前内存使用情况的,可以通过设置让其显示,方法如下: 打开Preferences-->Appearance & Behavior-->Appearance,右侧勾选Window Options下面的Show memory indicator即可.如下图: [外链图片转存失败(img-uHIFk4f0-1568595892191)(images/04_01.png)] 设置好之后,在idea右下角会出现展示内存信息指示器,显示当前使用的
-
.NET性能优化ValueStringBuilder拼接字符串使用实例
目录 前言 ValueStringBuilder 源码解析 适用场景 需要注意的场景 总结 前言 这一次要和大家分享的一个Tips是在字符串拼接场景使用的,我们经常会遇到有很多短小的字符串需要拼接的场景,在这种场景下及其的不推荐使用String.Concat也就是使用+=运算符.目前来说官方最推荐的方案就是使用StringBuilder来构建这些字符串,那么有什么更快内存占用更低的方式吗?那就是今天要和大家介绍的ValueStringBuilder. ValueStringBuilder Val
-
Java代码性能优化的35个方法总结
代码优化,一个很重要的课题.可能有些人觉得没用,一些细小的地方有什么好修改的,改与不改对于代码的运行效率有什么影响呢?这个问题我是这么考虑的,就像大海里面的鲸鱼一样,它吃一条小虾米有用吗?没用,但是,吃的小虾米一多之后,鲸鱼就被喂饱了.代码优化也是一样,如果项目着眼于尽快无BUG上线,那么此时可以抓大放小,代码的细节可以不精打细磨:但是如果有足够的时间开发.维护代码,这时候就必须考虑每个可以优化的细节了,一个一个细小的优化点累积起来,对于代码的运行效率绝对是有提升的. 代码优化细节如下: 1.尽
-
Java中性能优化的35种方法汇总
前言 对程序员们来说,代码优化是一个很重要的课题.可能有些人觉得没用,一些细小的地方有什么好修改的,改与不改对于代码的运行效率有什么影响呢?这个问题我是这么考虑的,就像大海里面的鲸鱼一样,它吃一条小虾米有用吗?没用,但是,吃的小虾米一多之后,鲸鱼就被喂饱了.代码优化也是一样,如果项目着眼于尽快无BUG上线,那么此时可以抓大放小,代码的细节可以不精打细磨:但是如果有足够的时间开发.维护代码,这时候就必须考虑每个可以优化的细节了,一个一个细小的优化点累积起来,对于代码的运行效率绝对是有提升的.