python3 requests库实现多图片爬取教程
最近对爬虫比较感兴趣,所以就学了一下,看人家都在网上爬取那么多美女图片养眼,我也迫不及待的试了一下,不多说,切入正题。
其实爬取图片和你下载图片是一个样子的,都是操作链接,也就是url,所以当我们确定要爬取的东西后就要开始寻找url了,所以先打开百度图片搜一下
然后使用浏览器F12进入开发者模式,或者右键检查元素
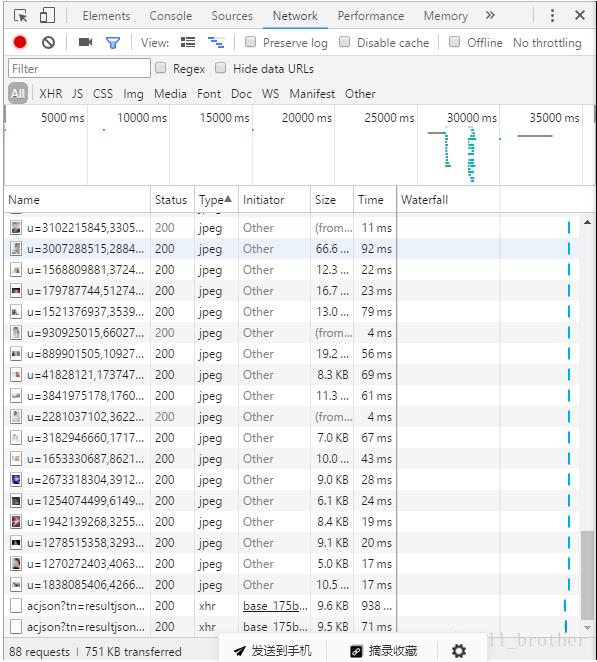
注意看xhr,点开观察有什么不一样的(如果没有xhr就在网页下滑)
第一个是这样的
第二个是这样的
注意看,pn是不是是30的倍数,而此时网页图片的数量也在增多,发现了这个,进url看一下,首先看原网页源码
view-source:http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&hs=0&xthttps=111121&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=%E7%BE%8E%E5%A5%B3&oq=%E7%BE%8E%E5%A5%B3&rsp=-1
再看看两个Requests URL的页面,发现都是这样的
不用管他,找我们要的信息,ObjURL,"ObjURL":"http:\/\/image.tianjimedia.com\/uploadimages\/2015\/131\/34\/545szi3x5s84_680x500.jpg"
就是这个,好,现在东西都找到在哪了,写程序咯
import re
import requests
import os
name=input('输入文件夹名称:')
robot='C:/Users/lenovo/Desktop/'+name+'/'
kv={'user-agent':'mozilla/5.0'}
#获取url对应的源码页面
def getHTMLText(url):
try:
r=requests.get(url,timeout=30,headers=kv)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ''
#解析url源码页面
def parserHTML(html):
#正则表达式为获取ObjURL
pattern=r'"ObjURL":"(.*?)"'
reg=re.compile(pattern)
urls=re.findall(reg,html)
return urls
#下载图片
def download(List):
for url in List:
try:
path=robot+url.split('/')[-1]
url=url.replace('\\','')
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
if not os.path.exists(robot):
os.makedirs(robot)
if not os.path.exists(path):
with open(path,'wb') as f:
f.write(r.content)
f.close()
print(path+' 文件保存成功')
else:
print('文件已经存在')
except:
continue
#通过Requests URL请求到更多的url源码页面
def getmoreurl(num,word):
ur=[]
url=r'http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord={word}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word={word}&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&cg=girl&pn={pn}&rn=30'
for x in range(1,num+1):
#word为搜索关键词,num为想获取的页面数量
u=url.format(word=word,pn=30*x)
ur.append(u)
return ur
def main():
n=int(input('输入想下载多少张图片(n*30):'))
word=input('输入想下载的图片:')
#初始页面url
url='http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1499773676062_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word={word}'.format(word=word)
html=getHTMLText(url)
urls=parserHTML(html)
download(urls)
#下面操作获取的更多页面图片
url1=getmoreurl(n,word)
for i in range(n):
html1=getHTMLText(url1[i])
urls1=parserHTML(html1)
download(urls1)
main()
然后试一试效果

我知道你们会原谅我的
以上这篇python3 requests库实现多图片爬取教程就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

简单实现Python爬取网络图片
本文实例为大家分享了Python爬取网络图片的具体代码,供大家参考,具体内容如下 代码: import urllib import urllib.request import re #打开网页,下载器 def open_html ( url): require=urllib.request.Request(url) reponse=urllib.request.urlopen(require) html=reponse.read() return html #下载图片 def load_imag
-
Python3.6安装及引入Requests库的实现方法
本博客可能没有那么规范,环境之类的配置.只是让你直接开始编程写python. 至于各种配置网络上有多种方法. 本文仅代表我的观点的一种方法. 电脑环境:win10 64位 第一步:下载python. 网址:https://www.python.org/downloads/windows/ 点击并打开,我下载的是最新Python3.6.0版本. 打开后界面如下,根据你的电脑和你的条件选择你需要的版本. x86适合32位操作系统:x86-64适合64位操作系统. web-based installe
-
Python3直接爬取图片URL并保存示例
有时候我们会需要从网络上爬取一些图片,来满足我们形形色色直至不可描述的需求. 一个典型的简单爬虫项目步骤包括两步:获取网页地址和提取保存数据. 这里是一个简单的从图片url收集图片的例子,可以成为一个小小的开始. 获取地址 这些图片的URL可能是连续变化的,如从001递增到099,这种情况可以在程序中将共同的前面部分截取,再在最后递增并字符串化后循环即可. 抑或是它们的URL都保存在某个文件中,这时可以读取到列表中: def getUrls(path): urls = [] with open(
-
Python3网络爬虫中的requests高级用法详解
本节我们再来了解下 Requests 的一些高级用法,如文件上传,代理设置,Cookies 设置等等. 1. 文件上传 我们知道 Reqeuests 可以模拟提交一些数据,假如有的网站需要我们上传文件,我们同样可以利用它来上传,实现非常简单,实例如下: import requests files = {'file': open('favicon.ico', 'rb')} r = requests.post('http://httpbin.org/post', files=files) print
-
Python爬虫爬取一个网页上的图片地址实例代码
本文实例主要是实现爬取一个网页上的图片地址,具体如下. 读取一个网页的源代码: import urllib.request def getHtml(url): html=urllib.request.urlopen(url).read() return html print(getHtml(http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E5%A3%81%E7%BA%B8&ct=201326592&am
-
Python requests库用法实例详解
本文实例讲述了Python requests库用法.分享给大家供大家参考,具体如下: requests是Python中一个第三方库,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库.它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTTP 测试需求.接下来将记录一下requests的使用: 安装 要使用requests库必须先要安装: pip install requests 创建请求 通过requests库发出一个请求非常简单,首先我们先导入
-
python3 requests库实现多图片爬取教程
最近对爬虫比较感兴趣,所以就学了一下,看人家都在网上爬取那么多美女图片养眼,我也迫不及待的试了一下,不多说,切入正题. 其实爬取图片和你下载图片是一个样子的,都是操作链接,也就是url,所以当我们确定要爬取的东西后就要开始寻找url了,所以先打开百度图片搜一下 然后使用浏览器F12进入开发者模式,或者右键检查元素 注意看xhr,点开观察有什么不一样的(如果没有xhr就在网页下滑) 第一个是这样的 第二个是这样的 注意看,pn是不是是30的倍数,而此时网页图片的数量也在增多,发现了这个,进url看
-
python制作微博图片爬取工具
有小半个月没有发博客了,因为一直在研究python的GUI,买了一本书学习了一些基础,用我所学做了我的第一款GUI--微博图片爬取工具.本软件源代码已经放在了博客中,另外软件已经打包好上传到网盘中以供下载学习. 一.准备工作 本次要用到以下依赖库:re json os random tkinter threading requests PIL 其中后两个需要安装后使用 二.预览 1.启动 2.运行中 3.结果 这里只将拿一张图片作为展示. 三.设计流程 设计流程分为总体设计和详细设计,这里我会使
-
Python实现微博动态图片爬取详解
由于微博的网页端有反爬虫,需要登录,所以我们换个思路,曲线救国. 我们找到微博在浏览器上面用于手机端的调试的APL,如何找到呢? 我这边直接附上微博的手机端的地址:https://m.weibo.cn/ 1.模拟搜索用户 搜索一个用户获取到的api: https://m.weibo.cn/api/container/getIndex?containerid=100103type=1&q=半半子&page_type=searchall 1.1 对api内参数进行处理 containerid=
-
如何利用Node.js做简单的图片爬取
目录 介绍 安装引入 创建实例 元素捕获 下载图片 结语 介绍 爬虫的主要目的是收集互联网上公开的一些特定数据.利用这些数据我们可以能进行分析一些趋势对比,或者训练模型做深度学习等等.本期我们就将介绍一个专门用于网络抓取的 node.js 包—— node-crawler ,并且我们将用它完成一个简单的爬虫案例来爬取网页上图片并下载到本地. node-crawler 是一个轻量级的 node.js 爬虫工具,兼顾了高效与便利性,支持分布式爬虫系统,支持硬编码,支持http前级代理.而且,它完全是
-
Python3爬虫之urllib携带cookie爬取网页的方法
如下所示: import urllib.request import urllib.parse url = 'https://weibo.cn/5273088553/info' #正常的方式进行访问 # headers = { # 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36' # } # 携带
-
Python使用requests xpath 并开启多线程爬取西刺代理ip实例
我就废话不多说啦,大家还是直接看代码吧! import requests,random from lxml import etree import threading import time angents = [ "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", "Mozilla/4.0 (compati
-
Python3爬虫使用Fidder实现APP爬取示例
之前爬取都是网页上的数据,今天要来说一下怎么借助Fidder来爬取手机APP上的数据. 一.环境配置 1.Fidder的安装和配置 没有安装Fidder软件的可以进入 这个网址 下载,然后就是傻瓜式的安装,安装步骤很简单.在安装完成后,打开软件,进行如下设置: 这里使用默认的8888端口就好了,如果要修改的话,要避免和其他端口冲突. 2.手机的配置 首先打开cmd,输入ipconfig查看IP地址,记录下这个IP地址: 想要使用FIdder进行手机抓包,要让手机和PC处在同一个内网中,方法就是连
-
Python使用xpath实现图片爬取
高性能异步爬虫 目的:在爬虫中使用异步实现高性能的数据爬取操作 异步爬虫的方式: - 多线程.多进程(不建议): 好处:可以为相关阻塞的操作单独开启多线程或进程,阻塞操作就可以异步执行; 弊端:无法无限制的开启多线程或多进程. - 线程池.进程池(适当的使用): 好处:我们可以降低系统对进程或线程创建和销毁的一个频率,从而很好的降低系统的开销: 弊端:池中线程或进程的数据是有上限的. 代码如下 # _*_ coding:utf-8 _*_ """ @FileName :6.4
-
python采用requests库模拟登录和抓取数据的简单示例
如果你还在为python的各种urllib和urlibs,cookielib 头疼,或者还还在为python模拟登录和抓取数据而抓狂,那么来看看我们推荐的requests,python采集数据模拟登录必备利器! 这也是python推荐的HTTP客户端库: 本文就以一个模拟登录的例子来加以说明,至于采集大家就请自行发挥吧. 代码很简单,主要是展现python的requests库的简单至极,代码如下: s = requests.session() data = {'user':'用户名','pass
-
python3 requests库文件上传与下载实现详解
在接口测试学习过程中,遇到了利用requests库进行文件下载和上传的问题.同样,在真正的测试过程中,我们不可避免的会遇到上传和下载的测试. 文件上传: url = ztx.host+'upload/uploadFile?CSRFToken='+self.getCSRFToken()#上传文件的接口地址 header = { 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko', '