Python文件名匹配与文件复制的实现
文件名的匹配,实际上就是相当于获取文件名(不含后缀),然后利用获取到的文件名到另外一个文件夹中去寻找对应的文件,然后将文件取出,放置到指定文件夹下.概括的来说,分三个步骤:一是取出遍历目录A,得到各个文件文件名;二是利用该文件名,与指定路径B拼接,并加上后缀,产生目标文件名;三是根据拼接产生的目标文件名,将相应文件复制到指定目录C.
好,那么我们开始写代码吧~~~
step1:获取指定目录A下面的所有文件名.不包含文件后缀.主要基于以下思想:
def GetFileNameAndExt(filename): import os (filepath,tempfilename) = os.path.split(filename); (shotname,extension) = os.path.splitext(tempfilename); return shotname,extension
测试代码
print(GetFileNameAndExt('c:\jb51\index.html'))
返回结果:
('index', '.html')
实际代码如下
#coding=utf-8 import os import os.path def GetFileNameAndExt(filename): (filepath,tempfilename) = os.path.split(filename); (shotname,extension) = os.path.splitext(tempfilename); return shotname,extension source_dir='/home/nvidia/xmlReader/circle' label_dir='/home/nvidia/xmlReader/label' annotion_dir='/home/nvidia/xmlReader/annocation' ##1.将指定A目录下的文件名取出,并将文件名文本和文件后缀拆分出来 img=os.listdir(source_dir) #得到文件夹下所有文件名称 s=[] for fileNum in img: #遍历文件夹 if not os.path.isdir(fileNum): #判断是否是文件夹,不是文件夹才打开 print fileNum #打印出文件名 imgname= os.path.join(source_dir,fileNum) print imgname #打印出文件路径 (imgpath,tempimgname) = os.path.split(imgname); #将路径与文件名分开 (shotname,extension) = os.path.splitext(tempimgname); #将文件名文本与文件后缀分开 print shotname,extension print '~~~~'
step2:二是利用该文件名,与指定路径B拼接,并加上后缀,产生目标文件名
##2.将取出来的文件名文本与特定后缀拼接,在于路径拼接,得到B目录下的文件 xmlname=os.path.join(label_dir,shotname,'.xml') print xmlname
但是得到的输出是有分隔符的.

如何去掉分隔符呢?或者说如何拼接文件名文本和后缀呢? 基于以下Python基础
'%d.txt'%fname
这样基本上可以表示比如120.txt这样的字符串了。
代码如下:
##2.将取出来的文件名文本与特定后缀拼接,在于路径拼接,得到B目录下的文件 tempxmlname='%s.xml'%shotname xmlname=os.path.join(label_dir,tempxmlname) print xmlname
我们来看看输出:
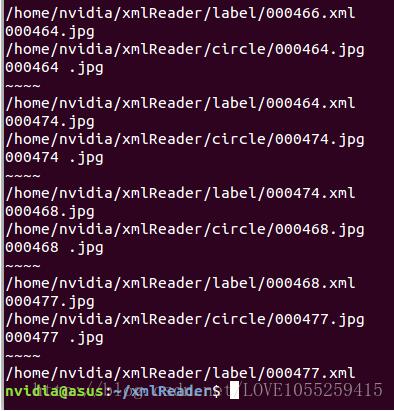
大功告成,现在我们得到了想要的数据格式,开始到这个指定的路径去寻找文件匹配文件名了~~~~
step3:定位到目标文件名,将其复制到指定目录下,保持文件名不变.(Python文件复制)
##3.根据得到的xml文件名,将对应文件拷贝到指定目录C
shutil.copy(xmlname,annotion_dir)
这样,与图片相关的标注文件就全部拷贝过来了~~~

最后,我们来看看我们最终的代码:
#coding=utf-8 import os import os.path import shutil #Python文件复制相应模块 def GetFileNameAndExt(filename): (filepath,tempfilename) = os.path.split(filename); (shotname,extension) = os.path.splitext(tempfilename); return shotname,extension source_dir='/home/nvidia/xmlReader/circle' label_dir='/home/nvidia/xmlReader/label' annotion_dir='/home/nvidia/xmlReader/annocation' ##1.将指定A目录下的文件名取出,并将文件名文本和文件后缀拆分出来 img=os.listdir(source_dir) #得到文件夹下所有文件名称 s=[] for fileNum in img: #遍历文件夹 if not os.path.isdir(fileNum): #判断是否是文件夹,不是文件夹才打开 print fileNum #打印出文件名 imgname= os.path.join(source_dir,fileNum) print imgname #打印出文件路径 (imgpath,tempimgname) = os.path.split(imgname); #将路径与文件名分开 (shotname,extension) = os.path.splitext(tempimgname); #将文件名文本与文件后缀分开 print shotname,extension print '~~~~' ##2.将取出来的文件名文本与特定后缀拼接,再与路径B拼接,得到B目录下的文件 tempxmlname='%s.xml'%shotname xmlname=os.path.join(label_dir,tempxmlname) print xmlname ##3.根据得到的xml文件名,将对应文件拷贝到指定目录C shutil.copy(xmlname,annotion_dir)
至此,大功告成!

以上这篇Python文件名匹配与文件复制的实现就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python: glob匹配文件的操作
glob模块实例详解 glob的应用场景是要寻找一系列(符合特定规则)文件名. glob模块是最简单的模块之一,内容非常少.用它可以查找符合特定规则的文件路径名.查找文件只用到三个匹配符:"*", "?", "[]". "*"匹配0个或多个字符: "?"匹配单个字符: "[ ]"匹配指定范围内的字符,如:[0-9]匹配数字. 假设以下例子目录是这样的. dir dir/file.txt
-
如何利用python正则表达式匹配版本信息
问题描述: 用正则表达式提取文本中的版本号信息,比如说:10.1.1 9.5 10.10.11 并实现在文本中(.txt)读入,写出到文本(.txt) 首先构造正则表达式: pattern=Vpat="I.(I.)*I" 构造正则表达式:r'\d+\.(?:\d+\.)*\d+' import re pattern = r'\d+\.(?:\d+\.)*\d+' f=open("F:\\xxxxxx\\banners.txt","r") data
-
Python通过fnmatch模块实现文件名匹配
fnmatch 模块主要用于文件名称的匹配,其能力比简单的字符串匹配更强大,但比使用正则表达式相比稍弱..如果在数据处理操作中,只需要使用简单的通配符就能完成文件名的匹配,则使用 fnmatch 模块是不错的选择. fnmatch 模块中,常用的函数及其功能如表 1 所示. Python fnmatch模块常用函数及功能 函数名 功能 fnmatch.filter(names, pattern) 对 names 列表进行过滤,返回 names 列表中匹配 pattern 的文件名组成的子集合.
-
用python实现前向分词最大匹配算法的示例代码
理论介绍 分词是自然语言处理的一个基本工作,中文分词和英文不同,字词之间没有空格.中文分词是文本挖掘的基础,对于输入的一段中文,成功的进行中文分词,可以达到电脑自动识别语句含义的效果.中文分词技术属于自然语言处理技术范畴,对于一句话,人可以通过自己的知识来明白哪些是词,哪些不是词,但如何让计算机也能理解?其处理过程就是分词算法. 可以将中文分词方法简单归纳为: 1.基于词表的分词方法 2.基于统计的分词方法 3.基于序列标记的分词方法 其中,基于词表的分词方法最为简单,根据起始匹配位置不同可以分
-

python使用正则表达式匹配txt特定字符串(有换行)
在原txt文件中,我们需要匹配出的字符串为:休闲服务(中间参杂着换行) 直接复制到notebook里进行处理 ①发现需要拿出的字符串都在证卷研究报告前,第一步就把证券报告前面的所有内容全部提出来(包括换行) ②发现需要的字符串在两个换行符(\n)的中间,再对其进行处理 完整代码 import re txt = """ 行业报告 | 行业点评 休闲服务 证券研究报告""" result = re.findall(r"([\s\S]*)证券
-
Python爬虫教程之利用正则表达式匹配网页内容
前言 Python爬虫,除了使用大家广为使用的scrapy架构外,还有很多包能够实现一些简单的爬虫,如BeautifulSoup.Urllib.requests,在使用这些包时,有的网络因为比较复杂,比较难以找到自己想要的代码,在这个时候,如果能够使用正则表达式,将能很方便地爬取到自己想要的数据. 何为正则表达式 正则表达式是一种描述字符串排列的一种语法规则,通过该规则可以在一个大字符串中匹配出满足规则的子字符串.简单来说,就是给定了一个字符串,在字符串中找到想要的字符串,如一个电话号码,一个I
-
python正则表达式 匹配反斜杠的操作方法
python正则表达式 匹配反斜杠 正则 需要把原始字符串不被转义的条件下传递给正则模块,正则再去转义. r表示r后面的字符串为原始字符串,防止计算机将 \ 理解为转义字符. r'^\\$' 首先按照原始字符串给到compile函数 ,正则再把r'^\\$'中的\`翻译成\ backslash='\\' print(backslash) regular_backslash=re.compile(r'^\\$') print(regular_backslash.search(regular_bac
-
Python文件名匹配与文件复制的实现
文件名的匹配,实际上就是相当于获取文件名(不含后缀),然后利用获取到的文件名到另外一个文件夹中去寻找对应的文件,然后将文件取出,放置到指定文件夹下.概括的来说,分三个步骤:一是取出遍历目录A,得到各个文件文件名:二是利用该文件名,与指定路径B拼接,并加上后缀,产生目标文件名:三是根据拼接产生的目标文件名,将相应文件复制到指定目录C. 好,那么我们开始写代码吧~~~ step1:获取指定目录A下面的所有文件名.不包含文件后缀.主要基于以下思想: def GetFileNameAndExt(file
-
浅谈Python实现2种文件复制的方法
本文实例主要实现Python中的文件复制操作,有两种方法,具体实现代码如下所示: #coding:utf-8 # 方法1:使用read()和write()模拟实现文件拷贝 # 创建文件hello.txt src = file("hello.txt", "w") li = ["Hello world \n", "Hello China \n"] src.writelines(li) src.close() #把hello.txt
-
python根据多个文件名批量查找文件
本文实例为大家分享了python根据多个文件名批量查找文件的具体代码,供大家参考,具体内容如下 老板给了我一个文件列表,让我在一堆文件中挑出来,他要的文件有500多个,一堆文件有上千个,而且给的是关键词,不是完整的文件名. 我先做了类似的文件测试一下,一个名为filename的excel表 又做了一个文件夹 接下来运行代码 import os import numpy as np import pandas as pd import shutil file_path='/home/disk/yh
-
python通用读取vcf文件的类(复制粘贴即可用)
前言 处理vcf文件的时候,需要多种切割,正则匹配,如果要自己写其实会比较麻烦,并且每次还得根据vcf文件格式或者需要读取的值不同要修改相应的代码.因此很多人会选择一些python的vcf的库,但是首先你得安装这个库, 并且有一些库它固定了能够读的内容,如果你的vcf的信息不在它固定的里面,就读不出来.比如最近我想读一个样本的AF,但是它放在最后样本的GT那列,不在INFO那一列,有一些库竟然无能为力.因此我写了这个通用的读vcf的类,直接复制粘贴这部分代码就可以方便的用这个类进行vcf文件的读
-
利用Python实现Excel的文件间的数据匹配功能
我们知道Excel有一个match函数,可以做数据匹配. 比如要根据人名获取成绩 而参考表sheet1的内容如下: 要根据sheet1匹配每人的成绩,用Excel是这么写 index(Sheet1!B:B,MATCH(A2,Sheet1!A:A,0)) 意思就是获取sheet1的B列的内容,根据我的A列匹配sheet1的A列的内容 但是如何用python实现这一点呢,我写了一个函数,非常好用,分享给大家. 这个函数考虑到了匹配多个字段,多个sheet. import pandas as pd d
-
Python文件名的匹配之clob库
一.前言 既然在Pathlib库中提到了glob()函数,那么我们就专门用一篇内容讲解文件名的匹配.其实我们有专门的一个文件名匹配库就叫:glob. 不过,glob库的API非常小,但是仅仅应用于文件名的匹配绰绰有余.只要是在实际的项目中需要过滤,或者匹配一组文件,都可以使用该库进行操作. 二.通配符 星号(*) 话不多说,下面我们使用通配符来匹配文件名,示例如下: import glob for name in sorted(glob.glob('text/*')): print(name)
-
python根据文件名批量搜索文件
目录 1.准备工作 1 安装python环境 2 准备一个excel文件 2.代码 总结 需求场景,五百个文件里面,选取50个指定文件,放入新的文件夹里. 1.准备工作 1 安装python环境 可能会报错,并且pip install 这些没有的东西即可. 2 准备一个excel文件 filename.xlsx 写好要塞选出来的文件名字,如下图 2.代码 # encoding: utf-8 import os import numpy as np import pandas as pd impo
-
Python实现文件复制删除
用python实现了一个小型的工具.其实只是简单地把debug 目录下的配置文件复制到指定目录,把Release下的生成文件复制到同一指定,过滤掉不需要的文件夹(.svn),然后再往这个指定目录添加几个特定的文件. 这个是我的第一个python小程序. 下面就来看其代码的实现. 首先插入必要的库: import os import os.path import shutil import time, datetime 然后就是一大堆功能函数.第一个就是把某一目录下的所有文件复制到指定目录中: d
-
python通过shutil实现快速文件复制的方法
本文实例讲述了python通过shutil实现快速文件复制的方法.分享给大家供大家参考.具体如下: python通过shutil实现快速文件拷贝,shutil使用起来非常方便,可以通过pip install shutil安装 from shutil import * from glob import glob print 'BEFORE:', glob('shutil_copyfile.*') copyfile('sharejs.com.py', 'sharejs.com.py.copy') p