keras实现图像预处理并生成一个generator的案例
如下所示:
接下来,给出我自己目前积累的代码,从目录中自动读取图像,并产生generator:
第一步:建立好目录结构和图像
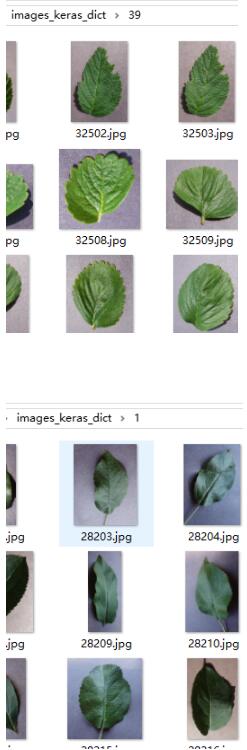
可以看到目录images_keras_dict下有次级目录,次级目录下就直接包含照片了
**第二步:写代码建立预处理程序
# 先进行预处理图像
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range=50,
height_shift_range=[-0.005, 0, 0.005],
width_shift_range=[-0.005, 0, 0.005],
horizontal_flip=True,
fill_mode='reflect')
#再对预处理图像指定从目录中读取数据,可以看到我的目录最核心的地方是images_keras_dict(可以对照上一张图片)
train_generator = train_datagen.flow_from_directory('AgriculturalDisease_trainingset/images_keras_dict',
target_size=(height, width), batch_size=16)
val_datagen = ImageDataGenerator(rescale=1./255)
val_generator = val_datagen.flow_from_directory('AgriculturalDisease_validationset/images_keras_dict', target_size=(height, width),
batch_size=64)
save_weights = ModelCheckpoint(filepath='models/best_weights.hdf5',monitor='val_loss', verbose=1, save_best_only=True)
# 最后在fit_generator 中放入生成器的函数train_generator
model.fit_generator(train_generator,
steps_per_epoch=times_train,
verbose=1,
epochs=300,
initial_epoch=0,
validation_data=val_generator,
validation_steps=times_val,
callbacks=[save_weights, TrainValTensorBoard(write_graph=False)])
第三步:写入fit_generator进行训练
已经写在上一个代码中。
第四步:写predict_generator进行预测**
首先我们需要建立同样的目录结构。把包含预测图片的次级目录放在一个文件夹下,这个文件夹名就是关键文件夹。
这里我的关键文件夹是test文件夹
# 建立预处理
predict_datagen = ImageDataGenerator(rescale=1./255)
predict_generator = predict_datagen.flow_from_directory('AgriculturalDisease_validationset/test',
target_size=(height, width), batch_size=128)
# predict_generator.reset()
# 利用predict_generator进行预测
pred = model.predict_generator(predict_generator, max_queue_size=10, workers=1, verbose=1)
# 利用几个属性来读取文件夹和对应的分类
train_datagen = ImageDataGenerator(rescale=1./255, rotation_range=40, fill_mode='wrap')
train_generator = train_datagen.flow_from_directory('new_images', target_size=(height, width), batch_size=96)
labels = (train_generator.class_indices)
labels = dict((v,k) for k,v in labels.items())
predictions = [labels[k] for k in predicted_class_indices]
# 还可以知道图片的名字
filenames = predict_generator.filenames
补充知识:[TensorFlow 2] [Keras] fit()、fit_generator() 和 train_on_batch() 分析与应用
前言
是的,除了水报错文,我也来写点其他的。本文主要介绍Keras中以下三个函数的用法:
1、fit()
2、fit_generator()
3、train_on_batch()
当然,与上述三个函数相似的evaluate、predict、test_on_batch、predict_on_batch、evaluate_generator和predict_generator等就不详细说了,举一反三嘛。
环境
本文的代码是在以下环境下进行测试的:
Windows 10
Python 3.6
TensorFlow 2.0 Alpha
异同
大家用Keras也就图个简单快捷,但是在享受简单快捷的时候,也常常需要些定制化需求,除了model.fit(),有时候model.fit_generator()和model.train_on_batch()也很重要。
那么,这三个函数有什么异同呢?Adrian Rosebrock [1] 有如下总结:
当你使用.fit()函数时,意味着如下两个假设:
训练数据可以 完整地 放入到内存(RAM)里
数据已经不需要再进行任何处理了
这两个原因解释的非常好,之前我运行程序的时候,由于数据集太大(实际中的数据集显然不会都像 TensorFlow 官方教程里经常使用的 MNIST 数据集那样小),一次性加载训练数据到fit()函数里根本行不通:
history = model.fit(train_data, train_label) // Bomb!!!
于是我想,能不能先加载一个batch训练,然后再加载一个batch,如此往复。于是我就注意到了fit_generator()函数。什么时候该使用fit_generator函数呢?Adrian Rosebrock 的总结道:
内存不足以一次性加载整个训练数据的时候
需要一些数据预处理(例如旋转和平移图片、增加噪音、扩大数据集等操作)
在生成batch的时候需要更多的处理
对于我自己来说,除了数据集太大的缘故之外,我需要在生成batch的时候,对输入数据进行padding,所以fit_generator()就派上了用场。下面介绍如何使用这三种函数。
fit()函数
fit()函数其实没什么好说的,大家在看TensorFlow教程的时候已经见识过了。此外插一句话,tf.data.Dataset对不规则的序列数据真是不友好。
import tensorflow as tf model = tf.keras.models.Sequential([ ... // 你的模型 ]) model.fit(train_x, // 训练输入 train_y, // 训练标签 epochs=5 // 训练5轮 )
fit_generator()函数
fit_generator()函数就比较重要了,也是本文讨论的重点。fit_generator()与fit()的主要区别就在一个generator上。之前,我们把整个训练数据都输入到fit()里,我们也不需要考虑batch的细节;现在,我们使用一个generator,每次生成一个batch送给fit_generator()训练。
def generator(x, y, b_size): ... // 处理函数 model.fit_generator(generator(train_x, train_y, batch_size), step_per_epochs=np.ceil(len(train_x)/batch_size), epochs=5 )
从上述代码中,我们发现有两处不同:
一个我们自定义的generator()函数,作为fit_generator()函数的第一个参数;
fit_generator()函数的step_per_epochs参数
自定义的generator()函数
该函数即是我们数据的生成器,在训练的时候,fit_generator()函数会不断地执行generator()函数,获取一个个的batch。
def generator(x, y, b_size): """Generates batch and batch and batch then feed into models. Args: x: input data; y: input labels; b_size: batch_size. Yield: (batch_x, batch_label): batched x and y. """ while 1: // 死循环 idx = ... batch_x = ... batch_y = ... ... // 任何你想要对这个`batch`中的数据执行的操作 yield (batch_x, batch_y)
需要注意的是,不要使用return或者exit。
step_per_epochs参数
由于generator()函数的循环没有终止条件,fit_generator也不知道一个epoch什么时候结束,所以我们需要手动指定step_per_epochs参数,一般的数值即为len(y)//batch_size。如果数据集大小不能整除batch_size,而且你打算使用最后一个batch的数据(该batch比batch_size要小),此时使用np.ceil(len(y)/batch_size)。
keras.utils.Sequence类(2019年6月10日更新)
除了写generator()函数,我们还可以利用keras.utils.Sequence类来生成batch。先扔代码:
class Generator(keras.utils.Sequence): def __init__(self, x, y, b_size): self.x, self.y = x, y self.batch_size = b_size def __len__(self): return math.ceil(len(self.y)/self.batch_size def __getitem__(self, idx): b_x = self.x[idx*self.batch_size:(idx+1)*self.batch_size] b_y = self.y[idx*self.batch_size:(idx+1)*self.batch_size] ... // 对`batch`的其余操作 return np.array(b_x), np.array(b_y) def on_epoch_end(self): """执行完一个`epoch`之后,还可以做一些其他的事情!""" ...
我们首先定义__init__函数,读取训练集数据,然后定义__len__函数,返回一个epoch中需要执行的step数(此时在fit_generator()函数中就不需要指定steps_per_epoch参数了),最后定义__getitem__函数,返回一个batch的数据。代码如下:
train_generator = Generator(train_x, train_y, batch_size) val_generator = Generator(val_x, val_y, batch_size) model.fit_generator(generator=train_generator, epochs=3197747, validation_data=val_generator )
根据官方 [2] 的说法,使用Sequence类可以保证在多进程的情况下,每个epoch中的样本只会被训练一次。总之,使用keras.utils.Sequence也是很方便的啦!
train_on_batch()函数
train_on_batch()函数接受一个batch的输入和标签,然后开始反向传播,更新参数等。大部分情况下你都不需要用到train_on_batch()函数,除非你有着充足的理由去定制化你的模型的训练流程。
结语
本文到此结束啦!希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
使用Keras预训练模型ResNet50进行图像分类方式
Keras提供了一些用ImageNet训练过的模型:Xception,VGG16,VGG19,ResNet50,InceptionV3.在使用这些模型的时候,有一个参数include_top表示是否包含模型顶部的全连接层,如果包含,则可以将图像分为ImageNet中的1000类,如果不包含,则可以利用这些参数来做一些定制的事情. 在运行时自动下载有可能会失败,需要去网站中手动下载,放在"~/.keras/models/"中,使用WinPython则在"settings/.ke
-
利用keras加载训练好的.H5文件,并实现预测图片
我就废话不多说了,直接上代码吧! import matplotlib matplotlib.use('Agg') import os from keras.models import load_model import numpy as np from PIL import Image import cv2 #加载模型h5文件 model = load_model("C:\\python\\python3_projects\\cat_dog\\cats_dogs_fifty_thousand.h
-
Keras使用ImageNet上预训练的模型方式
我就废话不多说了,大家还是直接看代码吧! import keras import numpy as np from keras.applications import vgg16, inception_v3, resnet50, mobilenet #Load the VGG model vgg_model = vgg16.VGG16(weights='imagenet') #Load the Inception_V3 model inception_model = inception_v3.I
-
keras实现图像预处理并生成一个generator的案例
如下所示: 接下来,给出我自己目前积累的代码,从目录中自动读取图像,并产生generator: 第一步:建立好目录结构和图像 可以看到目录images_keras_dict下有次级目录,次级目录下就直接包含照片了 **第二步:写代码建立预处理程序 # 先进行预处理图像 train_datagen = ImageDataGenerator(rescale=1./255, rotation_range=50, height_shift_range=[-0.005, 0, 0.005], width_
-
pytorch 图像预处理之减去均值,除以方差的实例
如下所示: #coding=gbk ''' GPU上面的环境变化太复杂,这里我直接给出在笔记本CPU上面的运行时间结果 由于方式3需要将tensor转换到GPU上面,这一过程很消耗时间,大概需要十秒,故而果断抛弃这样的做法 img (168, 300, 3) sub div in numpy,time 0.0110 sub div in torch.tensor,time 0.0070 sub div in torch.tensor with torchvision.transforms,tim
-
python+opencv3生成一个自定义纯色图教程
一. 图像在计算机中存储为矩阵.矩阵上一个点表示一个像素.若矩阵由一系列0-255的整数值组成,则表现为灰度图.便于理解,以下贴出代码: import cv2 import numpy as np img = np.ones((3,3),dtype=np.uint8)#random.random()方法后面不能加数据类型 #img = np.random.random((3,3)) #生成随机数都是小数无法转化颜色,无法调用cv2.cvtColor函数 img[0,0]=100 img[0,1]
-
利用python生成一个导出数据库的bat脚本文件的方法
实例如下: # 环境: python3.x def getExportDbSql(db, index): # 获取导出一个数据库实例的sql语句 sql = 'mysqldump -u%s -p%s -h%s -P%d --default-character-set=utf8 --databases mu_ins_s%s > %s.s%d.mu_ins_%d.sql' %(db['user'], db['pwd'], db['host'], db['port'], index, db['serv
-

详解JavaScript对Date对象的操作问题(生成一个倒数7天的数组)
问题描述: 使用JavaScript生成一个倒数7天的数组. 比如今天是10月1号,生成的数组是["9月25号","9月26号","9月27号","9月28号","9月29号","9月30号","10月1号"]. 这个难点就是需要判断这个月份(可能还需要上一个月份)是30天还是31天,而且还有瑞年的2月28天或者29天. 解答思路: 不需要那么复杂,在js中非常简单,
-
java随机生成一个名字和对应拼音的方法
本文实例讲述了java随机生成一个名字和对应拼音的方法.分享给大家供大家参考.具体如下: package com.cn.wangk.util.name; import java.util.Random; import com.cn.wangk.util.StrTools; public class ChineseName { String[] sName = new String[95]; String[] Name = new String[79]; private String Names;
-
JS如何生成一个不重复的ID的函数
在MongoDB中的ObjectID,可以理解为是一个不会重复的ID,这里有个链接http://www.jb51.net/article/101164.htm感兴趣可以去研究一下. 我今天要做的就是做一个不重复ID的生成器 /** * 生成一个用不重复的ID */ function GenNonDuplicateID():String{ } 先看看下面的几个方法 1.生成[0,1)的随机数的Math.random,例如 //我这次运行生成的是:0.5834165740043102 Math.ra
-
Java打乱ArrayList生成一个随机序列列表
前言 在做试卷的时候,需要将一个句子中的单词.一个单词中的字符.选择题中的答题项打乱生成一个随机的序列,下面我将其抽象成工具类,方便大家以后复用. 示例代码 public static <V> boolean isEmpty(ArrayList<V> sourceList) { return (sourceList == null || sourceList.size() == 0); } /** * 打乱ArrayList * * */ public static <V&g
-
ASP.Net生成一个简单的图片
在本节中我们通过生成一个简单的图片作为ASP.NET图形处理的入门训练.首先使用VisualStudio.NET 2003 新建一个Web 应用程序,命名为GDITec,新建一个Web 窗体命名为GDI_Sample1.aspx,我们为该窗体编写逻辑代码: '-----code begin----- Imports System.Drawing Imports System.Drawing.Bitmap Imports System.Drawing.Graphics Public Class W
-
vue打包之后生成一个配置文件修改接口的方法
前言: 我们的vue代码打包上传到服务器之后,要是数据接口 以后换了域名什么的,是不是需要重新去vue文件里修改接口. 能不能生成一个配置文件,里面可以配置域名或其它什么字段之类的,这样以后换了域名,只需打开记事本 修改一下域名即可. 教程: 第一步:安装generate-asset-webpack-plugin插件 npm install --save-dev generate-asset-webpack-plugin 第二步:配置webpack.prod.conf.js文件 //让打包的时候