卸载tensorflow-cpu重装tensorflow-gpu操作
问题描述:为了把之前的CPU版本的tensorflow卸载,换成GPU版本的tensorflow,经历了一番折腾。
BUG1 Could not install packages due to an EnvironmentError: [WinError 5] 拒绝访问
看指向的路径,感觉是在安装路径的site-packages中已经存在tensorflow文件夹了,但是执行
pip uninstall tensorflow
却提示没有安装,于是手动删除该文件夹,重新安装,此bug修复。
BUG2 ImportError: DLL load failed:找不到指定模块
网上找的很多答案都不符合,后来才发现!!!原来是CUDA装了10.1版本的,目前基本没有看到支持CUDA10.1版本的。
因此,首先卸载了CUDA10.1,在程序卸载界面删除了带版本号的以及Nsight关键字的。然后删除了C:/ProgramFiles/NVIDIA GPU Computing Toolkit
在此之前只安装了VS2013,因此也重新安装了VS2017
重新安装CUDA10.0,检查环境变量有没有修改成功
在这里查看nvcc -V时,无法调用命令,重启计算机即可解决
总的来说,配置下来是
CUDA10.0+cuDNN7.5+VS2017+python3.7+tensorflow1.13
成功从tensorflow CPU版本转成GPU版本
补充知识:Windows下卸载TensorFlow
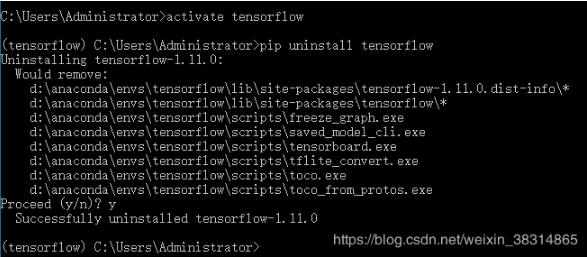
1、激活tensorflow:activate tensorflow
2、输入:pip uninstall tensorflow
3、Proceed(y/n):y
如果是gpu版本:
1、激活tensorflow:activate tensorflow-gpu
2、输入:pip uninstall tensorflow-gpu
3、Proceed(y/n):y
以上这篇卸载tensorflow-cpu重装tensorflow-gpu操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
踩坑:pytorch中eval模式下结果远差于train模式介绍
首先,eval模式和train模式得到不同的结果是正常的.我的模型中,eval模式和train模式不同之处在于Batch Normalization和Dropout.Dropout比较简单,在train时会丢弃一部分连接,在eval时则不会.Batch Normalization,在train时不仅使用了当前batch的均值和方差,也使用了历史batch统计上的均值和方差,并做一个加权平均(momentum参数).在test时,由于此时batchsize不一定一致,因此不再使用当前batch的均
-
pytorch掉坑记录:model.eval的作用说明
训练完train_datasets之后,model要来测试样本了.在model(test_datasets)之前,需要加上model.eval(). 否则的话,有输入数据,即使不训练,它也会改变权值. 这是model中含有batch normalization层所带来的的性质. 在做one classification的时候,训练集和测试集的样本分布是不一样的,尤其需要注意这一点. 补充知识:pytorch测试的时候为何要加上model.eval() Do need to use model.e
-
keras做CNN的训练误差loss的下降操作
采用二值判断如果确认是噪声,用该点上面一个灰度进行替换. 噪声点处理:对原点周围的八个点进行扫描,比较.当该点像素值与周围8个点的值小于N时,此点为噪点 . 处理后的文件大小只有原文件小的三分之一,前后的图片内容肉眼几乎无法察觉. 但是这样处理后图片放入CNN中在其他条件不变的情况下,模型loss无法下降,二分类图片,loss一直在8-9之间.准确率维持在0.5,同时,测试集的训练误差持续下降,但是准确率也在0.5徘徊.大概真是需要误差,让优化方法从局部最优跳出来. 使用的activation
-
浅谈keras中loss与val_loss的关系
loss函数如何接受输入值 keras封装的比较厉害,官网给的例子写的云里雾里, 在stackoverflow找到了答案 You can wrap the loss function as a inner function and pass your input tensor to it (as commonly done when passing additional arguments to the loss function). def custom_loss_wrapper(input_
-
基于Tensorflow使用CPU而不用GPU问题的解决
之前的文章讲过用Tensorflow的object detection api训练MobileNetV2-SSDLite,然后发现训练的时候没有利用到GPU,反而CPU占用率贼高(可能会有Could not dlopen library 'libcudart.so.10.0'之类的警告).经调查应该是Tensorflow的GPU版本跟服务器所用的cuda及cudnn版本不匹配引起的.知道问题所在之后就好办了. 检查cuda和cudnn版本 首先查看cuda版本: cat /usr/local/
-
基于Tensorflow:CPU性能分析
iostat iostat用于输出CPU和磁盘I/O相关的统计信息. 命令格式: 1)显示所有设备负载情况 指令: iostat -m 2 5 cpu属性值说明: %user:CPU处在用户模式下的时间百分比. %nice:CPU处在带NICE值的用户模式下的时间百分比. %system:CPU处在系统模式下的时间百分比. %iowait:CPU等待输入输出完成时间的百分比. %steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比. %idle:CPU空闲时间百分比. 备
-
解决TensorFlow程序无限制占用GPU的方法
今天遇到一个奇怪的现象,使用tensorflow-gpu的时候,出现内存超额~~如果我训练什么大型数据也就算了,关键我就写了一个y=W*x-显示如下图所示: 程序如下: import tensorflow as tf w = tf.Variable([[1.0,2.0]]) b = tf.Variable([[2.],[3.]]) y = tf.multiply(w,b) init_op = tf.global_variables_initializer() with tf.Session()
-
TensorFlow固化模型的实现操作
前言 TensorFlow目前在移动端是无法training的,只能跑已经训练好的模型,但一般的保存方式只有单一保存参数或者graph的,如何将参数.graph同时保存呢? 生成模型 主要有两种方法生成模型,一种是通过freeze_graph把tf.train.write_graph()生成的pb文件与tf.train.saver()生成的chkp文件固化之后重新生成一个pb文件,这一种现在不太建议使用.另一种是把变量转成常量之后写入PB文件中.我们简单的介绍下freeze_graph方法. f
-
keras和tensorflow使用fit_generator 批次训练操作
fit_generator 是 keras 提供的用来进行批次训练的函数,使用方法如下: model.fit_generator(generator, steps_per_epoch=None, epochs=1, verbose=1, callbacks=None, validation_data=None, validation_steps=None, class_weight=None, max_queue_size=10, workers=1, use_multiprocessing=F
-
将Pytorch模型从CPU转换成GPU的实现方法
最近将Pytorch程序迁移到GPU上去的一些工作和思考 环境:Ubuntu 16.04.3 Python版本:3.5.2 Pytorch版本:0.4.0 0. 序言 大家知道,在深度学习中使用GPU来对模型进行训练是可以通过并行化其计算来提高运行效率,这里就不多谈了. 最近申请到了实验室的服务器来跑程序,成功将我简陋的程序改成了"高大上"GPU版本. 看到网上总体来说少了很多介绍,这里决定将我的一些思考和工作记录下来. 1. 如何进行迁移 由于我使用的是Pytorch写的模型,网上给
-
TensorFlow和keras中GPU使用的设置操作
1. 训练运行时候指定GPU 运行时候加一行代码: CUDA_VISIBLE_DEVICES=1 python train.py 2. 运行过程中按需或者定量分配GPU tensorflow直接在开启Session时候加几行代码就行,而Keras指定GPU,并限制按需用量和TensorFlow不太一样,因为keras训练是封装好的,不好对Session操作.如下是两种对应的操作. keras中的操作: import os import tensorflow as tf from keras.ba
-
tensorflow指定CPU与GPU运算的方法实现
1.指定GPU运算 如果安装的是GPU版本,在运行的过程中TensorFlow能够自动检测.如果检测到GPU,TensorFlow会尽可能的利用找到的第一个GPU来执行操作. 如果机器上有超过一个可用的GPU,除了第一个之外的其他的GPU默认是不参与计算的.为了让TensorFlow使用这些GPU,必须将OP明确指派给他们执行.with......device语句能够用来指派特定的CPU或者GPU执行操作: import tensorflow as tf import numpy as np w
-

Window10上Tensorflow的安装(CPU和GPU版本)
之前摸索tensorflow的时候安装踩坑的时间非常久,主要是没搞懂几个东西的关系,就在瞎调试,以及当时很多东西不懂,很多报错也一知半解的.这次重装系统后正好需要再配置一次,把再一次的经历记录一下.我的电脑是华为的matebook13,intel i5-8625U,MX250显卡,win10系统.(不得不吐槽很垃圾,只能满足测试测试调调代码的需求) 深度学习利用Tensorflow平台,其中的Keras Sequential API对新用户非常的友好,可以将各基础组件组合在一起来构建模型. (官
-
详解tf.device()指定tensorflow运行的GPU或CPU设备实现
在tensorflow中,我们可以使用 tf.device() 指定模型运行的具体设备,可以指定运行在GPU还是CUP上,以及哪块GPU上. 设置使用GPU 使用 tf.device('/gpu:1') 指定Session在第二块GPU上运行: import tensorflow as tf with tf.device('/gpu:1'): v1 = tf.constant([1.0, 2.0, 3.0], shape=[3], name='v1') v2 = tf.constant([1.0