一次SQL如何查重及去重的实战记录
目录
- 前言
- ️1.distinct
- ️2.groupby
- ️3.row_number窗口函数
- ️4.删除重复数据
- 第一步:找出重复的数据
- 第二步:删除重复的数据
- 总结
前言
在使用SQL提数的时候,常会遇到表内有重复值的时候,就需要做去重,本文归类了常用方法。
️ 1.distinct
题目:现在运营需要查看用户来自于哪些学校,请从用户信息表中取出学校的去重数据
示例:user_profile
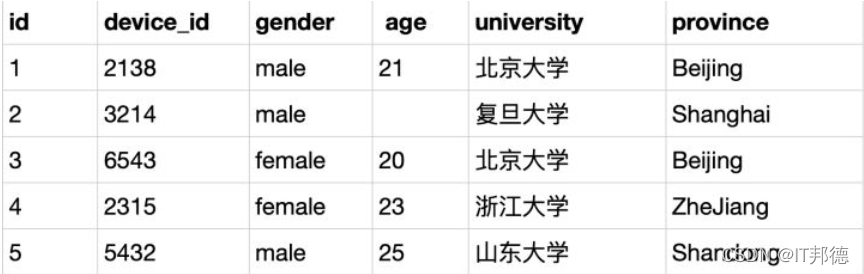
mysql>SELECT DISTINCT university FROM user_profile;
根据示例,查询返回以下结果

小贴士:
SQL中关键词distinct去重:
英语中distinct 代表独一无二的意思,
他在SQL表示去重的意思:比如本题中university这一列出现了两次北京大学,
使用distinct进行去重查询后,则北京大学只出现一次。
distinct 通常效率较低
distinct 使用中,放在 select 后边,对后面所有的字段的值统一进行去重
拓展:
题目:现在运营需要查看用户的总数
select count(distinct university) from user_profile;
️ 2.group by
举个栗子,现有这样一张表 task
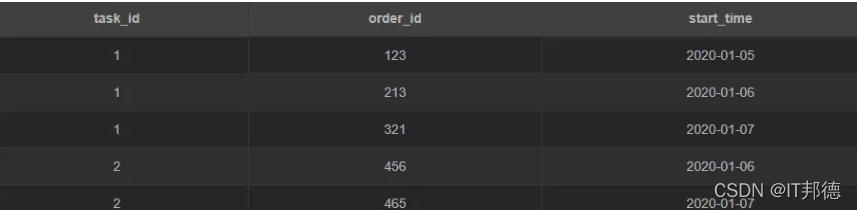
备注:
task_id: 任务id;
order_id: 订单id;
start_time: 开始时间
注意:一个任务对应多条订单
题目:列出任务总数
根据示例,查询方法如下:
第1步:列出 task_id 的所有唯一值(去重后的记录,null也是值)
select task_id from Task group by task_id;
第二步: 任务总数
select count(task_id) task_num from (select task_id from Task group by task_id) tmp;
️ 3.row_number 窗口函数
举个栗子,现有这样一张表 task
备注:
task_id: 任务id;
order_id: 订单id;
start_time: 开始时间
注意:一个任务对应多条订单
题目:查询整个表重复的数据
根据示例,查询方法如下:
– 在支持窗口函数的 sql 中使用
select count(case when rn=1 then task_id else null end) task_num from (select task_id , row_number() over (partition by task_id order by start_time) rn from Task) tmp;
小贴士:
MySQL8.0 中可以利用 ROW_NUMBER(),DENSE_RANK(),RANK() 三个窗口函数来实现排序
需要注意的一点是 as 后的别名,千万不要与前面的函数名重名,否则会报错
下面给出这三种函数实现排名的案例:
–三条语句对于上面三种排名
select xuehao,score, ROW_NUMBER() OVER(order by score desc) as row_r from scores_tb; select xuehao,score, DENSE_RANK() OVER(order by score desc) as dense_r from scores_tb; select xuehao,score, RANK() over(order by score desc) as r from scores_tb;
– 一条语句也可以查询出不同排名
SELECT xuehao,score, ROW_NUMBER() OVER w AS ‘row_r', DENSE_RANK() OVER w AS ‘dense_r', RANK() OVER w AS ‘r' FROM scores_tb WINDOW w AS (ORDER BY score desc);
️ 4.删除重复数据
创建测试数据
我们创建一个人员信息表并在里面插入一些重复的数据
CREATE TABLE Person( id int auto_increment primary key comment ‘主键', Name VARCHAR(20) NULL, Age INT NULL, Address VARCHAR(20) NULL, Sex CHAR(2) NULL );
INSERT INTO Person(ID,Name,Age,Address,Sex) VALUES ( 1, ‘张三', 18, ‘北京路18号', ‘男' ), ( 2, ‘李四', 19, ‘北京路29号', ‘男' ), ( 3, ‘王五', 19, ‘南京路11号', ‘女' ), ( 4, ‘张三', 18, ‘北京路18号', ‘男' ), ( 5, ‘李四', 19, ‘北京路29号', ‘男' ), ( 6, ‘张三', 18, ‘北京路18号', ‘男' ), ( 7, ‘王五', 19, ‘南京路11号', ‘女' ), ( 8, ‘马六', 18, ‘南京路19号', ‘女' );
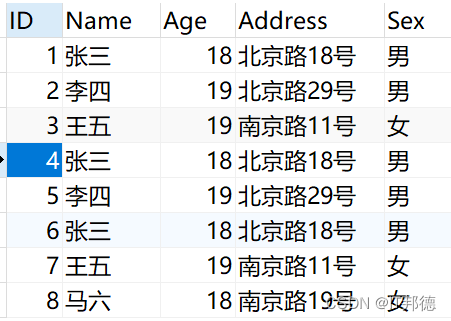
题目:数据库中存在重复记录,删除保留其中一条
我们发现除了自增长ID不同以为,有几条其他字段都重复的数据出现
第一步:找出重复的数据
mysql>SELECT MAX(ID) ID, Name,Age,Address,Sex FROM Person GROUP BY Name,Age,Address,Sex HAVING COUNT(1)>1
小贴士:
HAVING将分组后统计出来的数量大于1的数据行,就是我们要找的重复数据
上面用Max函数或者Min函数均可,只是为了保证取出来的数据的唯一性。
第二步:删除重复的数据
其实我们数据库中最后要保留的结果就是第二步中查询出来的数据,
我们把其他的数据删除即可。
怎么删除呢?我们使用ID来排除。
DELETE FROM Person WHERE EXISTS ( SELECT * FROM ( SELECT MAX(ID) ID, Name,Age,Address,Sex FROM Person GROUP BY Name,Age,Address,Sex HAVING COUNT(1)>1) T WHERE Person.Name=T.Name AND Person.Age=T.Age AND Person.Address=T.Address AND Person.Sex=T.Sex AND Person.ID<T.ID )
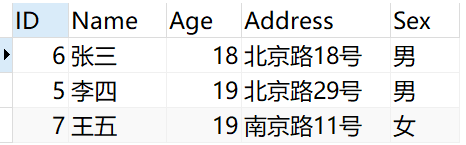
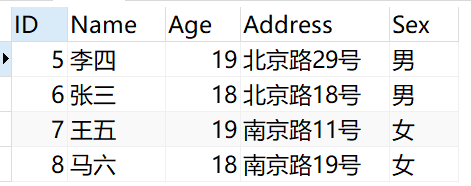
执行完后重新查询Person表结果如下
马六因为只有一条记录,所以没有参与去重,直接显示。
总结
到此这篇关于SQL如何查重及去重的文章就介绍到这了,更多相关SQL查重去重内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL 数据查重、去重的实现语句
有一个表user,字段分别有id.nick_name.password.email.phone. 一.单字段(nick_name) 查出所有有重复记录的所有记录 select * from user where nick_name in (select nick_name from user group by nick_name having count(nick_name)>1); 查出有重复记录的各个记录组中id最大的记录 select * from user where id in (se
-
mysql去重的两种方法详解及实例代码
mysql去重 方法一: 在使用MySQL时,有时需要查询出某个字段不重复的记录,虽然mysql提供 有distinct这个关键字来过滤掉多余的重复记录只保留一条,但往往只用它来返回不重复记录的条数,而不是用它来返回不重记录的所有值.其原因是 distinct只能返回它的目标字段,而无法返回其它字段 下面先来看看例子: table id name 1 a 2 b 3 c 4 c 5 b 库结构大概这样,这只是一个简单的例子,实际情况会复杂得多. 比如我想用一条语句查询得到name不重复的所有
-
MySQL去重的方法整理
MySQL去重的方法整理 [初级]有极少的重复行 使用distinct查出来,然后手动一行一行删除. [中级]按照单个字段的重复去重 例如:对id字段去重 使用方法:获取id的重复字段的值,利用相同id字段所在的行中,比较出数据不同的字段,删除 除了最小(或最大)的字段所在的该行之外的所有重复的行.一般使用主键来比较,因为主键的值一定是唯一值,绝对不相同. id name 1 a 1 b 2 c 2 a 3 c 结果: id name 1 a 2 a 操作: delete from a_tmp
-

浅谈sql数据库去重
关于sql去重,我简单谈一下自己的简介,如果各位有建议或有不明白的欢迎多多指出. 关于sql去重最常见的有两种方式:DISTINCT和ROW_NUMBER(),当然了ROW_NUMBER()除了去重还有很多其他比较重要的功能,一会我给大家简单说说我自己在实际中用到的. 假如有张UserInfo表,如下图: 现在我们要去掉完全重复的数据:SELECT DISTINCT * FROM dbo.UserInfo结果如下图: 但是现在有个新的需求,要把名字为'张三'的去重,也就是相同名字的只要一条数
-
一条sql语句完成MySQL去重留一
前几天在做一个需求的时候,需要清理mysql中重复的记录,当时的想法是通过代码遍历写出来,然后觉得太复杂,心里想着应该可以通过一个sql语句来解决问题的.查了资料,请教了大佬之后得出了一个很便利的sql语句,这里分享下这段sql语句和思路. 需求分析 数据库中存在重复记录,删除保留其中一条(是否重复判断基准为多个字段) 解决方案 碰到这个需求的时候,心里大概是有思路的.最快想到的是可以通过一条sql语句来解决,无奈自己对于复杂sql语句的道行太浅,所以想找大佬帮忙. 找人帮忙 因为这个需求有点着
-
mysql 开发技巧之JOIN 更新和数据查重/去重
主要涉及:JOIN .JOIN 更新.GROUP BY HAVING 数据查重/去重 1 INNER JOIN.LEFT JOIN.RIGHT JOIN.FULL JOIN(MySQL 不支持).CROSS JOIN 这是在网上找到的非常好的一篇博文,图解 join 语句: CODING HORROR-A Visual Explanation of SQL Joins 下图可以很清楚的明白,join 的数据选取范围 [][1] [1]: http://7xs09x.com1.z0.glb.clo
-
SQL分组排序去重复的小实例
复制代码 代码如下: SELECT *FROM ( SELECT userid, classid, remark, ROW_NUMBER () OVER ( PARTITION BY userid, classid ORDER BY addtime DESC
-
一次SQL如何查重及去重的实战记录
目录 前言 ️1.distinct ️2.groupby ️3.row_number窗口函数 ️4.删除重复数据 第一步:找出重复的数据 第二步:删除重复的数据 总结 前言 在使用SQL提数的时候,常会遇到表内有重复值的时候,就需要做去重,本文归类了常用方法. ️ 1.distinct 题目:现在运营需要查看用户来自于哪些学校,请从用户信息表中取出学校的去重数据 示例:user_profile mysql>SELECT DISTINCT university FROM user_profile;
-
Javascript面试经典套路reduce函数查重
今天在偶然间查看到了一段代码,代码使用了很短的篇幅完成了字符串统计相同字符次数这个经典面试题,其中用到了reduce这个方法,网上查了查,没有查到什么有价值的东西,导致浪费了我一些时间才看懂,现将我的思路整理如下: 原代码: var arr="qweqrq" var info= arr.split('').reduce((a,b)=> (a[b]++ || (a[b]=1),a) ,{}) console.log(info) 代码思路是这样的,先将字符串arr通过split方法切
-
用python对excel查重
最近媳妇工作上遇到一个重复性劳动,excel表格查重,重复的标记起来,问我能不能写个程序让它自动查重标记 必须安排 第一次正儿八经写python,边上网查资料,边写 终于成功了 在此记录一下 首先安装xlwings库 pip install xlwings 写代码 import xlwings as xw # 输入表名 title = input() # 指定不显示地打开Excel,读取Excel文件 app = xw.App(visible=False, add_book=False) wb
-
python基于搜索引擎实现文章查重功能
前言 文章抄袭在互联网中普遍存在,很多博主都收受其烦.近几年随着互联网的发展,抄袭等不道德行为在互联网上愈演愈烈,甚至复制.黏贴后发布标原创屡见不鲜,部分抄袭后的文章甚至标记了一些联系方式从而使读者获取源码等资料.这种恶劣的行为使人愤慨. 本文使用搜索引擎结果作为文章库,再与本地或互联网上数据做相似度对比,实现文章查重:由于查重的实现过程与一般情况下的微博情感分析实现流程相似,从而轻易的扩展出情感分析功能(下一篇将在此篇代码的基础上完成数据采集.清洗到情感分析的整个过程). 由于近期时间上并不充
-
SQL中的三种去重方法小结
目录 distinct group by row_number 在使用SQL提数的时候,常会遇到表内有重复值的时候,比如我们想得到 uv (独立访客),就需要做去重. 在 MySQL 中通常是使用 distinct 或 group by子句,但在支持窗口函数的 sql(如Hive SQL.Oracle等等) 中还可以使用 row_number 窗口函数进行去重. 举个栗子,现有这样一张表 task: task_id order_id start_time 1 123 2020-01-05 1 2
-
论文查重python文本相似性计算simhash源码
场景: 1.计算SimHash值,及Hamming距离.2.SimHash适用于较长文本(大于三五百字)的相似性比较,文本越短误判率越高. Python实现: 代码如下 # -*- encoding:utf-8 -*- import math import jieba import jieba.analyse class SimHash(object): def getBinStr(self, source): if source == "": return 0 else: x = o
-
MySQL实战记录之如何快速定位慢SQL
目录 开启慢查询日志 系统变量 修改配置文件 设置全局变量 分析慢查询日志 mysqldumpslow pt-query-digest 用法实战 总结 开启慢查询日志 在项目中我们会经常遇到慢查询,当我们遇到慢查询的时候一般都要开启慢查询日志,并且分析慢查询日志,找到慢sql,然后用explain来分析 系统变量 MySQL和慢查询相关的系统变量如下 参数 含义 slow_query_log 是否启用慢查询日志, ON为启用,OFF为没有启用,默认为OFF log_output 日志输出位置,默
-
使用sql语句insert之前判断是否已存在记录
目录 sql语句insert之前判断是否已存在记录 关于sql 插入时做判断 简单收集 sql语句insert之前判断是否已存在记录 INSERT INTO test(A,B) select 'ab',2 WHERE NOT EXISTS (SELECT * FROM test WHERE A='ab'); 关于sql 插入时做判断 简单收集 在做用户模块或其他模块要求数据库唯一性的时候在插入数据需要先判断一下数据库中是否已经存在; 这条sql 最基础的插入语句, ```sql ```sql I