使用Lucene.NET实现站内搜索
导入Lucene.NET 开发包
Lucene 是apache软件基金会一个开放源代码的全文检索引擎工具包,是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene.Net 是 .NET 版的Lucene。
你可以在这里下载到最新的Lucene.NET
创建索引、更新索引、删除索引

搜索,根据索引查找
IndexHelper 添加、更新、删除索引
using System;
using Lucene.Net.Store;
using Lucene.Net.Index;
using Lucene.Net.Analysis.PanGu;
using Lucene.Net.Documents;
namespace BLL
{
class IndexHelper
{
/// <summary>
/// 日志小助手
/// </summary>
static Common.LogHelper logger = new Common.LogHelper(typeof(SearchBLL));
/// <summary>
/// 索引保存的位置,保存在配置文件中从配置文件读取
/// </summary>
static string indexPath = Common.ConfigurationHelper.AppSettingMapPath("IndexPath");
/// <summary>
/// 创建索引文件或更新索引文件
/// </summary>
/// <param name="item">索引信息</param>
public static void CreateIndex(Model.HelperModel.IndexFileHelper item)
{
try
{
//索引存储库
FSDirectory directory = FSDirectory.Open(new System.IO.DirectoryInfo(indexPath), new NativeFSLockFactory());
//判断索引是否存在
bool isUpdate = IndexReader.IndexExists(directory);
if (isUpdate)
{
//如果索引目录被锁定(比如索引过程中程序异常退出),则首先解锁
if (IndexWriter.IsLocked(directory))
{
//解锁索引库
IndexWriter.Unlock(directory);
}
}
//创建IndexWriter对象,添加索引
IndexWriter writer = new IndexWriter(directory, new PanGuAnalyzer(), !isUpdate, Lucene.Net.Index.IndexWriter.MaxFieldLength.UNLIMITED);
//获取新闻 title部分
string title = item.FileTitle;
//获取新闻主内容
string body = item.FileContent;
//为避免重复索引,所以先删除number=i的记录,再重新添加
//尤其是更新的话,更是必须要先删除之前的索引
writer.DeleteDocuments(new Term("id", item.FileName));
//创建索引文件 Document
Document document = new Document();
//只有对需要全文检索的字段才ANALYZED
//添加id字段
document.Add(new Field("id", item.FileName, Field.Store.YES, Field.Index.NOT_ANALYZED));
//添加title字段
document.Add(new Field("title", title, Field.Store.YES, Field.Index.NOT_ANALYZED));
//添加body字段
document.Add(new Field("body", body, Field.Store.YES, Field.Index.ANALYZED, Lucene.Net.Documents.Field.TermVector.WITH_POSITIONS_OFFSETS));
//添加url字段
document.Add(new Field("url", item.FilePath, Field.Store.YES, Field.Index.NOT_ANALYZED));
//写入索引库
writer.AddDocument(document);
//关闭资源
writer.Close();
//不要忘了Close,否则索引结果搜不到
directory.Close();
//记录日志
logger.Debug(String.Format("索引{0}创建成功",item.FileName));
}
catch (SystemException ex)
{
//记录错误日志
logger.Error(ex);
throw;
}
catch (Exception ex)
{
//记录错误日志
logger.Error(ex);
throw;
}
}
/// <summary>
/// 根据id删除相应索引
/// </summary>
/// <param name="guid">要删除的索引id</param>
public static void DeleteIndex(string guid)
{
try
{
////索引存储库
FSDirectory directory = FSDirectory.Open(new System.IO.DirectoryInfo(indexPath), new NativeFSLockFactory());
//判断索引库是否存在索引
bool isUpdate = IndexReader.IndexExists(directory);
if (isUpdate)
{
//如果索引目录被锁定(比如索引过程中程序异常退出),则首先解锁
if (IndexWriter.IsLocked(directory))
{
IndexWriter.Unlock(directory);
}
}
IndexWriter writer = new IndexWriter(directory, new PanGuAnalyzer(), !isUpdate, Lucene.Net.Index.IndexWriter.MaxFieldLength.UNLIMITED);
//删除索引文件
writer.DeleteDocuments(new Term("id", guid));
writer.Close();
directory.Close();//不要忘了Close,否则索引结果搜不到
logger.Debug(String.Format("删除索引{0}成功", guid));
}
catch (Exception ex)
{
//记录日志
logger.Error(ex);
//抛出异常
throw;
}
}
}
}
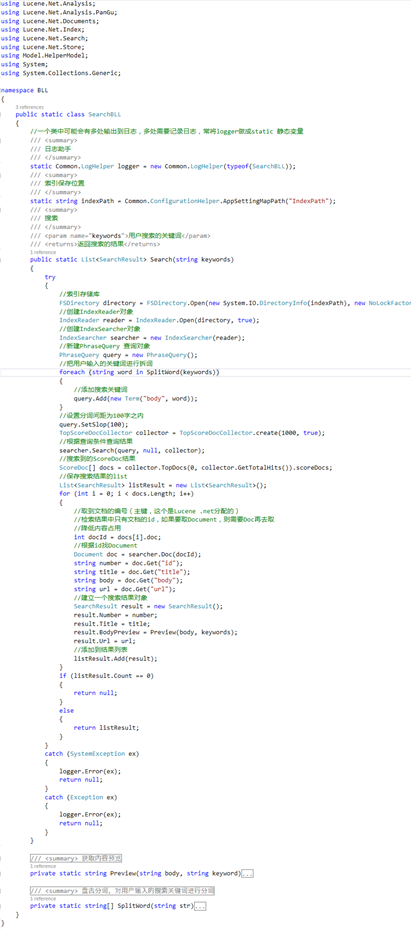
Search 通过查找索引实现搜索
using Lucene.Net.Analysis;
using Lucene.Net.Analysis.PanGu;
using Lucene.Net.Documents;
using Lucene.Net.Index;
using Lucene.Net.Search;
using Lucene.Net.Store;
using Model.HelperModel;
using System;
using System.Collections.Generic;
namespace BLL
{
public static class SearchBLL
{
//一个类中可能会有多处输出到日志,多处需要记录日志,常将logger做成static 静态变量
/// <summary>
/// 日志助手
/// </summary>
static Common.LogHelper logger = new Common.LogHelper(typeof(SearchBLL));
/// <summary>
/// 索引保存位置
/// </summary>
static string indexPath = Common.ConfigurationHelper.AppSettingMapPath("IndexPath");
/// <summary>
/// 搜索
/// </summary>
/// <param name="keywords">用户搜索的关键词</param>
/// <returns>返回搜索的结果</returns>
public static List<SearchResult> Search(string keywords)
{
try
{
//索引存储库
FSDirectory directory = FSDirectory.Open(new System.IO.DirectoryInfo(indexPath), new NoLockFactory());
//创建IndexReader对象
IndexReader reader = IndexReader.Open(directory, true);
//创建IndexSearcher对象
IndexSearcher searcher = new IndexSearcher(reader);
//新建PhraseQuery 查询对象
PhraseQuery query = new PhraseQuery();
//把用户输入的关键词进行拆词
foreach (string word in SplitWord(keywords))
{
//添加搜索关键词
query.Add(new Term("body", word));
}
//设置分词间距为100字之内
query.SetSlop(100);
TopScoreDocCollector collector = TopScoreDocCollector.create(1000, true);
//根据查询条件查询结果
searcher.Search(query, null, collector);
//搜索到的ScoreDoc结果
ScoreDoc[] docs = collector.TopDocs(0, collector.GetTotalHits()).scoreDocs;
//保存搜索结果的list
List<SearchResult> listResult = new List<SearchResult>();
for (int i = 0; i < docs.Length; i++)
{
//取到文档的编号(主键,这个是Lucene .net分配的)
//检索结果中只有文档的id,如果要取Document,则需要Doc再去取
//降低内容占用
int docId = docs[i].doc;
//根据id找Document
Document doc = searcher.Doc(docId);
string number = doc.Get("id");
string title = doc.Get("title");
string body = doc.Get("body");
string url = doc.Get("url");
//建立一个搜索结果对象
SearchResult result = new SearchResult();
result.Number = number;
result.Title = title;
result.BodyPreview = Preview(body, keywords);
result.Url = url;
//添加到结果列表
listResult.Add(result);
}
if (listResult.Count == 0)
{
return null;
}
else
{
return listResult;
}
}
catch (SystemException ex)
{
logger.Error(ex);
return null;
}
catch (Exception ex)
{
logger.Error(ex);
return null;
}
}
/// <summary>
/// 获取内容预览
/// </summary>
/// <param name="body">内容</param>
/// <param name="keyword">关键词</param>
/// <returns></returns>
private static string Preview(string body, string keyword)
{
//创建HTMLFormatter,参数为高亮单词的前后缀
PanGu.HighLight.SimpleHTMLFormatter simpleHTMLFormatter = new PanGu.HighLight.SimpleHTMLFormatter("<font color=\"red\">", "</font>");
//创建 Highlighter ,输入HTMLFormatter 和 盘古分词对象Semgent
PanGu.HighLight.Highlighter highlighter = new PanGu.HighLight.Highlighter(simpleHTMLFormatter, new PanGu.Segment());
//设置每个摘要段的字符数
highlighter.FragmentSize = 100;
//获取最匹配的摘要段
string bodyPreview = highlighter.GetBestFragment(keyword, body);
return bodyPreview;
}
/// <summary>
/// 盘古分词,对用户输入的搜索关键词进行分词
/// </summary>
/// <param name="str">用户输入的关键词</param>
/// <returns>分词之后的结果组成的数组</returns>
private static string[] SplitWord(string str)
{
List<string> list = new List<string>();
Analyzer analyzer = new PanGuAnalyzer();
TokenStream tokenStream = analyzer.TokenStream("", new System.IO.StringReader(str));
Lucene.Net.Analysis.Token token = null;
while ((token = tokenStream.Next()) != null)
{
list.Add(token.TermText());
}
return list.ToArray();
}
}
}
SearchResult 模型
namespace Model.HelperModel
{
public class SearchResult
{
public string Number { get; set; }
public string Title { get; set; }
public string BodyPreview { get; set; }
public string Url { get; set; }
}
}
以上所述就是本文的全部内容了,希望大家能够喜欢。
相关推荐
-

基于Lucene的Java搜索服务器Elasticsearch安装使用教程
一.安装Elasticsearch Elasticsearch下载地址:http://www.elasticsearch.org/download/ ·下载后直接解压,进入目录下的bin,在cmd下运行elasticsearch.bat 即可启动Elasticsearch ·用浏览器访问: http://localhost:9200/ ,如果出现类似如下结果则说明安装成功: { "name" : "Benedict Kine", "cluster_na
-
Java实现lucene搜索功能的方法(推荐)
直接上代码: package com.sand.mpa.sousuo; import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.FileWriter; import java.io.IOException; import java.io.PrintWriter; import java.sql.Connection; import java.sql.DriverMa
-
使用Java的Lucene搜索工具对检索结果进行分组和分页
使用GroupingSearch对搜索结果进行分组 Package org.apache.lucene.search.grouping Description 这个模块可以对Lucene的搜索结果进行分组,指定的单值域被聚集到一起.比如,根据"author"域进行分组,"author"域值相同的的文档分成一个组. 进行分组的时候需要输入一些必要的信息: 1.groupField:根据这个域进行分组.比如,如果你使用"author"域进行分组,那么
-
使用Lucene实现一个简单的布尔搜索功能
什么是lucene Lucene是apache软件基金会jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言). Lucene是一个全文搜索框架,而不是应用产品.因此它并不像www.baidu.com 或者google Desktop那么拿来就能用,它只是提供了一种工具让你能实现这些产品. 在布尔查询的对象中,包含一个子句的集合,各个子句间都是如
-
Lucene.Net实现搜索结果分类统计功能(中小型网站)
最近我们搜易站内搜索系统的一个客户需要一个无限级分类和分类统计功能,要实现的效果如下: 但由于搜易站内搜索系统是基于Lucene.net 2.0开发的,并没有内置的分类统计搜索功能,于是乎只能自己实现了,考虑到客户的总数据量和搜索量不是特别大,于是用了简单有效的方式来实现: 因为涉及到分类的操作,但是每个站点的分类体系还是有些不一样的,本文主要提供思路和部分演示代码,给有需要的童鞋参考: 思路: 首先想到Lucene搜索出来的结果是一个Hits对象,Hits其实就是一个搜索结果文档的集合对象,那
-
基于ASP.NET的lucene.net全文搜索实现步骤
在做项目的时候,需求添加全文搜索,选择了lucene.net方向,调研了一下,基本实现了需求,现在将它分享给大家.理解不深请多多包涵. 在完成需求的时候,查看的大量的资料,本文不介绍详细的lucene.net工程建立,只介绍如何对文档进行全文搜索.对于如何建立lucene.net的工程请大家访问 使用lucene.net搜索分为两个部分,首先是创建索引,创建文本内容的索引,其次是根据创建的索引进行搜索.那么如何对文档进行索引呢,主要是对文档的内容进行索引,关键是提取出文档的内容,按照常规实现,由
-
使用Lucene.NET实现站内搜索
导入Lucene.NET 开发包 Lucene 是apache软件基金会一个开放源代码的全文检索引擎工具包,是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎.Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎.Lucene.Net 是 .NET 版的Lucene. 你可以在这里下载到最新的Lucene.NET 创建索引.更新索引.删除索引 搜索,根据索引查找 IndexHelper
-
php站内搜索关键词变亮的实现方法
本文实例讲述了php站内搜索关键词变亮的实现方法.分享给大家供大家参考.具体分析如下: 我们这个做法是把搜索结果出来,与搜索关键词相同的替换成高亮的字, 我们会用到str_replace(你找的关键字,<带有高亮的html标签>你找的关键字,$str); 就这么容易了,好了下面我们来看一个实例吧. 先创建一个数据库:create database 'searchKey'; 再创建表,SQL建库代码如下: 复制代码 代码如下: CREATE TABLE `fangke_cc`.`search`
-
Google和百度、雅虎的站内搜索代码
对于一个网站来说,使用搜索引擎来进行站内搜索往往比自己编写的站内搜索更高效,并且不占用网站服务器的资源,下面是我搜集到的几个主要搜索引擎(Google和百度.雅虎)的站内搜索代码,使用时只需要将代码里的"www.jb51.net"替换成你的网址即可. <!--Google站内搜索开始--> <form method=get action="http://www.google.com/search"> <input type=text n
-
如何用FileSystemObject组件来做一个站内搜索?
searchpage.htm' 搜索页面. <html> <head> <title>千花飞舞之站内搜索引擎</title> </head> <body> <CENTER> <FORM METHOD=POST ACTION="searchresult.asp"> <TABLE BGCOLOR="#BLUE"
-
php站内搜索并高亮显示关键字的实现代码
复制代码 代码如下: <?php require_once 'sqlTools.class.php';//封装类,可执行dql.dml语句 $info=$_POST['info']; $sql="select name,password,email from user_500 where name like '%$info%' or password like '%$info%' or email like '%$info%'"; $sqlTools=new SqlTools()
-
用ASP做一个TOP COOL的站内搜索
该搜索引擎由一个HTM文件一个ASP文件组成,主要是运用FILESYSTEMOBJECT组件来达到目的,功能强大,修改界面以后可以直接拿来使用,当然加上一点自己的东西就更加好了. searchpage.htm 该HTM文件用来传入条件 <HTML> <HEAD> <TITLE>ASP搜索引擎范例</TITLE> </HEAD> <BODY> <CENTER> <FORM METHOD=POST ACTION=&quo
-
基于python + django + whoosh + jieba 分词器实现站内检索功能
基于 python django 源码 前期准备 安装库: pip install django-haystack pip install whoosh pip install jieba 如果pip 安装超时,可配置pip国内源下载,如下: pip install -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com <安装的库> pip install -i http://mirrors.al
-
python实现搜索指定目录下文件及文件内搜索指定关键词的方法
本文实例讲述了python实现搜索指定目录下文件及文件内搜索指定关键词的方法.分享给大家供大家参考.具体实现方法如下: #!/usr/bin/python -O # -*- coding: UTF-8 -*- """ Sucht rekursiv in Dateiinhalten und listet die Fundstellen auf. """ __author__ = "Jens Diemer" __license__
-
分享网站群发站内信数据库表设计
"站内信"不同于电子邮件,电子邮件通过专门的邮件服务器发送.保存.而"站内信"是系统内的消息,说白了,"站内信"的实现,就是通过数据库插入记录来实现的. "站内信"有两个基本功能.一:点到点的消息传送.用户给用户发送站内信:管理员给用户发送站内信.二:点到面的消息传送.管理员给用户(指定满足某一条件的用户群)群发消息.点到点的消息传送很容易实现,本文不再详述.下面将根据不同的情况,来说说"站内信"的群发是如
-
一个用js实现的页内搜索代码
<FORM name=search onsubmit="return findInPage(this.string.value);"> <INPUT onchange="n = 0;" size=15 name=string value="首相"> <INPUT type=submit value=页内搜索...></FORM> <SCRIPT language=JavaScrip