深入探究node之Transform
本文详细的介绍了node Transform ,分享给大家,希望此文章对各位有所帮助。
Transform流特性
在开发中直接接触Transform流的情况不是很多,往往是使用相对成熟的模块或者封装的API来完成流的处理,最为特殊的莫过于through2模块和gulp流操作。那么,Transform流到底有什么特点呢?
从名称上说,Transform意为处理,类似于生产流水线上的每一道工序,每道工序针对到来的产品作相应的处理;从结构上看,Transform是一个双工流,通俗的解释它既可以作为可读流,也可作为可写流。但是,node却对Transform流针对其特性做了更为特殊的定制,使Transform不是单纯的Duplex流。
Transform流由于包含了Readable和Writeable特性,因此Transform在实际使用中有着多种方式:它既可以只作为消费者消费数据,也可同时作为生产者和消费者完成数据中间处理。下面将逐渐深入内部阐述Transform的运行机理及使用技巧。
Transform内部架构
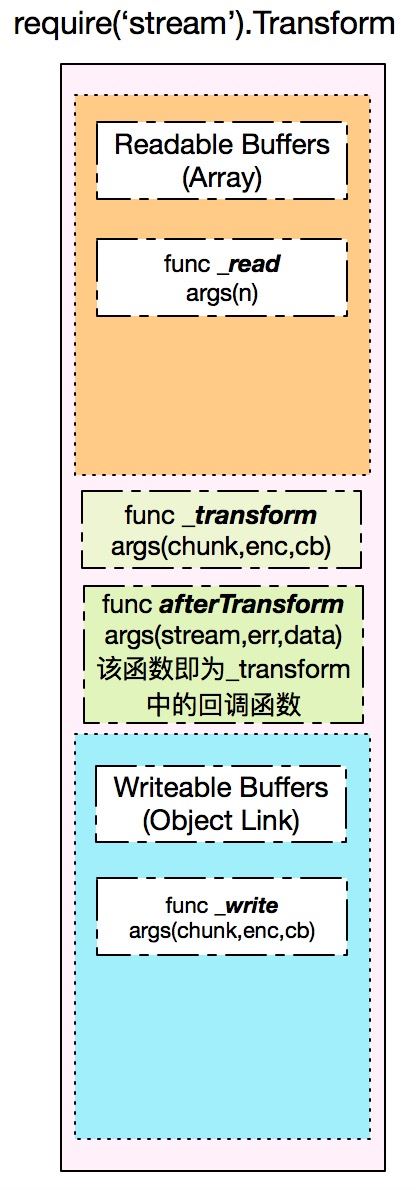
上图表示一个Transform实例的组成部分:Readable部分缓冲(数组)、内部_read函数、Writeable部分缓冲(链表)、内部_write函数、Transform实例必须实现的内部_transform函数以及系统提供的回调函数afterTransform。由于Transform实例同时拥有两部分缓冲,因此2个缓冲的存储、消耗的顺序也就需要了解,这对于后面使用原生Transform编写代码有很大的指导意义。
传统意义的流(即Readable和Writeable)的实现者都需要实现对应的内部函数_read()和_write(),对于Readable实例而言,_read函数用于准备从源文件中获取数据并添加到读缓冲中;对于Writeable实例_write函数则从写缓冲链表中一次刷入到磁盘中。它们分别对应了读写流程的首尾步骤,具体可以关注node中的Stream一文。
而Transform中的_read和_write函数的实现大有不同,由于需要兼顾流的处理,因此着重分析Transform的内部函数执行流程。
示例demo:
readable.pipe(transform);
以上段示例代码为例,transform作为消费者消费readable。
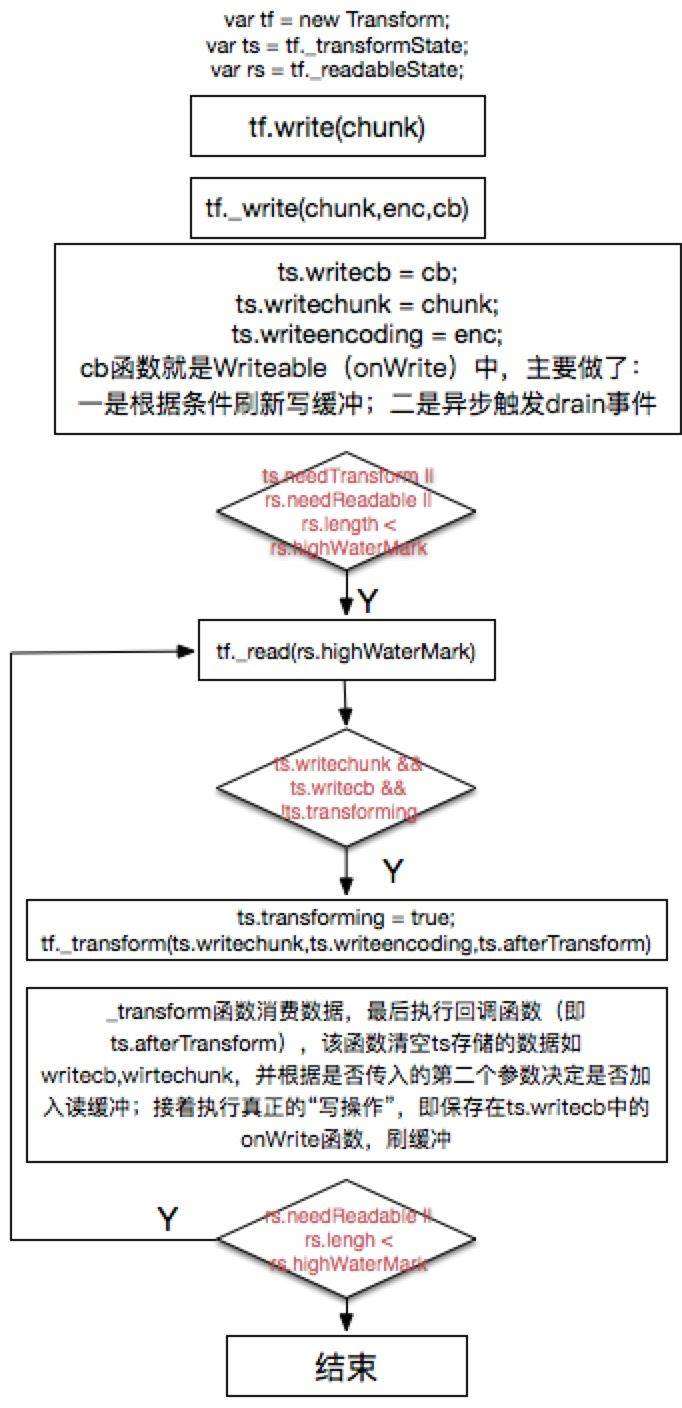
Transform的实例transform拥有transormState和readableState属性,保存了相关属性,如tranform状态信息、回调函数存储和编码等。transform作为消费者,会在其write函数中消费数据,在node中的Stream文中介绍了write函数的实现细节,通过内部调用_write函数实现数据的写入。而在Transform中_write函数已经重写:
1.保存transform收到的chunk数据、编码和函数(执行刷新写缓冲)
2.在一定条件下执行_read函数(当状态为非转换下,只要读缓冲大小未超过设定的大小,则执行_read)
如果一切顺利,readable的数据会顺利执行transform的**write->_write->_read**,那么原本负责填充读缓冲的_read在Transform中发生了哪些改变呢?
Transform.prototype._read = function(n) {
var ts = this._transformState;
if (ts.writechunk !== null && ts.writecb && !ts.transforming) {
ts.transforming = true;
this._transform(ts.writechunk, ts.writeencoding, ts.afterTransform);
} else {
// mark that we need a transform, so that any data that comes in
// will get processed, now that we've asked for it.
ts.needTransform = true;
}
};
可见,_read的实现非常简单,根据条件选择执行_transform函数。需要注意的是_read的参数n并未有使用,因为是否插入数据至读缓冲是由开发者在_transform中来决定。相信大家对_transform函数并不陌生,node规定Transform实例必须提供_transform函数,而该函数正是在_read中调用。
_transform有三个参数,第一个为待处理的chunk数据,第二个为编码,第三个为回调函数。前两个参数很好理解,我们可以在_transform中尽情的处理数据,最后调用回调函数完成处理。那么,这个回调函数究竟是什么? 它就是Transform架构图中的afterTransform函数,它有几个功能:
1.清空各种状态信息,如transformState对象的一些属性,用于下次处理数据使用
2.可选的保存处理结果至读缓冲区
3.刷新写缓冲区,执行下一阶段的数据流处理
可见,在afterTransform函数执行后,才基本宣告transform第一阶段的结束。为何是第一阶段呢?因为transform才完成了作为消费者(即Writeable)的作用,如果用户在_transform中传入了数据到写缓冲区,那么此时transform也同时是一个生产者,提供数据让后面的消费者消费数据,这就涉及到了Transform使用上的问题。
Transform的生产消费实例
const stream = require('stream')
var c = 0;
const readable = stream.Readable({
highWaterMark: 2,
read: function () {
var data = c < 26 ? String.fromCharCode(c++ + 97) : null;
console.log('push', data);
this.push(data);
}
})
const transform = stream.Transform({
highWaterMark: 2,
transform: function (buf, enc, next) {
console.log('transform', buf.toString());
next(null, buf);
}
})
readable.pipe(transform);
示例代码很简单,创建了一个可读流,向消费者提供a-z的小写字母;创建了一个转换流,在_transform函数中针对数据并不做处理仅作打点输出,并向回调函数传递数据至读缓冲区。我们的目的是通过transform输出26个小写字母,但是当前程序执行的结果并不让人满意:
执行结果:
push a
push b
transform a
push c
transform b
push d
push e
push f
tranform仅仅处理到字母b,readable也仅仅提供了a-f的数据便戛然而止,这是为何?
这一切都归结于transform对象。认真读过上文后我们知道,所有的Transform实例同时有两个缓冲区,其中写缓冲区用来接收生产者的数据进行转换操作,读缓冲区则缓存数据给消费者使用。而在当前的实现中,transform._transform函数输出了待处理数据,同时执行next(null, buf);。该函数上文已有分析,即afterTransform函数,第一个参数为Error实例,第二个则为存入读缓冲区的数据。在本例中,执行完_transform后将处理后的数据存入读缓冲区,等待后面的消费者消费读缓冲区的数据。可是,transform后面没有消费者了,因此transform在处理完字母b存入读缓冲区后,读缓冲区已经满了(设定highWaterMark为2,即读写缓冲区的最大值均为2字节)。当字母c、d也执行到tranform._write后,由于不满足执行transform._read的条件无法执行transform._transform函数,更无法执行afterTransform函数,导致无法刷新写缓冲区的数据,造成字母c、d贮存在写缓冲区。而字母e、f则由于transform的写缓冲区满(transform.write()返回false),只有存储在readable的读缓冲区中,等待消费。这就造成了死循环,readable和transform所有的缓冲区都满了,流也就停止了。
解决这个问题的方法很简单,有两种不同方案:
1.transform的读缓冲区保持为空
2.增加消费者消费transform的读缓冲区
其实本质上都是让transform的读缓冲区得到消耗。
第一种方案:
保证transform的读缓冲区为空:
const transform = stream.Transform({
highWaterMark: 2,
transform: function (buf, enc, next) {
console.log('transform', buf.toString())
next(null, null)
}
})
只需向next函数传入null即可,这样transform消费完数据后即宣告数据处理结束,读缓冲区始终为空。
第二种方案:
添加消费者:
const transform = stream.Transform({
highWaterMark: 2,
transform: function (buf, enc, next) {
console.log('transform', buf.toString())
next(null, buf)
}
})
readable.pipe(transform).pipe(process.stdout);
transform实现不变,只是添加了消费者process.stdout。这样也同时保证了transform的读缓冲区处于可添加状态,也给了afterTransform函数刷新写缓冲区的机会,开启新的数据处理流程。
through2的实现
through2的重头戏在于Transform流,使用through2的API可方便的创建一个Transform实例,完成数据流的处理。
function through2 (construct) {
return function (options, transform, flush) {
if (typeof options == 'function') {
flush = transform
transform = options
options = {}
}
if (typeof transform != 'function')
transform = noop
if (typeof flush != 'function')
flush = null
return construct(options, transform, flush)
}
}
module.exports = through2(function (options, transform, flush) {
var t2 = new DestroyableTransform(options)
t2._transform = transform
if (flush)
t2._flush = flush
return t2
})
可见,through2模块仅仅是封装了Transform的构造函数,并封装了更为易用的objectMode模式。之所以建议使用through2创建Transform对象,不仅仅是因为其提供了方便的API,更主要的是为了兼容性。Transform对象是属于Stream2.0的特性,早先版本的node并没有实现,而通过through2创建的Transform实例在之前版本的node下仍可正常使用,这是由于through2并未引用node默认提供的stream模块,而是使用社区中较为流行的“readable-stream”模块。
总结
本文旨在深入through2中的使用的Transform流进行探究,并作为上一篇文章node中的stream的回顾和应用。通过文末简单的示例了解Transform在开发中可能出现的问题,学会随意切换Transform的生产者和消费者的身份,更好的指导实际开发。
以上所述是小编给大家介绍的node之Transform ,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
nodejs npm install全局安装和本地安装的区别
npm的包安装分为本地安装(local).全局安装(global)两种,从敲的命令行来看,差别只是有没有-g而已,比如: 复制代码 代码如下: npm install grunt # 本地安装npm install -g grunt-cli # 全局安装 下面分别解释. 1. npm install xxx -g 时, 模块将被下载安装到[全局目录]中. [全局目录]通过 npm config set prefix "目录路径" 来设置. 通过 npm config get prefi
-

NodeJS学习笔记之Http模块
一,开篇分析 首先"Http"这个概念大家应该比较熟悉了,它不是基于特定语言的,是一个通用的应用层协议,不同语言有不同的实现细节,但是万变不离其宗,思想是相同的, NodeJS作为一个宿主运行环境,以JavaScript为宿主语言,它也有自己实现的一套标准,这篇文章我们就一起来学习一下 "Http模块" .但是作为前提来说, 希望大家可以先阅读一下官网提供的api,有一个前置了解,这样就方便多了,以下是Http部分的api概览: 复制代码 代码如下: HTTP
-
nodejs中exports与module.exports的区别详细介绍
你肯定非常熟悉nodejs模块中的exports对象,你可以用它创建你的模块.例如:(假设这是rocker.js文件) 复制代码 代码如下: exports.name = function() { console.log('My name is Lemmy Kilmister'); }; 在另一个文件中你这样引用 复制代码 代码如下: var rocker = require('./rocker.js'); rocker.name(); // 'My name is Lemmy Kilmiste
-
跟我学Nodejs(一)--- Node.js简介及安装开发环境
学习资料 1.深入浅出Node.js 2.Node.js开发指南 简介(只捡了我觉得重要的) Node.js是让Javascript脱离浏览器运行在服务器的一个平台,不是语言: Node.js采用的Javascript引擎是来自Google Chrome的V8:运行在浏览器外不用考虑头疼的Javascript兼容性问题 采用单线程.异步IO与事件驱动的设计来实现高并发(异步事件也在一定程度上增加了开发和调试的难度): Node.js内建一个HTTP服务器,所以对于网站开发来说是一个好消息:
-
nodejs开发环境配置与使用
先说下nodejs这个哦,有人以为它是一种语言,其实不是,它是一个平台,一个建立在google的V8引擎上的js运行平台,就是解析js,并提供自己 的一些API给用户调用.从目前的情况来看,这个发展情况还算好,明天都有好多的前端后台工程师在加入,连一些大神也在关注甚至写博客,昨晚我还看见一篇 文章写道一个外国的网站写了将近90搞nodejs的web插件,这个真牛啊!那学习中国东东对于我们来说最直接的能带来什么利益呢:前端人员由于熟悉 js那么可以基本简单学习下linux就可以上手了,那后台工程师
-
NodeJS学习笔记之FS文件模块
一,开篇分析 文件系统模块是一个简单包装的标准 POSIX 文件 I/O 操作方法集.可以通过调用 require("fs") 来获取该模块.文件系统模块中的所有方法均有异步和同步版本. (1),文件系统模块中的异步方法需要一个完成时的回调函数作为最后一个传入形参. (2),回调函数的构成由调用的异步方法所决定,通常情况下回调函数的第一个形参为返回的错误信息. (3),如果异步操作执行正确并返回,该错误形参则为null或者undefined.如果使用的是同步版本的操作方法,一旦出现错误
-
Node.js实战 建立简单的Web服务器
前面一章,我们介绍了Node.js这个面向互联网服务的JavaScript服务器平台,同时Node.js的运行环境已经搭建起来,并通过两段HelloWorld程序验证了Node.js的基本功能.本章我们同样通过实战的演练,利用Node.js建立一个简单的Web服务器. 如果你熟悉.NET或其他类似平台的Web开发,你可能会像,建立一个Web服务器有什么,在Visual Studio中建立一个Web工程,点击运行即可.事实的确是这样,但请不要忘记,这样的代价是,比如果说,你是用.NET开发Web应
-
一行命令搞定node.js 版本升级
node有一个模块叫n(这名字可够短的...),是专门用来管理node.js的版本的. 首先安装n模块: npm install -g n 第二步: 升级node.js到最新稳定版 n stable 是不是很简单?! n后面也可以跟随版本号比如: n v0.10.26 或 n 0.10.26 就这么简单,这可怎么办??!! 另外分享几个npm的常用命令 npm -v #显示版本,检查npm 是否正确安装. npm install express #安装express模块 npm install
-
windows系统下简单nodejs安装及环境配置
相信对于很多关注javascript发展的同学来说,nodejs已经不是一个陌生的词眼.有关nodejs的相关资料网上已经铺天盖地.由于它的高并发特性,造就了其特殊的应用地位. 国内目前关注最高,维护最好的一个关于nodejs的网站应该是http://www.cnodejs.org/ 这里不想谈太多的nodejs的相关信息.只说一下,windows系统下简单nodejs环境配置. 第一步:下载安装文件 下载地址:官网http://www.nodejs.org/download/ 这里用的是
-
Node.js(安装,启动,测试)
概念 Node.js 是构建在Chrome javascript runtime之上的平台,能够很容易的构建快速的,可伸缩性的网络应用程序.Node.js使用事件驱动,非阻塞I/O 模式,这使它能够更轻量,高效且完美的适用于运行在分布式设备之间的数据密集型实时应用程序. 安装 这里主要介绍基于windows平台上最简单方便的安装方式,我们首先直接访问node.js官方网站http://www.nodejs.org/,直接点击Install按钮开始下载安装. 点击Run按钮开始运行 继续点击Nex