pytorch中如何使用DataLoader对数据集进行批处理的方法
最近搞了搞minist手写数据集的神经网络搭建,一个数据集里面很多个数据,不能一次喂入,所以需要分成一小块一小块喂入搭建好的网络。
pytorch中有很方便的dataloader函数来方便我们进行批处理,做了简单的例子,过程很简单,就像把大象装进冰箱里一共需要几步?
第一步:打开冰箱门。
我们要创建torch能够识别的数据集类型(pytorch中也有很多现成的数据集类型,以后再说)。
首先我们建立两个向量X和Y,一个作为输入的数据,一个作为正确的结果:

随后我们需要把X和Y组成一个完整的数据集,并转化为pytorch能识别的数据集类型:

我们来看一下这些数据的数据类型:

可以看出我们把X和Y通过Data.TensorDataset() 这个函数拼装成了一个数据集,数据集的类型是【TensorDataset】。
好了,第一步结束了,冰箱门打开了。
第二步:把大象装进去。
就是把上一步做成的数据集放入Data.DataLoader中,可以生成一个迭代器,从而我们可以方便的进行批处理。

DataLoader中也有很多其他参数:
- dataset:Dataset类型,从其中加载数据
- batch_size:int,可选。每个batch加载多少样本
- shuffle:bool,可选。为True时表示每个epoch都对数据进行洗牌
- sampler:Sampler,可选。从数据集中采样样本的方法。
- num_workers:int,可选。加载数据时使用多少子进程。默认值为0,表示在主进程中加载数据。
- collate_fn:callable,可选。
- pin_memory:bool,可选
- drop_last:bool,可选。True表示如果最后剩下不完全的batch,丢弃。False表示不丢弃。
好了,第二步结束了,大象装进去了。
第三步:把冰箱门关上。
好啦,现在我们就可以愉快的用我们上面定义好的迭代器进行训练啦。
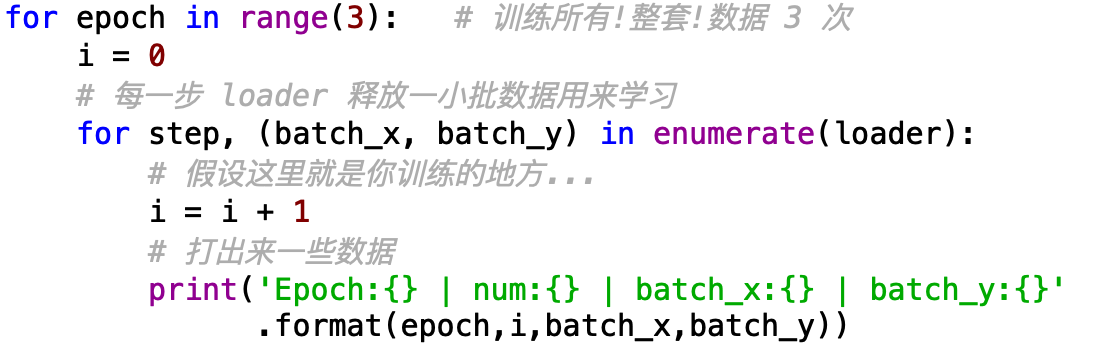
在这里我们利用print来模拟我们的训练过程,即我们在这里对搭建好的网络进行喂入。

输出的结果是:
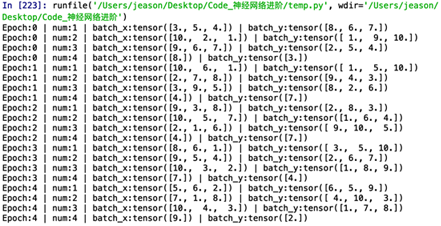
可以看到,我们一共训练了所有的数据训练了5次。数据中一共10组,我们设置的mini-batch是3,即每一次我们训练网络的时候喂入3组数据,到了最后一次我们只有1组数据了,比mini-batch小,我们就仅输出这一个。
此外,还可以利用python中的enumerate(),是对所有可以迭代的数据类型(含有很多东西的list等等)进行取操作的函数,用法如下:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

详解PyTorch批训练及优化器比较
一.PyTorch批训练 1. 概述 PyTorch提供了一种将数据包装起来进行批训练的工具--DataLoader.使用的时候,只需要将我们的数据首先转换为torch的tensor形式,再转换成torch可以识别的Dataset格式,然后将Dataset放入DataLoader中就可以啦. import torch import torch.utils.data as Data torch.manual_seed(1) # 设定随机数种子 BATCH_SIZE = 5 x = torch.li
-
使用pytorch进行图像的顺序读取方法
产生此次实验的原因:当我使用pytorch进行神经网络的训练时,需要每次向CNN传入一组图像,并且这些图片的存放位置是在两个文件夹中: A文件夹:图片1a,图片2a,图片3a--图片1000a B文件夹:图片1b, 图片2b,图片3b--图片1000b 所以在每个循环里,我都希望能从A中取出图片Na,同时从B文件夹中取出对应的图片Nb. 测试一:通过pytorch官方文档中的dataloader搭配python中的迭代器iterator dataset = dset.ImageFolder( r
-
pytorch 把MNIST数据集转换成图片和txt的方法
本文介绍了pytorch 把MNIST数据集转换成图片和txt的方法,分享给大家,具体如下: 1.下载Mnist 数据集 import os # third-party library import torch import torch.nn as nn from torch.autograd import Variable import torch.utils.data as Data import torchvision import matplotlib.pyplot as plt # t
-
PyTorch上搭建简单神经网络实现回归和分类的示例
本文介绍了PyTorch上搭建简单神经网络实现回归和分类的示例,分享给大家,具体如下: 一.PyTorch入门 1. 安装方法 登录PyTorch官网,http://pytorch.org,可以看到以下界面: 按上图的选项选择后即可得到Linux下conda指令: conda install pytorch torchvision -c soumith 目前PyTorch仅支持MacOS和Linux,暂不支持Windows.安装 PyTorch 会安装两个模块,一个是torch,一个 torch
-
WIn10+Anaconda环境下安装PyTorch(避坑指南)
这些天安装 PyTorch,遇到了一些坑,特此总结一下,以免忘记.分享给大家. 首先,安装环境是:操作系统 Win10,已经预先暗转了 Anaconda. 1. 为 PyTorch 创建虚拟环境 关于 Anaconda 的安装步骤这里就忽略不讲了,Win10 下安装 Anaconda 非常简单. 安装 Anaconda 完毕后,我们在安装 PyTorch 之前最好先创建一个 pytorch 的虚拟环境.之所以创建虚拟环境是因为 Python 为不同的项目需求创建不同的虚拟环境非常常见.在实际项目
-
pytorch中tensor的合并与截取方法
合并: torch.cat(inputs=(a, b), dimension=1) e.g. x = torch.cat((x,y), 0) 沿x轴合并 截取: x[:, 2:4] 以上这篇pytorch中tensor的合并与截取方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
Pytorch入门之mnist分类实例
本文实例为大家分享了Pytorch入门之mnist分类的具体代码,供大家参考,具体内容如下 #!/usr/bin/env python # -*- coding: utf-8 -*- __author__ = 'denny' __time__ = '2017-9-9 9:03' import torch import torchvision from torch.autograd import Variable import torch.utils.data.dataloader as Data
-
pytorch中如何使用DataLoader对数据集进行批处理的方法
最近搞了搞minist手写数据集的神经网络搭建,一个数据集里面很多个数据,不能一次喂入,所以需要分成一小块一小块喂入搭建好的网络. pytorch中有很方便的dataloader函数来方便我们进行批处理,做了简单的例子,过程很简单,就像把大象装进冰箱里一共需要几步? 第一步:打开冰箱门. 我们要创建torch能够识别的数据集类型(pytorch中也有很多现成的数据集类型,以后再说). 首先我们建立两个向量X和Y,一个作为输入的数据,一个作为正确的结果: 随后我们需要把X和Y组成一个完整的数据集,
-
pytorch加载自己的图片数据集的2种方法详解
目录 ImageFolder 加载数据集 使用pytorch提供的Dataset类创建自己的数据集. Dataset加载数据集 总结 pytorch加载图片数据集有两种方法. 1.ImageFolder 适合于分类数据集,并且每一个类别的图片在同一个文件夹, ImageFolder加载的数据集, 训练数据为文件件下的图片, 训练标签是对应的文件夹, 每个文件夹为一个类别 导入ImageFolder()包 from torchvision.datasets import ImageFolder 在
-
pytorch中DataLoader()过程中遇到的一些问题
如下所示: RuntimeError: stack expects each tensor to be equal size, but got [3, 60, 32] at entry 0 and [3, 54, 32] at entry 2 train_dataset = datasets.ImageFolder( traindir, transforms.Compose([ transforms.Resize((224)) ### 原因是 transforms.Resize() 的参数设置问
-
Pytorch使用技巧之Dataloader中的collate_fn参数详析
以MNIST为例 from torchvision import datasets mnist = datasets.MNIST(root='./data/', train=True, download=True) print(mnist[0]) 结果 (<PIL.Image.Image image mode=L size=28x28 at 0x196E3F1D898>, 5) MINIST数据集的dataset是由一张图片和一个label组成的元组 dataloader = torch.ut
-
PyTorch中torch.utils.data.DataLoader简单介绍与使用方法
目录 一.torch.utils.data.DataLoader 简介 二.实例 参考链接 总结 一.torch.utils.data.DataLoader 简介 作用:torch.utils.data.DataLoader 主要是对数据进行 batch 的划分. 数据加载器,结合了数据集和取样器,并且可以提供多个线程处理数据集. 在训练模型时使用到此函数,用来 把训练数据分成多个小组 ,此函数 每次抛出一组数据 .直至把所有的数据都抛出.就是做一个数据的初始化. 好处: 使用DataLoade
-
pytorch中dataloader 的sampler 参数详解
目录 1. dataloader() 初始化函数 2. shuffle 与sample 之间的关系 3. sample 的定义方法 3.1 sampler 参数的使用 4. batch 生成过程 1. dataloader() 初始化函数 def __init__(self, dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_mem
-
Pytorch中使用ImageFolder读取数据集时忽略特定文件
目录 一.使用ImageFolder读取数据集时忽略特定文件 二.ImageFolder只读取部分类别文件夹 一.使用ImageFolder读取数据集时忽略特定文件 如果事先知道需要忽略哪些文件,当然直接从数据集里删除就行了.但如果需要在程序运行时动态确认,或者筛选规则比较复杂,人工不好做,就需要让ImageFolder在读取时使用自定义的筛选规则. ImageFolder有一个可选参数为is_valid_file,参数类型为可调用的函数,该函数传入一个str参数,返回一个bool值.当返回值为
-
pytorch中的自定义数据处理详解
pytorch在数据中采用Dataset的数据保存方式,需要继承data.Dataset类,如果需要自己处理数据的话,需要实现两个基本方法. :.getitem:返回一条数据或者一个样本,obj[index] = obj.getitem(index). :.len:返回样本的数量 . len(obj) = obj.len(). Dataset 在data里,调用的时候使用 from torch.utils import data import os from PIL import Image 数
-
使用 PyTorch 实现 MLP 并在 MNIST 数据集上验证方式
简介 这是深度学习课程的第一个实验,主要目的就是熟悉 Pytorch 框架.MLP 是多层感知器,我这次实现的是四层感知器,代码和思路参考了网上的很多文章.个人认为,感知器的代码大同小异,尤其是用 Pytorch 实现,除了层数和参数外,代码都很相似. Pytorch 写神经网络的主要步骤主要有以下几步: 1 构建网络结构 2 加载数据集 3 训练神经网络(包括优化器的选择和 Loss 的计算) 4 测试神经网络 下面将从这四个方面介绍 Pytorch 搭建 MLP 的过程. 项目代码地址:la
-
在pytorch中动态调整优化器的学习率方式
在深度学习中,经常需要动态调整学习率,以达到更好地训练效果,本文纪录在pytorch中的实现方法,其优化器实例为SGD优化器,其他如Adam优化器同样适用. 一般来说,在以SGD优化器作为基本优化器,然后根据epoch实现学习率指数下降,代码如下: step = [10,20,30,40] base_lr = 1e-4 sgd_opt = torch.optim.SGD(model.parameters(), lr=base_lr, nesterov=True, momentum=0.9) de