django项目用higcharts统计最近七天文章点击量
下载higcharts插件放在static文件夹下
前端引入
<script src="/static/highcharts/highcharts.js"></script> <script src="/static/highcharts/modules/exporting.js"></script> <script src="/static/highcharts/modules/oldie.js"></script> <script src="/static/highcharts/highcharts-zh_CN.js"></script>
定义在页面中的位置
<div id="container" style="min-width:400px;height:400px"></div>
前端js
<script>
var chart = Highcharts.chart('container', {
chart: {
type: 'line'
},
title: {
text: '日点击量和点赞量统计'
},
subtitle: {
text: '数据来源: terroristhouse.com'
},
xAxis: {
categories: {{ list_week_day|safe }}
},
yAxis: {
title: {
text: '数量 (次)'
}
},
plotOptions: {
line: {
dataLabels: {
// 开启数据标签
enabled: true
},
// 关闭鼠标跟踪,对应的提示框、点击事件会失效
enableMouseTracking: false
}
},
series: [{
name: '点击量',
data:{{ clicknum_list|safe }}
}, {
name: '点赞量',
data: {{ praise_num_list|safe }}
}]
});
</script>
路由
# 点击量统计
re_path('article/click/', article.click,name='article/click/'),
后台方法
from blog.utils import function
# 点击量
def click(request):
recent_seven_days = function.recent_seven_days()
list_week_day = recent_seven_days[::-1] # 进行倒序
clicknum_list = []
praise_num_list = []
# print(list_week_day)
for v in list_week_day:
click_num_obj = Praise.objects.filter(click_addtime=v,click_sort=1).aggregate(clicknum=Count('click_sort'))
praise_num_obj = Praise.objects.filter(click_addtime=v,click_sort=0).aggregate(praise_num=Count('click_sort'))
# print(click_num_obj['clicknum'],praise_num_obj['praise_num'])
clicknum = int(click_num_obj['clicknum']) if (click_num_obj['clicknum'] is not None) else 0
praise_num = int(praise_num_obj['praise_num']) if (praise_num_obj['praise_num'] is not None) else 0
clicknum_list.append(clicknum)
praise_num_list.append(praise_num)
# print(clicknum_list)
# data=[{
# 'name': '点击量',
# 'data': clicknum_list
# }, {
# 'name': '点赞量',
# 'data': praise_num_list
# }]
# num= [ '20190624', '20190625', '20190626', '20190627', '20190628', '20190629', '20190630']
return render(request,'article/click.html',locals())
应用目录下创建untils文件夹,并在其下创建function.py文件,用来获取最近七天日期
# 七天日期
def recent_seven_days():# 通过for 循环得到天数,如果想得到两周的时间,只需要把8改成15就可以了。
import datetime
d = datetime.datetime.now()#2019-6-28 9:25:43.843164
lists = []
for i in range(1,8):#i:1-7
oneday = datetime.timedelta(days=i) #1 day, 0:00:00 2 days, 0:00:00 ... 7 days, 0:00:00
day = d - oneday#2019-06-27 11:32:10.186535 2019-06-26 11:32:10.186535 ... 2019-06-21 11:32:10.186535
date_to = datetime.datetime(day.year, day.month, day.day)#2019-06-27 00:00:00 2019-06-26 00:00:00 ... 2019-06-21 00:00:00
lists.append(str(date_to)[0:10])#2019-06-27 2019-06-26 ... 2019-06-21
return lists
页面效果
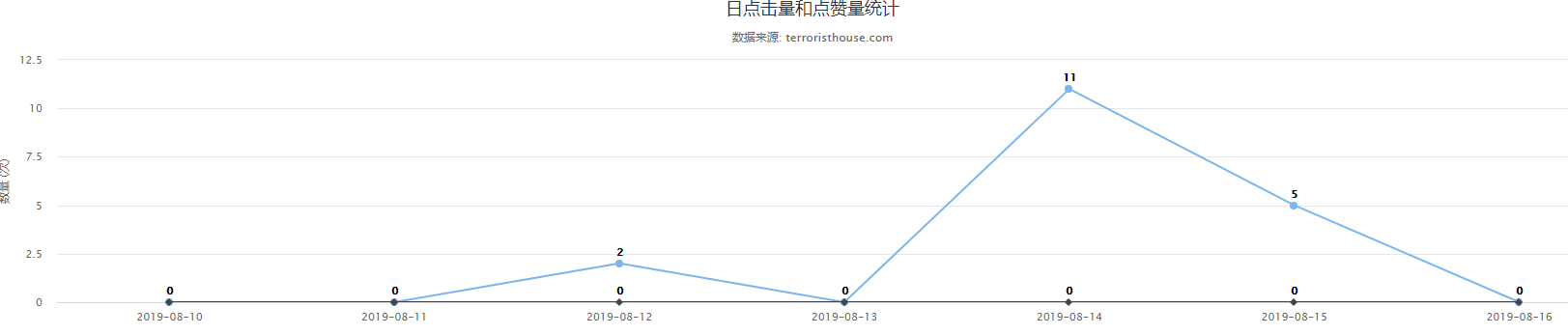
总结
以上所述是小编给大家介绍的django项目用higcharts统计最近七天文章点击量,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的!
相关推荐
-
利用Celery实现Django博客PV统计功能详解
前言 前几天给网站的文章增加了pv统计,之前只有uv统计.之前没加pv统计是觉得每个用户每访问一次文章,我都需要做一次数据库写操作实在是有损性能,毕竟从用户在the5fire博客的的一次访问来看,只需要从数据库里拿到对应的文章(通常情况下是从缓存中拿),然后返回给浏览器.写操作无意义.之前的uv,也是针对每个用户24小时内只会有一次写操作. 不过话说回来,就对于the5fire博客这么个小站点来说,就算每次访问我写十几次数据库都没啥影响,毕竟量小的可怜.但是咱们码农不是得有颗抗亿级流量的心嘛.
-
使用django的ORM框架按月统计近一年内的数据方法
如下所示: # 计算时间 time = datetime.datetime.now() - relativedelta(years=1) # 获取近一年数据 one_year_data = Data.objects.filter(create_time__gte=time_ago) # 分组统计每个月的数据 count_res = one_year_data\ .annotate(year=ExtractYear('create_time'),month=ExtractMonth('create
-
django项目用higcharts统计最近七天文章点击量
下载higcharts插件放在static文件夹下 前端引入 <script src="/static/highcharts/highcharts.js"></script> <script src="/static/highcharts/modules/exporting.js"></script> <script src="/static/highcharts/modules/oldie.js&qu
-
宝塔面板成功部署Django项目流程(图文)
上线 Django 项目记录,超简单,避免无意义的踩坑! 第一步:安装python管理器 在宝塔在线面板安装" python项目管理器 " 第二步:安装适配python版本 因为服务器 centos7 系统默认的 python 版本是 2.7 而我们项目是基于最新版 Django 来开发的,本地环境是 python2.7 的,为了尽量保证环境的相似,避免踩无意义的坑. 第三步:导出项目包到requirments.txt python 的安装时间比较长,所以先做一些别的工作,同时在 在本
-
Centos8下django项目部署 nginx+uwsgi的教程
1.虚拟环境virtualenv安装 1.安装virtualenv pip3 install virtualenv 2.创建目录,把项目文件传过来 mkdir My cd My 3.创建独立运行环境-命名 virtualenv --no-site-packages --python=python3 venv1 #创建独立的环境,并且指定解释器是python3 4.进入虚拟环境 source venv1/bin/activate #此时进入虚拟环境(venv1) 5.在虚拟环境中安装第
-
如何用Anaconda搭建虚拟环境并创建Django项目
一.创建虚拟环境 (1)打开cmd命令窗口 (2)创建虚拟环境 conda create -n mydjango_env (3)查看虚拟环境 conda env list *号表示当前使用的环境 (4)激活创建的虚拟环境 activate mydjango_env 二.安装Django 在新环境激活的状态下安装Django conda install django 三.创建项目 (1)进入需要创建项目的文件目录 (2)创建项目 django-admin startproject 项目名 此时Dj
-

Django 项目配置拆分独立的实现
目录 一.创建配置目录 二.创建基础配置文件 三.创建各个环境的配置 四.调整settings.py 五.程序使用 六.目录结构 Django 项目中,我们默认的配置是都在 settings.py 文件里面的,但是实际本地调试和线上应该是需要两个环境的,我们现在来拆分下配置.将配置拆分开来. 一.创建配置目录 我们在项目的跟路径下创建一个config 目录 二.创建基础配置文件 在config 配置下 创建 base.py 文件,然后将原来 settings.py 文件内容拷贝过来. 三.创建各
-
Django项目配置连接多个数据库的方法记录
一个APP对应一个默认数据库,若连接其他数据库用".using()" Author.objects.using('db02').all() 1.在项目settings中增加数据库配置 # settings.py DATABASES = { 'default': { 'ENGINE': 'django.db.backends.oracle', 'NAME': 'orcl19c', 'USER': "username01", 'PASSWORD': "pass
-
Django项目定期自动清除过期session的2种方法实例
目录 非自动方法 第一种方法通用方法(利用APScheduler定时清除) 安装插件 添加定时任务 添加如下代码在wsgi.py 运行效果 利用宝塔面板(baota)的计划面板(shell脚本) 进入shell编辑面 编写shell脚本 执行脚本 运行效果 总结 非自动方法 python manage.py clearsessions 第一种方法通用方法(利用APScheduler定时清除) 安装插件 pip install apscheduler 添加定时任务 找到项目同名的app文件夹中的w
-
对Django项目中的ORM映射与模糊查询的使用详解
ORM映射 什么是ORM映射?在笔者认为就是对SQL语句的封装,所写语句与SQL对应语句含义相同,使开发更加简单方便,不过也是存在弊端的,使程序运行效率下降.例如: UserInfo.objects.get(id=2) 等于 select * from user_userinfo where id=2 修改管理器(models.py) 导入新的包:from django.db import models 进行模糊查询 开始进行查找前我们先来认识filter()方法. 这是一个过滤器方法用于过滤掉
-
ubuntu16.04在python3 下创建Django项目并运行的操作方法
第一步:创建django项目 打开终端,切换到期望所写项目的地址:cd python3_django_projects; 输入命令:django-admin.py startproject Hello;(即创建好了一个名为Hello的项目) 第二步:启动项目 进入Hello目录:cd Hello; 输入命令python manage.py runserver; 或 python3 manage.py runserver;(自己对应python版本) 第三步:在浏览器中输入http://127.0