Python输出\u编码将其转换成中文的实例
爬取了下小猪短租的网站出租房信息但是输出的时候是这种:

百度了下。python2.7在window上的编码确实是个坑
解决如下
如果是个字典的话要先将其转成字符串 导入json库
然后 这么输出(json.dumps(data).decode("unicode-escape"))
整个代码demo
# -*- coding: UTF-8 -*-
#小猪短租爬取
import requests
from bs4 import BeautifulSoup
import json
def get_xinxi(i):
url = 'http://cd.xiaozhu.com/search-duanzufang-p%d-0/' %i
html = requests.get(url)
soup = BeautifulSoup(html.content)
#获取地址
dizhis=soup.select(' div > a > span')
#获取价格
prices = soup.select(' span.result_price')
#获取简单信息
ems = soup.select(' div > em')
datas =[]
for dizhi,price,em in zip(dizhis,prices,ems):
data={
'价格':price.get_text(),
'信息':em.get_text().replace('\n','').replace(' ',''),
'地址':dizhi.get_text()
}
print(json.dumps(data).decode("unicode-escape"))
i=1
while(i<12):
get_xinxi(i)
i=i+1
爬取了12页的信息
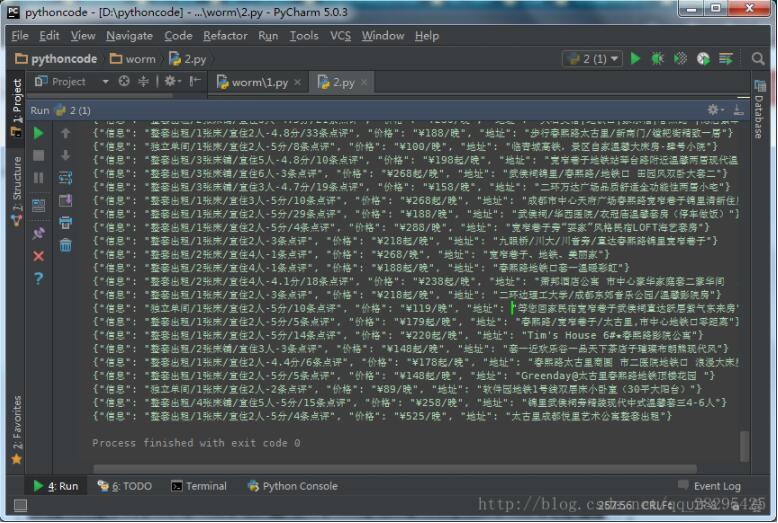
小结:
压注意的是
创建soup
soup = BeautifulSoup(html.content)
多个值的for赋值
for dizhi,price,em in zip(dizhis,prices,ems):
字典的输出编码问题
json.dumps(data).decode("unicode-escape")
如果想获取每个个详细信息可以获取其href属性值
#page_list > ul > li:nth-of-type(1) > a
然后获取其属性值get(‘href')获取每个的详情信息在解析页面获取想要的信息加在data字典中
以上这篇Python输出\u编码将其转换成中文的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python实现unicode转中文及转换默认编码的方法
本文实例讲述了python实现unicode转中文及转换默认编码的方法.分享给大家供大家参考,具体如下: 一.在爬虫抓取网页信息时常需要将类似"\u4eba\u751f\u82e6\u77ed\uff0cpy\u662f\u5cb8"转换为中文,实际上这是unicode的中文编码.可用以下方法转换: 1. >>> s = u'\u4eba\u751f\u82e6\u77ed\uff0cpy\u662f\u5cb8' >>> print s 人生苦短,
-
Python3编码问题 Unicode utf-8 bytes互转方法
为什么需要本文,因为在对接某些很老的接口的时候,需要传递过去的是16进制的hex字符串,并且要求对传的字符串做编码,这里就介绍了utf-8 Unicode bytes 等等. #英文使用utf-8 转换成16进制hex字符串的方法 newstr = 'asd' b_str = bytes(newstr,encoding='utf-8') print(b_str) hex_str = b_str.hex() #将bytes类型转换成16进制的hex字符串 print(hex_str) #字节码转1
-
Python 转换文本编码实现解析
最近在做周报的时候,需要把csv文本中的数据提取出来制作表格后生产图表. 在获取csv文本内容的时候,基本上都是用with open(filename, encoding ='UTF-8') as f:来打开csv文本,但是实际使用过程中发现有些csv文本并不是utf-8格式,从而导致程序在run的过程中报错,每次都需要手动去把该文本文件的编码格式修改成utf-8,再次来run该程序,所以想说:直接在程序中判断并修改文本编码. 基本思路:先查找该文本是否是utf-8的编码,如果不是则修改为utf
-
解决Python中pandas读取*.csv文件出现编码问题
1.问题 在使用Python中pandas读取csv文件时,由于文件编码格式出现以下问题: Traceback (most recent call last): File "pandas\_libs\parsers.pyx", line 1134, in pandas._libs.parsers.TextReader._convert_tokens File "pandas\_libs\parsers.pyx", line 1240, in pandas._libs
-
python3 中文乱码与默认编码格式设定方法
python默认编码格式是utf-8.在python2.7中,可以通过sys.setdefaultencoding('gbk')设定默认编码格式,而在python3.3中sys.setdefaultencoding()这个函数已经没有了.在python3.3中该如何设置内置的默认编码格式啊!急求!!! (类似于"#coding:gbk"这种就不必来说了.能让import sys print(sys.getdefaultencoding())输出"gbk"的大神请进!
-

python中文编码与json中文输出问题详解
前言 python2.x版本的字符编码有时让人很头疼,遇到问题,网上方法可以解决错误,但对原理还是一知半解,本文主要介绍 python 中字符串处理的原理,附带解决 json 文件输出时,显示中文而非 unicode 问题.首先简要介绍字符串编码的历史,其次,讲解 python 对于字符串的处理,及编码的检测与转换,最后,介绍 python 爬虫采取的 json 数据存入文件时中文输出的问题. 参考书籍:Python网络爬虫从入门到实践 by唐松 在python 2或者3 ,字符串编码只有两类
-
python3编码问题汇总
这两天写了个监测网页的爬虫,作用是跟踪一个网页的变化,但运行了一晚出现了一个问题....希望大家不吝赐教! 我用的是python3,错误在对html response的decode时抛出,代码原样为: response = urllib.urlopen(dsturl) content = response.read().decode('utf-8') 抛出错误为 File "./unxingCrawler_p3.py", line 50, in getNewPhones content
-
Python输出\u编码将其转换成中文的实例
爬取了下小猪短租的网站出租房信息但是输出的时候是这种: 百度了下.python2.7在window上的编码确实是个坑 解决如下 如果是个字典的话要先将其转成字符串 导入json库 然后 这么输出(json.dumps(data).decode("unicode-escape")) 整个代码demo # -*- coding: UTF-8 -*- #小猪短租爬取 import requests from bs4 import BeautifulSoup import json def g
-
Python基于pandas实现json格式转换成dataframe的方法
本文实例讲述了Python基于pandas实现json格式转换成dataframe的方法.分享给大家供大家参考,具体如下: # -*- coding:utf-8 -*- #!python3 import re import json from bs4 import BeautifulSoup import pandas as pd import requests import os from pandas.io.json import json_normalize class image_str
-
Python3的unicode编码转换成中文的问题及解决方案
这篇文章主要介绍了Python3的unicode编码转换成中文的问题及解决方案,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 从别的地方搬过来的,担心以后不容易搜索到,就收集过来. 我当时面临的问题是要从C++发json代码出来,用python写了个server,然后返回给C++程序,结果收到的是: httpSvrDataCbUser: {"tranNO": "0808ad498670dc996", "d
-
Python深度学习之Keras模型转换成ONNX模型流程详解
目录 从Keras转换成PB模型 从PB模型转换成ONNX模型 改变现有的ONNX模型精度 部署ONNX 模型 总结 从Keras转换成PB模型 请注意,如果直接使用Keras2ONNX进行模型转换大概率会出现报错,这里笔者曾经进行过不同的尝试,最后都失败了. 所以笔者的推荐的情况是:首先将Keras模型转换为TensorFlow PB模型. 那么通过tf.keras.models.load_model()这个函数将模型进行加载,前提是你有一个基于h5格式或者hdf5格式的模型文件,最后再通过改
-
python使用PythonMagick将jpg图片转换成ico图片的方法
本文实例讲述了python使用PythonMagick将jpg图片转换成ico图片的方法.分享给大家供大家参考.具体分析如下: 这里使用到了PythonMagick模块,关于PythonMagick模块和ImageMagick的详细信息请参考:http://www.imagemagick.org/. 下面这段代码可以讲jpg图片转换成ico图标格式. # -*- coding: utf-8 -*- import PythonMagick img = PythonMagick.Image("c:/
-
python将时分秒转换成秒的实例
处理数据的时候遇到一个问题,从数据库里导出的数据是时分秒的格式:hh:mm:ss ,现在我需要把它转换成秒,方便计算. 原数据可能分两种情况,字段有可能是文本字符串类型的,也有可能是时间类型,他们的处理方法不一样,所以我们分开讨论. 1.字符串类型转换成秒 可以将其用 ':' 分隔开,分别得出时.分.秒,即可计算出秒数.所以我们定义如下函数: def str2sec(x): ''' 字符串时分秒转换成秒 ''' h, m, s = x.strip().split(':') #.split()函数
-
python如何把字符串类型list转换成list
这篇文章主要介绍了python如何吧字符串类型list转换成list,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 python读取了一个list是字符串形式的'[11.23,23.34]',想转换成list类型: 方式一: import ast str_list = "[11.23,23.34]" list_list = ast.literal_eval(str_list) print(type(list_list)) 得到结果为:
-
python 将视频 通过视频帧转换成时间实例
我就废话不多说了,还是直接看代码吧! def frames_to_timecode(framerate,frames): """ 视频 通过视频帧转换成时间 :param framerate: 视频帧率 :param frames: 当前视频帧数 :return:时间(00:00:01:01) """ return '{0:02d}:{1:02d}:{2:02d}:{3:02d}'.format(int(frames / (3600 * fram
-
python将dict中的unicode打印成中文实例
我就废话不多说了,大家还是直接看代码吧! import json a = {u'content': {u'address_detail': {u'province': u'\u5409\u6797\u7701', u'city': u'\u957f\u6625\u5e02', u'street_number': u'', u'district': u'', u'street': u'', u'city_code': 53}, u'point': {u'y': u'43.89833761', u'
-
php解析mht文件转换成html的实例
php解析mht文件,使用编辑器打开可以看到base64编码所以,mht是可以转换成html的. <?php /** * 针对Mht格式的文件进行解析 * 使用例子: * * function mhtmlParseBody($filename) { if (file_exists ( $filename )) { if (is_dir ( $filename )) return false; $filename = strtolower ( $filename ); if (strpos ( $