用python处理MS Word的实例讲解
使用python工具读写MS Word文件(docx与doc文件),主要利用了python-docx包。本文给出一些常用的操作,并完成一个样例,帮助大家快速入手。
安装
pyhton处理docx文件需要使用python-docx 包,可以利用pip工具很方便的安装,pip工具在python安装路径下的Scripts文件夹中
pip install python-docx
当然你也可以选择使用easy_install或者手动方式进行安装
写入文件内容
此处我们直接给出一个样例,根据自己的需要摘取有用的内容
#coding=utf-8
from docx import Document
from docx.shared import Pt
from docx.shared import Inches
from docx.oxml.ns import qn
#打开文档
document = Document()
#加入不同等级的标题
document.add_heading(u'MS WORD写入测试',0)
document.add_heading(u'一级标题',1)
document.add_heading(u'二级标题',2)
#添加文本
paragraph = document.add_paragraph(u'我们在做文本测试!')
#设置字号
run = paragraph.add_run(u'设置字号、')
run.font.size = Pt(24)
#设置字体
run = paragraph.add_run('Set Font,')
run.font.name = 'Consolas'
#设置中文字体
run = paragraph.add_run(u'设置中文字体、')
run.font.name=u'宋体'
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), u'宋体')
#设置斜体
run = paragraph.add_run(u'斜体、')
run.italic = True
#设置粗体
run = paragraph.add_run(u'粗体').bold = True
#增加引用
document.add_paragraph('Intense quote', style='Intense Quote')
#增加无序列表
document.add_paragraph(
u'无序列表元素1', style='List Bullet'
)
document.add_paragraph(
u'无序列表元素2', style='List Bullet'
)
#增加有序列表
document.add_paragraph(
u'有序列表元素1', style='List Number'
)
document.add_paragraph(
u'有序列表元素2', style='List Number'
)
#增加图像(此处用到图像image.bmp,请自行添加脚本所在目录中)
document.add_picture('image.bmp', width=Inches(1.25))
#增加表格
table = document.add_table(rows=1, cols=3)
hdr_cells = table.rows[0].cells
hdr_cells[0].text = 'Name'
hdr_cells[1].text = 'Id'
hdr_cells[2].text = 'Desc'
#再增加3行表格元素
for i in xrange(3):
row_cells = table.add_row().cells
row_cells[0].text = 'test'+str(i)
row_cells[1].text = str(i)
row_cells[2].text = 'desc'+str(i)
#增加分页
document.add_page_break()
#保存文件
document.save(u'测试.docx')
该段代码生成的文档样式如下

注:有一个问题没找到如何解决,即如何为表格设置边框线。如果您知道,还请能够指教。
读取文件内容
#coding=utf-8
from docx import Document
#打开文档
document = Document(u'测试.docx')
#读取每段资料
l = [ paragraph.text.encode('gb2312') for paragraph in document.paragraphs];
#输出并观察结果,也可以通过其他手段处理文本即可
for i in l:
print i
#读取表格材料,并输出结果
tables = [table for table in document.tables];
for table in tables:
for row in table.rows:
for cell in row.cells:
print cell.text.encode('gb2312'),'\t',
print
print '\n'
我们仍然使用刚才我们生成的文件,可以看到,输出的结果为
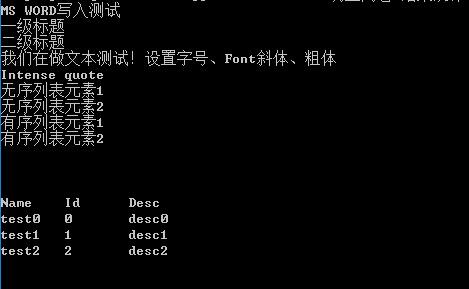
注意:此处我们使用gb2312编码方式读取,主要是保证中文的读写正确。一般情况下,使用的utf-8编码方式。另外,python-docx主要处理docx文件,在加载doc文件时,会出现问题,如果有大量doc文件,建议先将doc文件批量转换为docx文件,例如利用工具doc2doc
以上这篇用python处理MS Word的实例讲解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python实现在windows下操作word的方法
本文实例讲述了python实现在windows下操作word的方法.分享给大家供大家参考.具体实现方法如下: import win32com from win32com.client import Dispatch, constants w = win32com.client.Dispatch('Word.Application') # 或者使用下面的方法,使用启动独立的进程: # w = win32com.client.DispatchEx('Word.Application') # 后台运行
-

Python操作Word批量生成文章的方法
下面通过COM让Python与Word建立连接实现Python操作Word批量生成文章,具体介绍请看下文: 需要做一些会议记录.总共有多少呢?五个地点x7个月份x每月4篇=140篇.虽然不很重要,但是140篇记录完全雷同也不好.大体看了一下,此类的记录大致分为四段.于是决定每段提供四种选项,每段从四选项里随机选一项,拼凑成四段文字,存成一个文件.而且要打印出来,所以准备生成一个140页的Word文档,每页一篇. 需要用到win32com模块(下载链接: http://sourceforge.ne
-
Python读取word文本操作详解
本文研究的主要问题时Python读取word文本操作,分享了相关概念和实现代码,具体如下. 一,docx模块 Python可以利用python-docx模块处理word文档,处理方式是面向对象的.也就是说python-docx模块会把word文档,文档中的段落.文本.字体等都看做对象,对对象进行处理就是对word文档的内容处理. 二,相关概念 如果需要读取word文档中的文字(一般来说,程序也只需要认识word文档中的文字信息),需要先了解python-docx模块的几个概念. 1,Docume
-
Python实现批量读取word中表格信息的方法
本文实例讲述了Python实现批量读取word中表格信息的方法.分享给大家供大家参考.具体如下: 单位收集了很多word格式的调查表,领导需要收集表单里的信息,我就把所有调查表放一个文件里,写了个python小程序把所需的信息打印出来 #coding:utf-8 import os import win32com from win32com.client import Dispatch, constants from docx import Document def parse_doc(f):
-
Python读取Word(.docx)正文信息的方法
本文介绍用Python简单读取*.docx文件信息,一些python-word库就是对这种方法的扩展. 介绍分两部分: Word(*.docx)文件简述 Python提取Word信息 Word(*.docx)文件简述 大约在2008年以前,Office产品中Word用.doc文件格式,这种二进制格式很难与其他软件兼容. 为了跟上时代,微软采用类XML格式标准定义其新版Word文件.docx. .docx实际上是一个zip的压缩文件,比如我们有一个test.docx的文件: 其内容如下: 改变其后
-
用python处理MS Word的实例讲解
使用python工具读写MS Word文件(docx与doc文件),主要利用了python-docx包.本文给出一些常用的操作,并完成一个样例,帮助大家快速入手. 安装 pyhton处理docx文件需要使用python-docx 包,可以利用pip工具很方便的安装,pip工具在python安装路径下的Scripts文件夹中 pip install python-docx 当然你也可以选择使用easy_install或者手动方式进行安装 写入文件内容 此处我们直接给出一个样例,根据自己的需要摘取有
-
python模块之time模块(实例讲解)
time 表示时间的三种形式 时间戳(timestamp) :通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量.我们运行"type(time.time())",返回的是float类型. 格式化的时间字符串(Format String): '1999-12-06' 时间格式化符号 ''' %y 两位数的年份表示(00-99) %Y 四位数的年份表示(000-9999) %m 月份(01-12) %d 月内中的一天(0-31) %H 24小时制小时数(0-2
-
python数据结构之链表的实例讲解
在程序中,经常需要将⼀组(通常是同为某个类型的)数据元素作为整体 管理和使⽤,需要创建这种元素组,⽤变量记录它们,传进传出函数等. ⼀组数据中包含的元素个数可能发⽣变化(可以增加或删除元素). 对于这种需求,最简单的解决⽅案便是将这样⼀组元素看成⼀个序列,⽤ 元素在序列⾥的位置和顺序,表示实际应⽤中的某种有意义的信息,或者 表示数据之间的某种关系. 这样的⼀组序列元素的组织形式,我们可以将其抽象为线性表.⼀个线性 表是某类元素的⼀个集合,还记录着元素之间的⼀种顺序关系.线性表是 最基本的数据结构
-
Python网络爬虫与信息提取(实例讲解)
课程体系结构: 1.Requests框架:自动爬取HTML页面与自动网络请求提交 2.robots.txt:网络爬虫排除标准 3.BeautifulSoup框架:解析HTML页面 4.Re框架:正则框架,提取页面关键信息 5.Scrapy框架:网络爬虫原理介绍,专业爬虫框架介绍 理念:The Website is the API ... Python语言常用的IDE工具 文本工具类IDE: IDLE.Notepad++.Sublime Text.Vim & Emacs.Atom.Komodo E
-
Python数据处理numpy.median的实例讲解
numpy模块下的median作用为: 计算沿指定轴的中位数 返回数组元素的中位数 其函数接口为: median(a, axis=None, out=None, overwrite_input=False, keepdims=False) 其中各参数为: a:输入的数组: axis:计算哪个轴上的中位数,比如输入是二维数组,那么axis=0对应行,axis=1对应列: out:用于放置求取中位数后的数组. 它必须具有与预期输出相同的形状和缓冲区长度: overwrite_input:一个bool
-
python增加矩阵维度的实例讲解
numpy.expand_dims(a, axis) Examples >>> x = np.array([1,2]) >>> x.shape (2,) >>> y = np.expand_dims(x, axis=0) >>> y array([[1, 2]]) >>> y.shape (1, 2) >>> y = np.expand_dims(x, axis=1) # Equivalent to
-
对Python 网络设备巡检脚本的实例讲解
1.基本信息 我公司之前采用的是人工巡检,但奈何有大量网络设备,往往巡检需要花掉一上午(还是手速快的话),浪费时间浪费生命. 这段时间正好在学 Python ,于是乎想(其)要(实)解(就)放(是)双(懒)手. 好了,脚本很长又比较挫,有耐心就看看吧. 需要巡检的设备如下: 设备清单 设备型号 防火墙 华为 E8000E H3C M9006 飞塔 FG3950B 交换机 华为 S9306 H3C S12508 Cisco N7K 路由器 华为 NE40E 负载 Radware RD5412 Ra
-
对python 矩阵转置transpose的实例讲解
在读图片时,会用到这么的一段代码: image_vector_len = np.prod(image_size)#总元素大小,3*55*47 img = Image.open(path) arr_img = np.asarray(img, dtype='float64') arr_img = arr_img.transpose(2,0,1).reshape((image_vector_len, ))# 47行,55列,每个点有3个元素rgb.再把这些元素一字排开 transpose是什么意识呢?
-
python去除扩展名的实例讲解
获取不带扩展名的文件的名称: import os printos.path.splitext("path_to_file")[0] from os.path import basename # now you can call it directly with basename print basename("/a/b/c.txt") >>>base=os.path.basename('/root/dir/sub/file.ext') >&g
-
python 限制函数调用次数的实例讲解
如下代码,限制某个函数在某个时间段的调用次数, 灵感来源:python装饰器-限制函数调用次数的方法(10s调用一次)欢迎访问 原博客中指定的是缓存,我这里换成限制访问次数,异曲同工 #newtest.py #!/usr/bin/env python #-*- coding:utf-8 -*- import time def stat_called_time(func): cache={} limit_times=[10] def _called_time(*args,**kwargs): ke