详解python中list的使用
1、list(列表)是一种有序的集合,可以随时添加、修改、删除其中的元素。
举例:listClassName = ['Jack','Tom','Mark']
列表可以根据索引获取元素,如:listClassName[0] :

列表索引是从0开始的,最后一个元素索引是len(listClassName)-1;
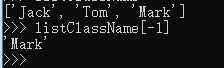
如果要取最后一个元素,除了计算索引位置外,还可以用-1做索引,直接获取最后一个元素:
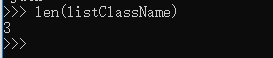
1.1 获取列表个数(长度):用len()函数,可以获取列表元素的个数(元素从1开始计算的):len(listClassName)
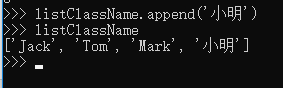
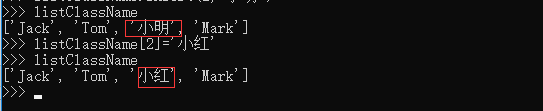
1.2 添加元素:用append()函数,可以再列表末尾添加元素:listClassName.append('小明')
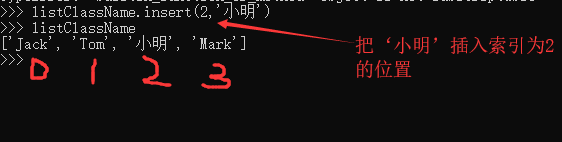
1.3 插入元素:用insert()函数,可以把元素插入到指定的位置:
1.4 替换元素:把某个元素替换成别的元素,可以直接赋值给对应的索引位置:
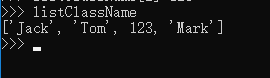
1.5 list里面的元素的数据类型也可以不同:
1.6 list元素也可以是另一个list:

以上所述是小编给大家介绍的python中list的使用详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
在python中以相同顺序shuffle两个list的方法
通常做机器学习问题时,需要准备训练数据,通常会把样本数据和标签存放于2个list中,比如train_x = [x1,x2,...,xN][x1,x2,...,xN],train_y = [y1,y2,...,yN][y1,y2,...,yN]. 有时候是需要将数据shuffle后再做处理的(比如,批量梯度下降算法,需要数据是打乱的). 这时就需要以相同的顺序打乱两个list,那么在python中如何实现呢?可以通过设置相同的随机种子,再shuffle的方式来实现. 代码如下: import ra
-
Python列表list排列组合操作示例
本文实例讲述了Python列表list排列组合操作.分享给大家供大家参考,具体如下: 排列 例如: 输入为 ['1','2','3']和3 输出为 ['111','112','113','121','122','123','131','132','133','211','212','213','221','222','223','231','232','233','311','312','313','321','322','323','331','332','333'] 实现代码: # -*-
-
Python list列表中删除多个重复元素操作示例
本文实例讲述了Python list列表中删除多个重复元素操作.分享给大家供大家参考,具体如下: 我们以下面这个list为例,删除其中所有值为6的元素: l=[9,6,5,6,6,7,8,9,6,0] 首先尝试remove方法: l.remove(6) print(l) 结果为:[9, 5, 6, 6, 7, 8, 9, 6, 0],只删除了第一个为6的元素. 如果采用for循环遍历各元素: for x in l: if x == 6: l.remove(x) 结果为[9, 5, 7, 8, 9
-
Python List cmp()知识点总结
描述 cmp() 方法用于比较两个列表的元素. 语法 cmp()方法语法: cmp(list1, list2) 参数 list1 -- 比较的列表. list2 -- 比较的列表. 返回值 如果比较的元素是同类型的,则比较其值,返回结果. 如果两个元素不是同一种类型,则检查它们是否是数字. 如果是数字,执行必要的数字强制类型转换,然后比较. 如果有一方的元素是数字,则另一方的元素"大"(数字是"最小的") 否则,通过类型名字的字母顺序进行比较. 如果有一个列表首先到
-
Python 多维List创建的问题小结
背景 最近在学Python,我觉得学习一个新语言最好的方式就是写一个简单的项目,所以就打算写一个简单的俄罗斯方块游戏.那么在写的过程中遇到了一个小问题. def __init__(self, width = 10, height = 30): self.width, self.height = width, height self.board_size = [width, height] 我用一个二维List来记录游戏空间的状态,game_boardx代表一个格子,0代表这格子是空的,1代表不是
-
Python判断一个list中是否包含另一个list全部元素的方法分析
本文实例讲述了Python判断一个list中是否包含另一个list全部元素的方法.分享给大家供大家参考,具体如下: 你可以用for in循环+in来判断 #!/usr/bin/env python # coding: utf-8 a = [1, 2, 3, 4, 5] b = [3, 4, 5] d = [False for c in b if c not in a] if d: print "a不包含b的所有元素" else: print "a包含b的所有元素"
-
详解python中executemany和序列的使用方法
详解python中executemany和序列的使用方法 一 代码 import sqlite3 persons=[ ("Jim","Green"), ("Hu","jie") ] conn=sqlite3.connect(":memory:") conn.execute("CREATE TABLE person(firstname,lastname)") conn.executeman
-
详解python中 os._exit() 和 sys.exit(), exit(0)和exit(1) 的用法和区别
详解python中 os._exit() 和 sys.exit(), exit(0)和exit(1) 的用法和区别 os._exit() 和 sys.exit() os._exit() vs sys.exit() 概述 Python的程序有两中退出方式:os._exit(), sys.exit().本文介绍这两种方式的区别和选择. os._exit()会直接将python程序终止,之后的所有代码都不会继续执行. sys.exit()会引发一个异常:SystemExit,如果这个异常没有被捕获,那
-
详解 Python中LEGB和闭包及装饰器
详解 Python中LEGB和闭包及装饰器 LEGB L>E>G?B L:local函数内部作用域 E:enclosing函数内部与内嵌函数之间 G:global全局作用域 B:build-in内置作用域 python 闭包 1.Closure:内部函数中对enclosing作用域变量的引用 2.函数实质与属性 函数是一个对象 函数执行完成后内部变量回收 函数属性 函数返回值 passline = 60 def func(val): if val >= passline: print (
-
详解python中的文件与目录操作
详解python中的文件与目录操作 一 获得当前路径 1.代码1 >>>import os >>>print('Current directory is ',os.getcwd()) Current directory is D:\Python36 2.代码2 如果将上面的脚本写入到文件再运行 Current directory is E:\python\work 二 获得目录的内容 Python代码 >>> os.listdir (os.getcwd
-
详解python中的 is 操作符
大家可以与Java中的 == 操作符相互印证一下,加深一下对引用和对象的理解.原问题: Python为什么直接运行和在命令行运行同样语句但结果却不同,他们的缓存机制不同吗? 其实,高票答案已经说得很详细了.我只是再补充一点而已. is 操作符是Python语言的一个内建的操作符.它的作用在于比较两个变量是否指向了同一个对象. 与 == 的区别 class A(): def __init__(self, v): self.value = v def __eq__(self, t): return
-
详解python中asyncio模块
一直对asyncio这个库比较感兴趣,毕竟这是官网也非常推荐的一个实现高并发的一个模块,python也是在python 3.4中引入了协程的概念.也通过这次整理更加深刻理解这个模块的使用 asyncio 是干什么的? 异步网络操作并发协程 python3.0时代,标准库里的异步网络模块:select(非常底层) python3.0时代,第三方异步网络库:Tornado python3.4时代,asyncio:支持TCP,子进程 现在的asyncio,有了很多的模块已经在支持:aiohttp,ai
-
详解python中的线程
Python中创建线程有两种方式:函数或者用类来创建线程对象. 函数式:调用 _thread 模块中的start_new_thread()函数来产生新线程. 类:创建threading.Thread的子类来包装一个线程对象. 1.线程的创建 1.1 通过thread类直接创建 import threading import time def foo(n): time.sleep(n) print("foo func:",n) def bar(n): time.sleep(n) prin
-
详解Python中pyautogui库的最全使用方法
在使用Python做脚本的话,有两个库可以使用,一个为PyUserInput库,另一个为pyautogui库.就本人而言,我更喜欢使用pyautogui库,该库功能多,使用便利.下面给大家介绍一下pyautogui库的使用方法.在cmd命令框中输入pip3 install pyautogui即可安装该库! 常用操作 我们在pyautogui库中常常使用的方法,如下: import pyautogui pyautogui.PAUSE = 1 # 调用在执行动作后暂停的秒数,只能在执行一些pyaut
-
详解Python中namedtuple的使用
namedtuple是Python中存储数据类型,比较常见的数据类型还有有list和tuple数据类型.相比于list,tuple中的元素不可修改,在映射中可以当键使用. namedtuple: namedtuple类位于collections模块,有了namedtuple后通过属性访问数据能够让我们的代码更加的直观更好维护. namedtuple能够用来创建类似于元祖的数据类型,除了能够用索引来访问数据,能够迭代,还能够方便的通过属性名来访问数据. 接下来通过本文给大家分享python nam
-
详解python中groupby函数通俗易懂
一.groupby 能做什么? python中groupby函数主要的作用是进行数据的分组以及分组后地组内运算! 对于数据的分组和分组运算主要是指groupby函数的应用,具体函数的规则如下: df[](指输出数据的结果属性名称).groupby([df[属性],df[属性])(指分类的属性,数据的限定定语,可以有多个).mean()(对于数据的计算方式--函数名称) 举例如下: print(df["评分"].groupby([df["地区"],df["类
随机推荐
- jquery中获取id值方法小结
- CentOS下Redis数据库的基本安装与配置教程
- hadoop map-reduce中的文件并发操作
- JS实现图片延迟加载并淡入淡出效果的简单方法
- 在Java的Hibernate框架中对数据库数据进行查询操作
- 详解微信小程序Radio选中样式切换
- JS+CSS实现表格高亮的方法
- 微信小程序(二十)slider组件详细介绍
- 火车头采集器3.0采集图文教程
- 使用Python绘制图表大全总结
- android高仿小米时钟(使用Camera和Matrix实现3D效果)
- Android中ViewPager实现滑动指示条及与Fragment的配合
- JavaScript 错误处理与调试经验总结
- Android 两个Fragment之间传递数据实例详解
- java生成json数据示例
- Android获取设备隐私 忽略6.0权限管理
- 在Python中使用NLTK库实现对词干的提取的教程
- 英语单词state与status的区别
- 浅谈java项目与javaweb项目导入jar包的区别
- javascript数组拍平方法总结