浅谈Python大神都是这样处理XML文件的
最近有同学询问如何利用Python处理xml文件,特此整理一个比较简洁的操作手册,供大家参阅。
首先准备一个xml文件,xml中的内容如下所示。存储为:student.xml
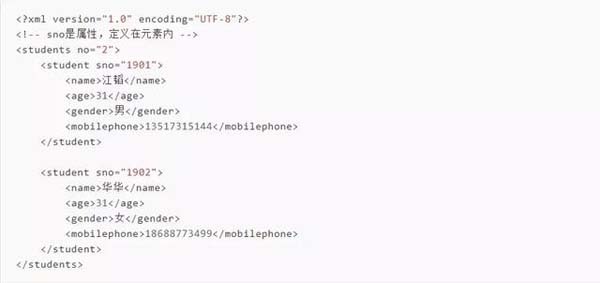
如果要获取这个xml里面的数据,我们需要利用Python里面ElementTree来进行处理。
具体操作如下所示:
1、导入包(包是Python内置自带)

2、打开文件,并获取根节点的属性和节点名称
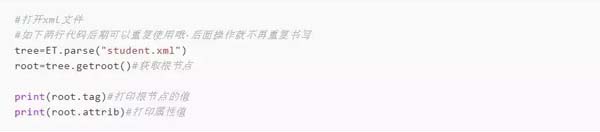
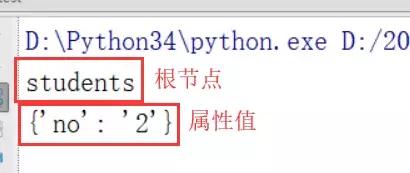
运行代码后,结果如下所示:
3、利用find方法获取子节点(缺点:只能根据提供的名称获取第一个子节点)

运行结果如下所示:

4、利用findall方法获取所有子节点,返回的节点会存在一个列表里面

运行的结果如下所示:运行的结果如下所示:

5、利用findall方法获取所有三级子节点,返回的节点会存在一个列表里面

运行结果如下所示:

6、利用遍历的方法去直接遍历子节点里面的所有元素

运行结果如下所示:

至此我们的xml的处理已经完全结束啦!
给大家留下一个练习题: 有一个xml的文件。内容如下,保存为:UILibrary.xml


针对上述xml文件,要求如下:
◆ 写一XmlUtil类
里面写一个函数:get_page
传递一个参数file_path
实现元素的读取,返回列表形式的数据,并且列表里面存储每个page节点的信息;
◆ 写一个page类
有2个属性:page_key_word,
存储页面信息;uiElement存储列表数据
◆ 写一个UiElement类
有1个属性:存储列表类型的数据,把每一个信息作为列表里面的一个数据。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python解析xml文件实例分析
本文实例讲述了python解析xml文件的方法.分享给大家供大家参考.具体如下: python解析xml非常方便.在dive into python中也有讲解. 如果xml的结构如下: <?xml version="1.0" encoding="utf-8"?> <books> <book> <author>zoer</author> <title>think in java</title
-
Python Xml文件添加字节属性的方法
实例如下所示: from xml.etree.cElementTree import ElementTree,Element import xlrd import re def read_xlsx(xlsx_path): workbook = xlrd.open_workbook(xlsx_path) booksheet = workbook.sheet_by_name("Sheet1") p = list() row_data = [] for row in range(booksh
-

python解析xml文件实例分享
复制代码 代码如下: def get_area_list(self): """获取地域省份和城市名称字典""" page = urllib2.urlopen(self.xml_url).read() area_list = {} root = ElementTree.fromstring(page) #读取xml格式文本 for onep in root:
-
Python 解析XML文件
Python文件: 复制代码 代码如下: #parsexml.py #本例子参考自python联机文档,做了适当改动和添加 import xml.parsers.expat #控制打印缩进 level = 0 #获取某节点名称及属性值集合 def start_element(name, attrs): global level print ' '*level, 'Start element:', name, attrs level = level + 1 #获取某节点结束名称 def end_e
-
python操作xml文件详细介绍
关于python读取xml文章很多,但大多文章都是贴一个xml文件,然后再贴个处理文件的代码.这样并不利于初学者的学习,希望这篇文章可以更通俗易懂的教如何使用python 来读取xml 文件. 一.什么是xml? xml即可扩展标记语言,它可以用来标记数据.定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言. abc.xml 复制代码 代码如下: <?xml version="1.0" encoding="utf-8"?> <catalo
-
python处理xml文件的方法小结
本文实例讲述了python处理xml文件的方法.分享给大家供大家参考,具体如下: 前一段时间因为工作的需要,学习了一点用Python处理xml文件的方法,现在贴出来,供大家参考. xml文件是按节点一层一层来叠加的,最顶层的是根节点.比如说: <sys:String x:Key="STR_License_WithoutLicense">Sorry, you are not authorized.</sys:String> 其中sys:String为节点名字,x:
-
利用python将xml文件解析成html文件的实现方法
功能就是题目所述,我的python2.7,装在windows环境,我使用的开发工具是wingide 6.0 1.首先是我设计的简单的一个xml文件,也就是用来解析的源文件 下面是这个文件website.xml内容: <website> <page name="index" title="fuckyou"> <h1>welcome to</h1> <p>this is a moment</p> &
-
python操作xml文件示例
复制代码 代码如下: def get_seed_data(filename):dom = minidom.parse(filename)root = dom.documentElementsystem_nodes = root.getElementsByTagName("system")k = 0seed_list = []for system_node in system_nodes: #print system_node.nodeName+' id='+system_node
-
python写入xml文件的方法
本文实例讲述了python写入xml文件的方法.分享给大家供大家参考.具体分析如下: 本范例通过xml模块对xml文件进行写入操作 from xml.dom.minidom import Document doc = Document() people = doc.createElement("people") doc.appendChild(people) aperson = doc.createElement("person") people.appendChi
-
Python创建xml文件示例
本文实例讲述了Python创建xml文件的方法.分享给大家供大家参考,具体如下: 这是一个使用ElementTree有关类库,生成xml文件的例子 # *-* coding=utf-8 from xml.etree.ElementTree import ElementTree from xml.etree.ElementTree import Element from xml.etree.ElementTree import SubElement from xml.etree.ElementTr