python 实现识别图片上的数字
Python 3.6 版本 Pytesseract 图像验证码识别
环境:
(1) win7 64位 (2) Idea (3) python 3.6 (4) pip install pillow < >pip install pytesseract (5) 识别引擎tesseract-ocr
安装
安装tesseract-ocr的识别引擎
第一步:下载安装包
根据https://github.com/UB-Mannheim/tesseract/wiki,找到下载安装包。

我下载的是64位,根据自己需要下载
第二步:安装
直接点击下载好的tesseract-ocr-w64-setup-v4.0.0-beta.1.20180608.exe文件,点击下一步,下一步,安装完成。
第三步:配置环境变量
复制你安装的路径,我的是安装在C:\Program Files (x86)\Tesseract-OCR,界面如下:

进入“计算机/属性”,点击“高级系统设置”,点击环境变量,找到path,点击编辑,在末尾粘贴你刚才复制的路径,
{粘贴时,你要给原有的信息末尾添加;分号}
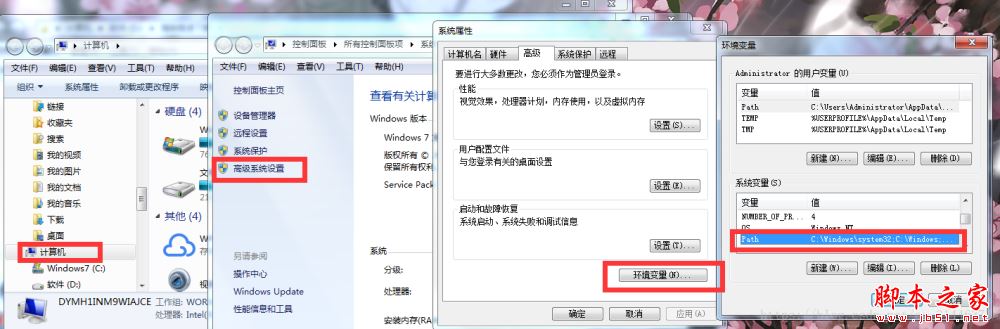
配置完毕后,点击保存。
打开命令行windows + R 输入cmd 打开 在命令行里面输入tesseract -v 配置成功会显示当前的tesseract版本

测试读取图片上的数字

KO!!!!!
出现问题:
解决方法:
添加环境变量内容
1.在环境变量里面增加一个TESSDATA_PREFIX变量名,变量值还是安装tesseract的路径。我这里还是放的我之前的路径
C:\Program Files (x86)\Tesseract-OCR;
2.修改python文件下的lib里面生成的一个pytesseract.py文件


修改里面的一个路径内容:ps:(tesseract_cmd = ‘D:/Program Files/Tesseract-OCR/tesseract.exe')网上也有人说是斜杠的
问题,可以修改双斜杠或者反斜杠

总结
以上所述是小编给大家介绍的python 实现识别图片上的数字,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
python 识别图片中的文字信息方法
最近朋友需要一个可以识别图片中的文字的程序,以前做过java验证码识别的程序: 刚好最近在做一个python项目,所以顺便用Python练练手 1.需要的环境: 2.7或者3.4版本的python 2.需要安装pytesseract库 依赖PIL和tesseract-ocr库 本地环境是ubuntu,下面说一下 具体步骤: 2.7 1.安装PIL: 直接使用pip 安装: pip install Pillow 2.安装tesseract-ocr: apt-get install tesserac
-

python验证码识别教程之利用投影法、连通域法分割图片
前言 今天这篇文章主要记录一下如何切分验证码,用到的主要库就是Pillow和Linux下的图像处理工具GIMP.首先假设一个固定位置和宽度.无粘连.无干扰的例子学习一下如何使用Pillow来切割图片. 使用GIMP打开图片后,按 加号 放大图片,然后点击View->Show Grid来显示网格线: 其中,每个正方形边长为10像素,所以数字1切割坐标为左20.上20.右40.下70.以此类推可以知道剩下3个数字的切割位置. 代码如下: from PIL import Image p = Image
-
Python实现识别手写数字 Python图片读入与处理
写在前面 在上一篇文章Python徒手实现手写数字识别-大纲中,我们已经讲过了我们想要写的全部思路,所以我们不再说全部的思路. 我这一次将图片的读入与处理的代码写了一下,和大纲写的过程一样,这一段代码分为以下几个部分: 读入图片: 将图片读取为灰度值矩阵: 图片背景去噪: 切割图片,得到手写数字的最小矩阵: 拉伸/压缩图片,得到标准大小为100x100大小矩阵: 将图片拉为1x10000大小向量,存入训练矩阵中. 所以下面将会对这几个函数进行详解. 代码分析 基础内容 首先我们现在最前面定义基础
-
python+opencv识别图片中的圆形
本文实例为大家分享了python+opencv识别图片中足球的方法,供大家参考,具体内容如下 先补充下霍夫圆变换的几个参数知识: dp,用来检测圆心的累加器图像的分辨率于输入图像之比的倒数,且此参数允许创建一个比输入图像分辨率低的累加器.上述文字不好理解的话,来看例子吧.例如,如果dp= 1时,累加器和输入图像具有相同的分辨率.如果dp=2,累加器便有输入图像一半那么大的宽度和高度. minDist,为霍夫变换检测到的圆的圆心之间的最小距离,即让我们的算法能明显区分的两个不同圆之间的最小距离.这
-
Python实现识别手写数字 简易图片存储管理系统
写在前面 上一篇文章Python实现识别手写数字-图像的处理中我们讲了图片的处理,将图片经过剪裁,拉伸等操作以后将每一个图片变成了1x10000大小的向量.但是如果只是这样的话,我们每一次运行的时候都需要将他们计算一遍,当图片特别多的时候会消耗大量的时间. 所以我们需要将这些向量存入一个文件当中,每次先看看图库中有没有新增的图片,如果有新增的图片,那么就将新增的图片变成1x10000向量再存入文件之中,然后从文件中读取全部图片向量即可.当图库中没有新增图片的时候,那么就直接调用文件中的图片向量进
-
python验证码识别教程之利用滴水算法分割图片
滴水算法概述 滴水算法是一种用于分割手写粘连字符的算法,与以往的直线式地分割不同 ,它模拟水滴的滚动,通过水滴的滚动路径来分割字符,可以解决直线切割造成的过分分割问题. 引言 之前提过对于有粘连的字符可以使用滴水算法来解决分割,但智商捉急的我实在是领悟不了这个算法的精髓,幸好有小伙伴已经实现相关代码. 我对上面的代码进行了一些小修改,同时升级为python3的代码. 还是以这张图片为例: 在以前的我们已经知道这种简单的粘连可以通过控制阈值来实现分割,这里我们使用滴水算法. 首先使用之前文章中介绍
-
python tensorflow学习之识别单张图片的实现的示例
假设我们已经安装好了tensorflow. 一般在安装好tensorflow后,都会跑它的demo,而最常见的demo就是手写数字识别的demo,也就是mnist数据集. 然而我们仅仅是跑了它的demo而已,可能很多人会有和我一样的想法,如果拿来一张数字图片,如何应用我们训练的网络模型来识别出来,下面我们就以mnist的demo来实现它. 1.训练模型 首先我们要训练好模型,并且把模型model.ckpt保存到指定文件夹 saver = tf.train.Saver() saver.save(s
-
python 实现识别图片上的数字
Python 3.6 版本 Pytesseract 图像验证码识别 环境: (1) win7 64位 (2) Idea (3) python 3.6 (4) pip install pillow < >pip install pytesseract (5) 识别引擎tesseract-ocr 安装 安装tesseract-ocr的识别引擎 第一步:下载安装包 根据https://github.com/UB-Mannheim/tesseract/wiki,找到下载安装包. 我下载
-
Python小程序之在图片上加入数字的代码
在GitHub上发现一些很有意思的项目,由于本人作为Python的初学者,编程代码能力相对薄弱,为了加强Python的学习,特此利用前辈们的学习知识成果,自己去亲自实现. 来源:GitHub Python练手小程序项目地址:https://github.com/Show-Me-the-Code/python 写作日期:2019.11.24 今天练习的小程序,是其中第0000题,题目如下: 将你的 QQ 头像(或者微博头像)右上角加上红色的数字,类似于微信未读信息数量那种提示效果. 如下图中的效果
-
python批量识别图片指定区域文字内容
Python批量识别图片指定区域文字内容,供大家参考,具体内容如下 简介 对于一张图片,需求识别指定区域的内容 1.截取原始图上的指定图片当做模板 2.根据模板相似度去再原始图片上识别准确坐标 3.根据坐标剪切出指定位置图片,也就是所需的内容区域 4.对指定位置图片进行ocr识别 环境 Ubuntu18.04 Python2.7 所需Python模块 1.aircv 用于识别模板再原始图的位置坐标 pip install aircv 2.Pillow 用于剪裁图片 pip install Pil
-
Python实现识别图片为文字的示例代码
目录 1.环境准备 2.业务实现 3.效果展示 本来想着做一个将图片识别为文字的小功能,本想到Google上面第一页全是各种收费平台的广告. 这些平台提供的基本都是让我们通过调用相关的三方接口实现的,本着坚决不想花一分钱的态度,在论坛找有没有可以免费解决的方案. 果然,有大佬早就做出开源框架pytesseract,差点让我损失了一笔巨款,哈哈~ 这次只为实现将图片识别为文字的业务功能,就不使用PyQt5做页面应用了.后面若是需要做成UI应用朋友比较多,我有时间会将这个小工具封装开发成一个PyQ5
-
opencv如何识别图片上带颜色的圆
本文实例为大家分享了opencv识别图片上带颜色的圆的具体代码,供大家参考,具体内容如下 识别带颜色的圆,首先需要先查询该颜色的HSV值,下图部分紫色归为红色了: 比如红色: //红色的HSV值 int low_H = 0,low_S = 123,low_V = 100; int High_H = 5,High_S = 255,High_V = 255; 然后将图片从BGR转化成HSV,接着二值化: cvtColor(image,src,COLOR_BGR2HSV); //从BGR-> HSV
-
Python Flask实现图片上传与下载的示例详解
目录 1.效果预览 2.新增逻辑概览 3.tuchuang.py 逻辑介绍 3.1 图片上传 3.2 图片合法检查 3.3 图片下载 4.__init__.py 逻辑介绍 5.upload.html 介绍 5.1 upload Jinja 模板介绍 5.2 upload css 介绍(虚线框) 5.3 upload js 介绍(拖拽) 1.效果预览 我们基于 Flask 官方指导工程,增加一个图片拖拽上传功能,效果如下: 2.新增逻辑概览 我们在官方指导工程上进行增加代码,改动如下: 由于 fl
-
Python OpenCV实现图片上输出中文
OpenCV中在图片上输出中文一般需要借助FreeType库实现.FreeType库是一个完全免费(开源)的.高质量的且可移植的字体引擎,它提供统一的接口来访问多种字体格式文件.但使用FreeType需要下载库并重新编译,过程麻烦一点. 在Python中,可以借助PIL(Python Imaging Library)模块实现,相对简单很多,需要做的只是对图像进行OpenCV格式和PIL格式的相互转换. # -*- coding: utf-8 -*- import cv2 import numpy
-
c#实现识别图片上的验证码数字
public void imgdo(Bitmap img) { //去色 Bitmap btp = img; Color c = new Color(); int rr, gg, bb; for (int i = 0; i < btp.Width; i++) { for (int j = 0; j < btp.Height; j++) { //取图片当前的像素点 c = btp.GetPixel(i, j); rr = c.R; gg = c.G; bb = c.B; //改变颜色 if (r
-
python实现在图片上画特定大小角度矩形框
做图像识别的时候需要在图片中画出特定大小和角度的矩形框,自己写了一个函数,给定的输入是图片名称,矩形框的位置坐标,长宽和角度,直接输出画好矩形框的图片. 主要思想是先根据x,y坐标和长宽得到矩形,然后通过数学计算得到旋转angle角度后的新矩形框的四个顶点位置坐标,再利用draw.line()函数画出来. import math import matplotlib.pyplot as plt import numpy as np from PIL import Image, ImageDraw