利用Pandas读取文件路径或文件名称包含中文的csv文件方法
利用Pandas的read_csv函数导入数据文件时,若文件路径或文件名包含中文,会报错,无法导入:
import pandas as pd
df=pd.read_csv('E:/学习相关/Python/数据样例/用户侧数据/账单.csv')
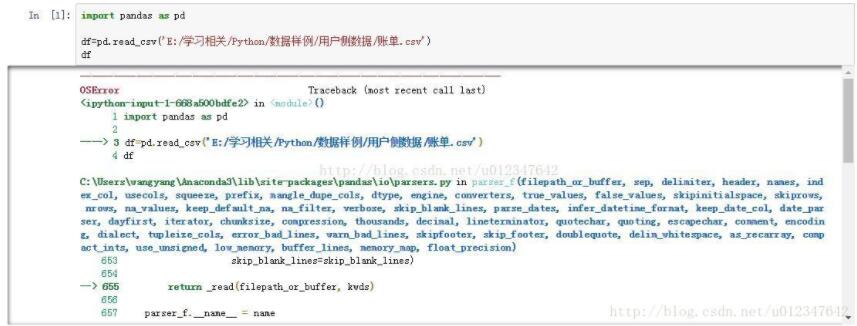
解决方法如下:
import pandas as pd
f=open('E:/学习相关/Python/数据样例/用户侧数据/账单.csv')
df=pd.read_csv(f)
以上这篇利用Pandas读取文件路径或文件名称包含中文的csv文件方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
使用pandas读取csv文件的指定列方法
根据教程实现了读取csv文件前面的几行数据,一下就想到了是不是可以实现前面几列的数据.经过多番尝试总算试出来了一种方法. 之所以想实现读取前面的几列是因为我手头的一个csv文件恰好有后面几列没有可用数据,但是却一直存在着.原来的数据如下: GreydeMac-mini:chapter06 greyzhang$ cat data.csv 1,name_01,coment_01,,,, 2,name_02,coment_02,,,, 3,name_03,coment_03,,,, 4,name_04
-
基于Pandas读取csv文件Error的总结
OSError:报错1 <span style="font-size:14px;">pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader.__cinit__ (pandas\_libs\parsers.c:4209)() pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader._setup_parser_source (pandas\_libs\
-
使用pandas模块读取csv文件和excel表格,并用matplotlib画图的方法
如下所示: # coding=utf-8 import pandas as pd # 读取csv文件 3列取名为 name,sex,births,后面参数格式为names= names1880 = pd.read_csv("names_1880.txt", names=['name', 'sex', 'births']) print names1880 print names1880.groupby('sex').births.sum() 输出如下 最后一行是说按sex分组并计算bir
-
使用pandas read_table读取csv文件的方法
read_csv是pandas中专门用于csv文件读取的功能,不过这并不是唯一的处理方式.pandas中还有读取表格的通用函数read_table. 接下来使用read_table功能作一下csv文件的读取尝试,使用此功能的时候需要指定文件中的内容分隔符. 查看csv文件的内容如下: In [10]: cat data.csv index,name,comment,,,, 1,name_01,coment_01,,,, 2,name_02,coment_02,,,, 3,name_03,come
-
解决pandas使用read_csv()读取文件遇到的问题
如下: 数据文件: 上海机场 (sh600009) 24.11 3.58 东风汽车 (sh600006) 74.25 1.74 中国国贸 (sh600007) 26.38 2.66 包钢股份 (sh600010) 61.01 2.35 武钢股份 (sh600005) 75.85 1.3 浦发银行 (sh600000) 6.65 0.96 在使用read_csv() API读取CSV文件时求取某一列数据比较大小时, df=pd.read_csv(output_file,encoding='gb23
-
使用实现pandas读取csv文件指定的前几行
用于存储数据的csv文件有时候数据量是十分庞大的,然而我们有时候并不需要全部的数据,我们需要的可能仅仅是前面的几行. 这样就可以通过pandas中read_csv中指定行数读取的功能实现. 例如有data.csv文件,文件的内容如下: GreydeMac-mini:chapter06 greyzhang$ cat data.csv ,name_01,coment_01,,,, 2,name_02,coment_02,,,, 3,name_03,coment_03,,,, 4,name_04,co
-
解决pandas read_csv 读取中文列标题文件报错的问题
从windows操作系统本地读取csv文件报错 data = pd.read_csv(path) Traceback (most recent call last): File "C:/Users/arron/PycharmProjects/ML/ML/test.py", line 45, in <module> data = pd.read_csv(path) File "C:\Users\arron\AppData\Local\Continuum\Anacon
-
利用Pandas读取文件路径或文件名称包含中文的csv文件方法
利用Pandas的read_csv函数导入数据文件时,若文件路径或文件名包含中文,会报错,无法导入: import pandas as pd df=pd.read_csv('E:/学习相关/Python/数据样例/用户侧数据/账单.csv') 解决方法如下: import pandas as pd f=open('E:/学习相关/Python/数据样例/用户侧数据/账单.csv') df=pd.read_csv(f) 以上这篇利用Pandas读取文件路径或文件名称包含中文的csv文件方法就是小编
-

Python如何利用pandas读取csv数据并绘图
目录 如何利用pandas读取csv数据并绘图 绘制图像 展示结果 pandas画pearson相关系数热力图 pearson相关系数计算函数 如何利用pandas读取csv数据并绘图 导包,常用的numpy和pandas,绘图模块matplotlib, import matplotlib.pyplot as plt import pandas as pd import numpy as np fig = plt.figure() ax = fig.add_subplot(111) 读取csv文
-
利用Pandas读取某列某行数据之loc和iloc用法总结
目录 1.loc方法 2.iloc方法 补充:利用loc.iloc提取所有数据 总结 实际操作中我们经常需要寻找数据的某行或者某列,这里介绍我在使用Pandas时用到的两种方法:iloc和loc. loc:通过行.列的名称或标签来索引 iloc:通过行.列的索引位置来寻找数据 首先,我们先创建一个Dataframe,生成数据,用于下面的演示 import pandas as pd import numpy as np # 生成DataFrame data = pd.DataFrame(np.ar
-
利用pandas读取中文数据集的方法
直接利用numpy读取非数字型的数据集时需要先进行转换,而且python3在处理中文数据方面确实比较蛋疼.最近在学习周志华老师的那本西瓜书,需要没事和一堆西瓜反复较劲,之前进行联系的时候都是利用批量替换先清理一遍数据,不过这样实在是太麻烦了,今天偶然发现可以使用pandas来实现读取中文数据集的功能. 首先分享一下数据集: 编号,色泽,根蒂,敲声,纹理,脐部,触感,密度,含糖率,好瓜 1,青绿,蜷缩,浊响,清晰,凹陷,硬滑,0.697,0.46,是 2,乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,0.7
-
利用Pandas读取表格行数据判断是否相同的方法
描述: 下午快下班的时候公司供应链部门的同事跑过来问我能不能以程序的方法帮他解决一些excel表格每周都需要手工重复做的事情,Excel 是数据处理最常用的办公工具对于市场.运营都应该很熟练.哈哈,然而程序员是不怎么会用excel的.下面给大家介绍一下pandas, Pandas是一个强大的分析结构化数据的工具集:它的使用基础是Numpy(提供高性能的矩阵运算):用于数据挖掘和数据分析,同时也提供数据清洗功能. 具体需求: 找出相同的数字,把与数字对应的英文字母合并在一起. 期望最终生成值:
-
Python将一个CSV文件里的数据追加到另一个CSV文件的方法
在做数据处理工作时,有时需要将数据合并在一起,本文主要使用Python将两个CSV文件内数据合并在一起,合并方式有很多,本文只追加方式. 首先给定两个CSV文件的内容 1.CSV 2.CSV 将2.CSV文件里的数据追加到1.CSV后面 直接敲写Python代码 with open('1.csv','ab') as f: f.write(open('2.csv','rb').read())#将2.csv内容追加到1.csv的后面 查看1.CSV内的数据变化情况 非常简单快捷的一次Python操作
-
Python利用pandas计算多个CSV文件数据值的实例
功能:扫描当前目录下所有CSV文件并对其中文件进行统计,输出统计值到CSV文件 pip install pandas import pandas as pd import glob,os,sys input_path='./' output_fiel='pandas_union_concat.csv' all_files=glob.glob(os.path.join(input_path,'sales_*')) all_data_frames=[] for file in all_files:
-
python pandas 解析(读取、写入)CSV 文件的操作方法
目录 1. 使用 pandas 读取 CSV 文件 2. 使用 pandas 写入 CSV 文件 1. 使用 pandas 读取 CSV 文件 原始数据包含了公司员工的数据: Name Hire Date Salary Sick Days remaining Graham Chapman 03/15/14 50000.00 10 John Cleese 06/01/15 65000.00 8 Eric Idle 05/12/14 45000.00 10 Terry Jones 11/01/13
-
python:pandas合并csv文件的方法(图书数据集成)
数据集成:将不同表的数据通过主键进行连接起来,方便对数据进行整体的分析. 两张表:ReaderInformation.csv,ReaderRentRecode.csv ReaderInformation.csv: ReaderRentRecode.csv: pandas读取csv文件,并进行csv文件合并处理: # -*- coding:utf-8 -*- import csv as csv import numpy as np # ------------- # csv读取表格数据 # ---
-
使用pandas库对csv文件进行筛选保存
这个操作现在看来真没啥难的,但是我找相关的资料真的找了好久. 多数大佬都是直接pandas官网甩我脸上,然后举一个入门级的例子. https://pandas.pydata.org/docs/reference/index.html 首先导入pandas库 import pandas as pd 然后使用read_csv来打开指定的csv文件 df = pd.read_csv('./IP2LOCATION.csv',encoding= 'utf-8') 这个函数里面需要写入csv文件的路径,如果