Docker安装ELK并实现JSON格式日志分析的方法
ELK是什么
ELK是elastic公司提供的一套完整的日志收集以及前端展示的解决方案,是三个产品的首字母缩写,分别是ElasticSearch、Logstash和Kibana。
其中Logstash负责对日志进行处理,如日志的过滤、日志的格式化等;ElasticSearch具有强大的文本搜索能力,因此作为日志的存储容器;而Kibana负责前端的展示。
ELK搭建架构如下图:
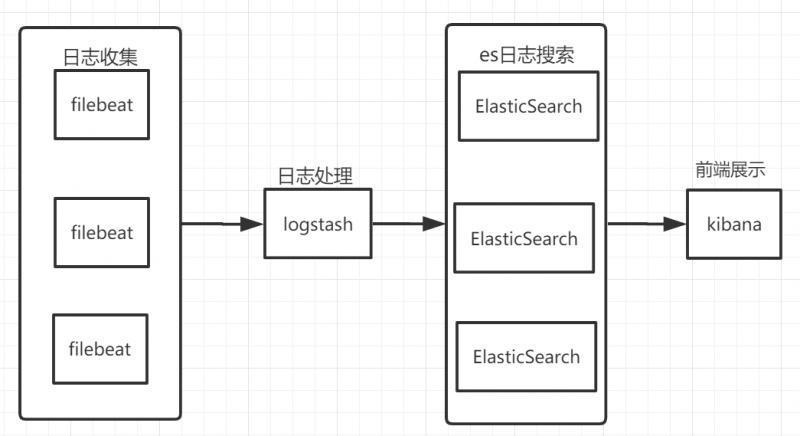
加入了filebeat用于从不同的客户端收集日志,然后传递到Logstash统一处理。
ELK的搭建
因为ELK是三个产品,可以选择依次安装这三个产品。
这里选择使用Docker安装ELk。
Docker安装ELk也可以选择分别下载这三个产品的镜像并运行,但是本次使用直接下载elk的三合一镜像来安装。
因此首先要保证已经有了Docker的运行环境,Docker运行环境的搭建请查看:https://blog.csdn.net/qq13112...
拉取镜像
有了Docker环境之后,在服务器运行命令:
docker pull sebp/elk
这个命令是在从Docker仓库下载elk三合一的镜像,总大小为2个多G,如果发现下载速度过慢,可以将Docker仓库源地址替换为国内源地址。
下载完成之后,查看镜像:
docker images

Logstash配置
在/usr/config/logstash目录下新建beats-input.conf,用于日志的输入:
input {
beats {
port => 5044
}
}
新建output.conf,用于日志由Logstash到ElasticSearch的输出:
output {
elasticsearch {
hosts => ["localhost"]
manage_template => false
index => "%{[@metadata][beat]}"
}
}
其中的index为输出到ElasticSearch后的index。
运行容器
有了镜像之后直接启动即可:
docker run -d -p 5044:5044 -p 5601:5601 -p 9203:9200 -p 9303:9300 -v /var/data/elk:/var/lib/elasticsearch -v /usr/config/logstash:/etc/logstash/conf.d --name=elk sebp/elk
-d的意思是后台运行容器;
-p的意思是宿主机端口:容器端口,即将容器中使用的端口映射到宿主机上的某个端口,ElasticSearch的默认端口是9200和9300,由于我的机器上已经运行了3台ElasticSearch实例,因此此处将映射端口进行了修改;
-v的意思是宿主机的文件|文件夹:容器的文件|文件夹,此处将容器中elasticsearch 的数据挂载到宿主机的/var/data/elk上,以防容器重启后数据的丢失;并且将logstash的配置文件挂载到宿主机的/usr/config/logstash目录。
--name的意思是给容器命名,命名是为了之后操作容器更加方便。
如果你之前搭建过ElasticSearch的话,会发现搭建的过程中有各种错误,但是使用docker搭建elk的过程中并没有出现那些错误。
运行后查看容器:
docker ps

查看容器日志:
docker logs -f elk
进入容器:
docker exec -it elk /bin/bash
修改配置后重启容器:
docker restart elk
查看kinaba
浏览器输入http://my_host:5601/
即可看到kinaba界面。此时ElasticSearch中还没有数据,需要安装Filebeat采集数据到elk中。
Filebeat搭建
Filebeat用于采集数据并上报到Logstash或者ElasticSearch,在需要采集日志的服务器上下载Filebeat并解压即可使用
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.2.1-linux-x86_64.tar.gz
tar -zxvf filebeat-6.2.1-linux-x86_64.tar.gz
修改配置文件
进入filebeat,修改filebeat.yml。
filebeat.prospectors: - type: log #需要设置为true配置才能生效 enabled: true path: #配置需要采集的日志路径 - /var/log/*.log #可以打一个tag以后分类使用 tag: ["my_tag"] #对应ElasticSearch的type document_type: my_type setup.kibana: #此处为kibana的ip及端口,即kibana:5601 host: "" output.logstash: #此处为logstash的ip及端口,即logstash:5044 host: [""] #需要设置为true,否则不生效 enabled: true #如果想直接从Filebeat采集数据到ElasticSearch,则可以配置output.elasticsearch的相关配置
运行Filebeat
运行:
./filebeat -e -c filebeat.yml -d "publish"
此时可以看到Filebeat会将配置的path下的log发送到Logstash;然后在elk中,Logstash处理完数据之后就会发送到ElasticSearch。但我们想做的是通过elk进行数据分析,因此导入到ElasticSearch的数据必须是JSON格式的。
这是之前我的单条日志的格式:
2019-10-22 10:44:03.441 INFO rmjk.interceptors.IPInterceptor Line:248 - {"clientType":"1","deCode":"0fbd93a286533d071","eaType":2,"eaid":191970823383420928,"ip":"xx.xx.xx.xx","model":"HONOR STF-AL10","osType":"9","path":"/applicationEnter","result":5,"session":"ef0a5c4bca424194b29e2ff31632ee5c","timestamp":1571712242326,"uid":"130605789659402240","v":"2.2.4"}
导入之后不好分析,之后又想到使用Logstash的filter中的grok来处理日志使之变成JSON格式之后再导入到ElasticSearch中,但是由于我的日志中的参数是不固定的,发现难度太大了,于是转而使用Logback,将日志直接格式化成JSON之后,再由Filebeat发送。
Logback配置
我的项目是Spring Boot,在项目中加入依赖:
<dependency> <groupId>net.logstash.logback</groupId> <artifactId>logstash-logback-encoder</artifactId> <version>5.2</version> </dependency>
然后在项目中的resource目录下加入logback.xml:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!--
说明:
1、日志级别及文件
日志记录采用分级记录,级别与日志文件名相对应,不同级别的日志信息记录到不同的日志文件中
例如:error级别记录到log_error_xxx.log或log_error.log(该文件为当前记录的日志文件),而log_error_xxx.log为归档日志,
日志文件按日期记录,同一天内,若日志文件大小等于或大于2M,则按0、1、2...顺序分别命名
例如log-level-2013-12-21.0.log
其它级别的日志也是如此。
2、文件路径
若开发、测试用,在Eclipse中运行项目,则到Eclipse的安装路径查找logs文件夹,以相对路径../logs。
若部署到Tomcat下,则在Tomcat下的logs文件中
3、Appender
FILEERROR对应error级别,文件名以log-error-xxx.log形式命名
FILEWARN对应warn级别,文件名以log-warn-xxx.log形式命名
FILEINFO对应info级别,文件名以log-info-xxx.log形式命名
FILEDEBUG对应debug级别,文件名以log-debug-xxx.log形式命名
stdout将日志信息输出到控制上,为方便开发测试使用
-->
<contextName>service</contextName>
<property name="LOG_PATH" value="logs"/>
<!--设置系统日志目录-->
<property name="APPDIR" value="doctor"/>
<!-- 日志记录器,日期滚动记录 -->
<appender name="FILEERROR" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 正在记录的日志文件的路径及文件名 -->
<file>${LOG_PATH}/${APPDIR}/log_error.log</file>
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 归档的日志文件的路径,例如今天是2013-12-21日志,当前写的日志文件路径为file节点指定,可以将此文件与file指定文件路径设置为不同路径,从而将当前日志文件或归档日志文件置不同的目录。
而2013-12-21的日志文件在由fileNamePattern指定。%d{yyyy-MM-dd}指定日期格式,%i指定索引 -->
<fileNamePattern>${LOG_PATH}/${APPDIR}/error/log-error-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<!-- 除按日志记录之外,还配置了日志文件不能超过2M,若超过2M,日志文件会以索引0开始,
命名日志文件,例如log-error-2013-12-21.0.log -->
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>2MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
</rollingPolicy>
<!-- 追加方式记录日志 -->
<append>true</append>
<!-- 日志文件的格式 -->
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level %logger Line:%-3L - %msg%n</pattern>
<charset>utf-8</charset>
</encoder>
<!-- 此日志文件只记录info级别的 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>error</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<!-- 日志记录器,日期滚动记录 -->
<appender name="FILEWARN" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 正在记录的日志文件的路径及文件名 -->
<file>${LOG_PATH}/${APPDIR}/log_warn.log</file>
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 归档的日志文件的路径,例如今天是2013-12-21日志,当前写的日志文件路径为file节点指定,可以将此文件与file指定文件路径设置为不同路径,从而将当前日志文件或归档日志文件置不同的目录。
而2013-12-21的日志文件在由fileNamePattern指定。%d{yyyy-MM-dd}指定日期格式,%i指定索引 -->
<fileNamePattern>${LOG_PATH}/${APPDIR}/warn/log-warn-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<!-- 除按日志记录之外,还配置了日志文件不能超过2M,若超过2M,日志文件会以索引0开始,
命名日志文件,例如log-error-2013-12-21.0.log -->
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>2MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
</rollingPolicy>
<!-- 追加方式记录日志 -->
<append>true</append>
<!-- 日志文件的格式 -->
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level %logger Line:%-3L - %msg%n</pattern>
<charset>utf-8</charset>
</encoder>
<!-- 此日志文件只记录info级别的 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>warn</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<!-- 日志记录器,日期滚动记录 -->
<appender name="FILEINFO" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 正在记录的日志文件的路径及文件名 -->
<file>${LOG_PATH}/${APPDIR}/log_info.log</file>
<!-- 日志记录器的滚动策略,按日期,按大小记录 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 归档的日志文件的路径,例如今天是2013-12-21日志,当前写的日志文件路径为file节点指定,可以将此文件与file指定文件路径设置为不同路径,从而将当前日志文件或归档日志文件置不同的目录。
而2013-12-21的日志文件在由fileNamePattern指定。%d{yyyy-MM-dd}指定日期格式,%i指定索引 -->
<fileNamePattern>${LOG_PATH}/${APPDIR}/info/log-info-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<!-- 除按日志记录之外,还配置了日志文件不能超过2M,若超过2M,日志文件会以索引0开始,
命名日志文件,例如log-error-2013-12-21.0.log -->
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>2MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
</rollingPolicy>
<!-- 追加方式记录日志 -->
<append>true</append>
<!-- 日志文件的格式 -->
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level %logger Line:%-3L - %msg%n</pattern>
<charset>utf-8</charset>
</encoder>
<!-- 此日志文件只记录info级别的 -->
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>info</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<appender name="jsonLog" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- 正在记录的日志文件的路径及文件名 -->
<file>${LOG_PATH}/${APPDIR}/log_IPInterceptor.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_PATH}/${APPDIR}/log_IPInterceptor.%d{yyyy-MM-dd}.log</fileNamePattern>
</rollingPolicy>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<jsonFactoryDecorator class="net.logstash.logback.decorate.CharacterEscapesJsonFactoryDecorator">
<escape>
<targetCharacterCode>10</targetCharacterCode>
<escapeSequence>\u2028</escapeSequence>
</escape>
</jsonFactoryDecorator>
<providers>
<pattern>
<pattern>
{
"timestamp":"%date{ISO8601}",
"uid":"%mdc{uid}",
"requestIp":"%mdc{ip}",
"id":"%mdc{id}",
"clientType":"%mdc{clientType}",
"v":"%mdc{v}",
"deCode":"%mdc{deCode}",
"dataId":"%mdc{dataId}",
"dataType":"%mdc{dataType}",
"vid":"%mdc{vid}",
"did":"%mdc{did}",
"cid":"%mdc{cid}",
"tagId":"%mdc{tagId}"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>
<!-- 彩色日志 -->
<!-- 彩色日志依赖的渲染类 -->
<conversionRule conversionWord="clr" converterClass="org.springframework.boot.logging.logback.ColorConverter"/>
<conversionRule conversionWord="wex"
converterClass="org.springframework.boot.logging.logback.WhitespaceThrowableProxyConverter"/>
<conversionRule conversionWord="wEx"
converterClass="org.springframework.boot.logging.logback.ExtendedWhitespaceThrowableProxyConverter"/>
<!-- 彩色日志格式 -->
<property name="CONSOLE_LOG_PATTERN"
value="${CONSOLE_LOG_PATTERN:-%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}}"/>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<!--encoder 默认配置为PatternLayoutEncoder-->
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf-8</charset>
</encoder>
<!--此日志appender是为开发使用,只配置最底级别,控制台输出的日志级别是大于或等于此级别的日志信息-->
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>debug</level>
</filter>
</appender>
<!-- 指定项目中某个包,当有日志操作行为时的日志记录级别 -->
<!-- rmjk.dao.mappe为根包,也就是只要是发生在这个根包下面的所有日志操作行为的权限都是DEBUG -->
<!-- 级别依次为【从高到低】:FATAL > ERROR > WARN > INFO > DEBUG > TRACE -->
<logger name="rmjk.dao.mapper" level="DEBUG"/>
<logger name="rmjk.service" level="DEBUG"/>
<!--显示日志-->
<logger name="org.springframework.jdbc.core" additivity="false" level="DEBUG">
<appender-ref ref="STDOUT"/>
<appender-ref ref="FILEINFO"/>
</logger>
<!-- 打印json日志 -->
<logger name="IPInterceptor" level="info" additivity="false">
<appender-ref ref="jsonLog"/>
</logger>
<!-- 生产环境下,将此级别配置为适合的级别,以免日志文件太多或影响程序性能 -->
<root level="INFO">
<appender-ref ref="FILEERROR"/>
<appender-ref ref="FILEWARN"/>
<appender-ref ref="FILEINFO"/>
<!-- 生产环境将请stdout,testfile去掉 -->
<appender-ref ref="STDOUT"/>
</root>
</configuration>
其中的关键为:
<logger name="IPInterceptor" level="info" additivity="false"> <appender-ref ref="jsonLog"/> </logger>
在需要打印的文件中引入slf4j:
private static final Logger LOG = LoggerFactory.getLogger("IPInterceptor");
MDC中放入需要打印的信息:
MDC.put("ip", ipAddress);
MDC.put("path", servletPath);
MDC.put("uid", paramMap.get("uid") == null ? "" : paramMap.get("uid").toString());
此时如果使用了LOG.info("msg")的话,打印的内容会输入到日志的message中,日志格式如下:

修改Logstash配置
修改/usr/config/logstash目录下的beats-input.conf:
input {
beats {
port => 5044
codec => "json"
}
}
只加了一句codec => "json",但是Logstash会按照JSON格式来解析输入的内容。
因为修改了配置,重启elk:
docker restart elk
这样,当我们的日志生成完毕之后,使用Filebeat导入到elk中,就可以通过Kibana来进行日志分析了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
详解使用Docker快速部署ELK环境(最新5.5.1版本)
在Linux服务器上安装Docker以后,Pull相关的官方Docker镜像: docker pull docker.elastic.co/elasticsearch/elasticsearch:5.5.1 docker pull docker.elastic.co/kibana/kibana:5.5.1 docker pull docker.elastic.co/logstash/logstash:5.5.1 启动Elastic Search容器: docker run -p 9200:920
-
使用docker compose搭建一个elk系统的方法
找了不少使用 docker-elk 搭建的博客, 英文的阅读吃力不说, 镜像源也是慢的让人头皮发麻, 因此重新编排了一个docker-compose,源都是从 https://hub.docker.com/ 上找的, 即使拉的国内镜像源应该也能很好的支持了吧? 环境 Docker 18.06.0-ce docker-compose 1.22.0 给每个容器最少分配 1G 的内存 软件版本 logstash: 5.* elasticsearch: 5.* kibana: 5.* 启动前的配置 在各
-
详解利用ELK搭建Docker容器化应用日志中心
概述 应用一旦容器化以后,需要考虑的就是如何采集位于Docker容器中的应用程序的打印日志供运维分析.典型的比如SpringBoot应用的日志 收集.本文即将阐述如何利用ELK日志中心来收集容器化应用程序所产生的日志,并且可以用可视化的方式对日志进行查询与分析,其架构如下图所示: 架构图 镜像准备 镜像准备 ElasticSearch镜像 Logstash镜像 Kibana镜像 Nginx镜像(作为容器化应用来生产日志) 开启Linux系统Rsyslog服务 修改Rsyslog服务配置文件: v
-
详解如何使用Docker快速部署ELK环境(最新5.5.1版本)
在Linux服务器上安装Docker以后,Pull相关的官方Docker镜像: docker pull docker.elastic.co/elasticsearch/elasticsearch:5.5.1 docker pull docker.elastic.co/kibana/kibana:5.5.1 docker pull docker.elastic.co/logstash/logstash:5.5.1 启动Elastic Search容器: docker run -p 9200:920
-
基于Docker快速搭建ELK的方法
[摘要] 本文基于自建的Docker平台速搭建一套完整的ELK系统,相关的镜像直接从Docker Hub上获取,可以快速实现日志的采集和分析检索. 准备镜像 获取ES镜像:docker pull elasticsearch:latest 获取kibana镜像:docker pull kibana:latest 获取logstash镜像:docker pull logstash:latest 启动Elasticsearch 官方镜像里面ES的配置文件保存在/usr/share/elasticsea
-

Docker构建ELK Docker集群日志收集系统
当我们搭建好Docker集群后就要解决如何收集日志的问题 ELK就提供了一套完整的解决方案 本文主要介绍使用Docker搭建ELK 收集Docker集群的日志 ELK简介 ELK由ElasticSearch.Logstash和Kiabana三个开源工具组成 Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等. Logstash是一个完全开源的工具,他可以对你的日志进行收集.过滤,并将
-
Docker-compose部署ELK的示例代码
环境 主机IP 192.168.0.9 Docker version 19.03.2 docker-compose version 1.24.0-rc1 elasticsearch version 6.6.1 kibana version 6.6.1 logstash version 6.6.1 一.ELK-dockerfile文件编写及配置文件 ● elasticsearch 1.elasticsearch-dockerfile FROM centos:latest ADD elasticse
-
使用Docker搭建ELK日志系统的方法示例
以下安装都是以 ~/ 目录作为安装根目录. ElasticSearch 下载镜像: $ sudo docker pull elasticsearch:5.5.0 运行ElasticSearch容器: $ sudo docker run -it -d -p 9200:9200 -p 9300:9300 \ -v ~/elasticsearch/data:/usr/share/elasticsearch/data \ --name myes elasticsearch:5.5.0 特别注意的是如果使
-
Docker安装ELK并实现JSON格式日志分析的方法
ELK是什么 ELK是elastic公司提供的一套完整的日志收集以及前端展示的解决方案,是三个产品的首字母缩写,分别是ElasticSearch.Logstash和Kibana. 其中Logstash负责对日志进行处理,如日志的过滤.日志的格式化等:ElasticSearch具有强大的文本搜索能力,因此作为日志的存储容器:而Kibana负责前端的展示. ELK搭建架构如下图: 加入了filebeat用于从不同的客户端收集日志,然后传递到Logstash统一处理. ELK的搭建 因为ELK是三个产
-
Slf4j+logback实现JSON格式日志输出方式
目录 Slf4j+logback实现JSON格式日志输出 依赖 logback 记录JSON日志 Slf4j+logback实现JSON格式日志输出 依赖 <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.8</version> <scope>provided</s
-
使用docker安装elk的详细步骤
目录 1.安装docker 2.下载elk 3.启动elk 3.启动elk 4.汉化 配置要求:一台Linux服务器,内存不少于2g,centos7以上系统 1.安装docker 安装教程:CentOS Docker 安装 | 菜鸟教程 分以下几个步骤(我只写我使用过的方式): curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun 安装 Docker Engine-Community yum install -y y
-
将List对象列表转换成JSON格式的类实现方法
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式.易于人阅读和编写.同时也易于机器解析和生成.它基于JavaScript Programming Language, Standard ECMA-262 3rd Edition - December 1999的一个子集. JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C, C++, C#, Java, JavaScript, Perl, Python等).这些特性使JSON
-
javascript将url解析为json格式的两种方法
本文介绍了javascript将url解析为json格式的两种方法,分享给大家,具体如下: 方法一:最简单的方法,利用a标签来实现 function parseUrl(url){ var a=document.createElement('a'); a.href=url; return { protocol:a.protocol.replace(':',''), hostname:a.hostname, port:a.port, path:a.pathname, query:(()=>{ var
-
JS获取url参数,JS发送json格式的POST请求方法
<script type="text/javascript"> 一.获取url所有参数值 function US() { var name, value; var str = location.href; var num = str.indexOf("?"); str = str.substr(num + 1); var arr = str.split("&"); for (var i = 0; i < arr.leng
-
php从数据库读取数据,并以json格式返回数据的方法
php中,从数据库读取数据,并以json格式返回数据.具体方法如下: 第一步,定义相关变量 $servername = "localhost"; $username = "root"; $password = "root"; $mysqlname = "datatest"; $json = ''; $data = array(); class User { public $id; public $fname; public $
-
python 提取tuple类型值中json格式的key值方法
标题比较麻烦,都有些叙述不清:昨天下午在调试接口框架的时候,遇到了一个问题是这样的: 使用python 写了一个函数,return 了两个返回值比如 return a,b 于是返回的a,b 是tuple类型,比如值是actual.那么,得到a,b分别是actual[0] ,actual[1]这样的.而目前,actual[0]的值是这样的: {"code":"m0001","result":True} ,但是我想得到code的key值 m0001
-
php将从数据库中获得的数据转换成json格式并输出的方法
如下所示: header('content-type:application/json;charset=utf8'); $results = array(); while ($row = mysql_fetch_assoc($result_query)) { $results[] = $row; } if($results){ echo json_encode($results); }else{ echo mysql_error(); } 将查询到的数组存放到一个新的数组中,然后返回json格式
-
docker 安装solr8.6.2 配置中文分词器的方法
一.环境版本 Docker version 19.03.12 centos7 solr8.6.2 二.docker安装 1.使用官方安装脚本自动安装 curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun 2.使用国内 daocloud 一键安装命令: curl -sSL https://get.daocloud.io/docker | sh 三.docker安装solr8.6.2 1.docker拉取solr doc