pandas 缺失值与空值处理的实现方法
1.相关函数
- df.dropna()
- df.fillna()
- df.isnull()
- df.isna()
2.相关概念
空值:在pandas中的空值是""
缺失值:在dataframe中为nan或者naT(缺失时间),在series中为none或者nan即可
3.函数具体解释
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
函数作用:删除含有空值的行或列
axis:维度,axis=0表示index行,axis=1表示columns列,默认为0
how:"all"表示这一行或列中的元素全部缺失(为nan)才删除这一行或列,"any"表示这一行或列中只要有元素缺失,就删除这一行或列
thresh:一行或一列中至少出现了thresh个才删除。
subset:在某些列的子集中选择出现了缺失值的列删除,不在子集中的含有缺失值得列或行不会删除(有axis决定是行还是列)
inplace:刷选过缺失值得新数据是存为副本还是直接在原数据上进行修改。
例子:
df = pd.DataFrame({"name": ['Alfred', 'Batman', 'Catwoman'],
"toy": [np.nan, 'Batmobile', 'Bullwhip'],
"born": [pd.NaT, pd.Timestamp("1940-04-25"),pd.NaT]})
print df

默认参数:删除行,只要有空值就会删除,不替换。
print df.dropna() print df

print "delete colums" print df.dropna(axis=1) #delete col

print "所有值全为缺失值才删除" print df.dropna(how='all')

print "至少出现过两个缺失值才删除" print df.dropna(thresh=2)

print "删除这个subset中的含有缺失值的行或列" print df.dropna(subset=['name', 'born'])

DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)
函数作用:填充缺失值
value:需要用什么值去填充缺失值
axis:确定填充维度,从行开始或是从列开始
method:ffill:用缺失值前面的一个值代替缺失值,如果axis =1,那么就是横向的前面的值替换后面的缺失值,如果axis=0,那么则是上面的值替换下面的缺失值。backfill/bfill,缺失值后面的一个值代替前面的缺失值。注意这个参数不能与value同时出现
limit:确定填充的个数,如果limit=2,则只填充两个缺失值。
示例:
df = pd.DataFrame([[np.nan, 2, np.nan, 0],
[3, 4, np.nan, 1],
[np.nan, np.nan, np.nan, 5],
[np.nan, 3, np.nan, 4]],
columns=list('ABCD'))
print df
print "横向用缺失值前面的值替换缺失值"
print df.fillna(axis=1,method='ffill')
print "纵向用缺失值上面的值替换缺失值"
print df.fillna(axis=0,method='ffill')
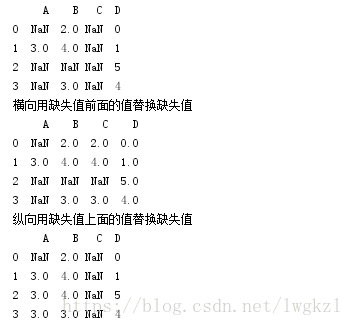
print df.fillna(0)
不同的列用不同的值填充:

对每列出现的替换值有次数限制,此处限制为一次

DataFrame.isna()
判断是不是缺失值:
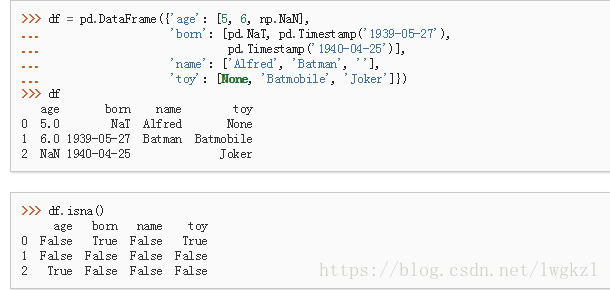
isnull同上。
替换空值:
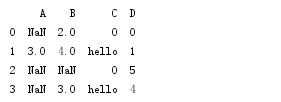
df = pd.DataFrame([[np.nan, 2, np.nan, 0],
[3, 4, "", 1],
[np.nan, np.nan, np.nan, 5],
[np.nan, 3, "", 4]],
columns=list('ABCD'))
print df

如上,缺失值是NAN,空值是没有显示。
替换空值代码:需要把含有空值的那一列提出来单独处理,然后在放进去就好。
clean_z = df['C'].fillna(0) clean_z[clean_z==''] = 'hello' df['C'] = clean_z print df
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python解决pandas处理缺失值为空字符串的问题
踩坑记录: 用pandas来做csv的缺失值处理时候发现奇怪BUG,就是excel打开csv文件,明明有的格子没有任何东西,当然,我就想到用pandas的dropna()或者fillna()来处理缺失值. 但是pandas读取csv文件后发现那个空的地方isnull()竟然是false,就是说那个地方有东西... 后来经过排查发现看似什么都没有的地方有空字符串,故pandas认为那儿不是缺失值,所以就不能用dropna()或者fillna()来处理. 解决思路:先用正则将空格匹配出来,然后全部替
-
Python Pandas对缺失值的处理方法
Pandas使用这些函数处理缺失值: isnull和notnull:检测是否是空值,可用于df和series dropna:丢弃.删除缺失值 axis : 删除行还是列,{0 or 'index', 1 or 'columns'}, default 0 how : 如果等于any则任何值为空都删除,如果等于all则所有值都为空才删除 inplace : 如果为True则修改当前df,否则返回新的df fillna:填充空值 value:用于填充的值,可以是单个值,或者字典(key是列名,valu
-
pandas如何处理缺失值
在实际应用中对于数据进行分析的时候,经常能看见缺失值,下面来介绍一下如何利用pandas来处理缺失值.常见的缺失值处理方式有,过滤.填充. 一.缺失值的判断 pandas使用浮点值NaN(Not a Number)表示浮点数和非浮点数组中的缺失值,同时python内置None值也会被当作是缺失值. a.Series的缺失值判断 s = Series(["a","b",np.nan,"c",None]) print(s) ''' 0 a 1 b 2
-
对Pandas DataFrame缺失值的查找与填充示例讲解
查看DataFrame中每一列是否存在空值: temp = data.isnull().any() #列中是否存在空值 print(type(temp)) print(temp) 结果如下,返回结果类型是Series,列中不存在空值则对应值为False: <class 'pandas.core.series.Series'> eventid False iyear False imonth False iday False approxdate True extended False reso
-
Python Pandas找到缺失值的位置方法
问题描述: python pandas判断缺失值一般采用 isnull(),然而生成的却是所有数据的true/false矩阵,对于庞大的数据dataframe,很难一眼看出来哪个数据缺失,一共有多少个缺失数据,缺失数据的位置. 首先对于存在缺失值的数据,如下所示 import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(10,6)) # Make a few areas have NaN values df.
-
Python3.5 Pandas模块缺失值处理和层次索引实例详解
本文实例讲述了Python3.5 Pandas模块缺失值处理和层次索引.分享给大家供大家参考,具体如下: 1.pandas缺失值处理 import numpy as np import pandas as pd from pandas import Series,DataFrame df3 = DataFrame([ ["Tom",np.nan,456.67,"M"], ["Merry",34,345.56,np.nan], [np.nan,np
-
pandas 使用均值填充缺失值列的小技巧分享
pd.DataFrame中通常含有许多特征,有时候需要对每个含有缺失值的列,都用均值进行填充,代码实现可以这样: for column in list(df.columns[df.isnull().sum() > 0]): mean_val = df[column].mean() df[column].fillna(mean_val, inplace=True) # -------代码分解------- # 判断哪些列有缺失值,得到series对象 df.isnull().sum() > 0
-
pandas 缺失值与空值处理的实现方法
1.相关函数 df.dropna() df.fillna() df.isnull() df.isna() 2.相关概念 空值:在pandas中的空值是"" 缺失值:在dataframe中为nan或者naT(缺失时间),在series中为none或者nan即可 3.函数具体解释 DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False) 函数作用:删除含有空值的行或列 axis:维度,axis=
-
简单了解Pandas缺失值处理方法
这篇文章主要介绍了简单了解Pandas缺失值处理方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 判断数据是否为NaN: pd.isnull(df), pd.notnull(df) 判断缺失值是否存在 np.all(pd.notnull(data)) # 返回false代表有空值 np.any(pd.isnull(data)) #返回true代表有空值 处理方式: 存在缺失值nan,并且是np.nan: 1.删除缺失值:dropna(axis
-
pandas数据清洗,排序,索引设置,数据选取方法
此教程适合有pandas基础的童鞋来看,很多知识点会一笔带过,不做详细解释 Pandas数据格式 Series DataFrame:每个column就是一个Series 基础属性shape,index,columns,values,dtypes,describe(),head(),tail() 统计属性Series: count(),value_counts(),前者是统计总数,后者统计各自value的总数 df.isnull() df的空值为True df.notnull() df的非空值为T
-

Pandas缺失值删除df.dropna()的使用
函数参数 函数形式:dropna(axis=0, how=‘any’, thresh=None, subset=None, inplace=False) 参数: axis:0或’index’,表示按行删除:1或’columns’,表示按列删除. how:‘any’,表示该行/列只要有一个以上的空值,就删除该行/列:‘all’,表示该行/列全部都为空值,就删除该行/列. thresh:int型,默认为None.如果该行/列中,非空元素数量小于这个值,就删除该行/列. subset:子集.列表,按c
-
Pandas缺失值填充 df.fillna()的实现
df.fillna主要用来对缺失值进行填充,可以选择填充具体的数字,或者选择临近填充. 官方文档 DataFrame.fillna(self, value=None, method=None, axis=None, inplace=False, limit=None, downcast=None) df.fillna(x)可以将缺失值填充为指定的值 import pandas as pd # 原数据 df = pd.DataFrame({'A':['a1','a1','a2','a2'], 'B
-
Python使用Pandas对csv文件进行数据处理的方法
今天接到一个新的任务,要对一个140多M的csv文件进行数据处理,总共有170多万行,尝试了导入本地的MySQL数据库进行查询,结果用Navicat导入直接卡死....估计是XAMPP套装里面全默认配置的MySQL性能不给力,又尝试用R搞一下吧结果发现光加载csv文件就要3分钟左右的时间,相当不给力啊,翻了翻万能的知乎发现了Python下的一个神器包:Pandas(熊猫们?),加载这个140多M的csv文件两秒钟就搞定,后面的分类汇总等操作也都是秒开,太牛逼了!记录一下这次数据处理的过程: 使用
-
Python使用pandas对数据进行差分运算的方法
如下所示: >>> import pandas as pd >>> import numpy as np # 生成模拟数据 >>> df = pd.DataFrame({'a':np.random.randint(1, 100, 10),\ 'b':np.random.randint(1, 100, 10)},\ index=map(str, range(10))) >>> df a b 0 21
-
Python Pandas模块实现数据的统计分析的方法
一.groupby函数 Python中的groupby函数,它主要的作用是进行数据的分组以及分组之后的组内的运算,也可以用来探索各组之间的关系,首先我们导入我们需要用到的模块 import pandas as pd 首先导入我们所需要用到的数据集 customer = pd.read_csv("Churn_Modelling.csv") marketing = pd.read_csv("DirectMarketing.csv") 我们先从一个简单的例子着手来看, c
-
Python Pandas读写txt和csv文件的方法详解
目录 一.文本文件 1. read_csv() 2. to_csv() 一.文本文件 文本文件,主要包括csv和txt两种等,相应接口为read_csv()和to_csv(),分别用于读写数据 1. read_csv() 格式代码: pandas.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False
-
pandas object格式转float64格式的方法
在数据处理过程中 比如从CSV文件中导入数据 data_df = pd.read_csv("names.csv") 在处理之前一定要查看数据的类型 data_df.info() *RangeIndex: 891 entries, 0 to 890 Data columns (total 12 columns): Name 891 non-null object Sex 891 non-null object Age 714 non-null float64 SibSp 891 non-