正解SQLSEVER 2005 sql排序(按大小排序)
今天在论坛上看到一个问题,如下:
解决这个问题,Insus.NET写了一个函数,可以方便以后的扩展,如果数值出现TB或是或更高时,可以只改这个函数即可。
代码如下:
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
ALTER FUNCTION [dbo].[udf_OrderLimitSize]
(
@Ov NVARCHAR(30)
)
RETURNS decimal(18,6)
AS
BEGIN
--如果长度少于等于2的数值为返回NULL
IF (LEN(@Ov) <= 2)
RETURN NULL
--宣告两个变量
DECLARE @v DECIMAL(18,6),@n DECIMAL(18,6)
--判断最后两位数是否为下面这些单位
IF (RIGHT(@Ov,2) NOT IN ('TB','GB','MB','KB'))
RETURN NULL
--去掉最后两位数之后,把值转为DECIMAL数据类型
SET @n = CONVERT(DECIMAL(18,6),LEFT(@Ov, LEN(@Ov) - 2))
--判断截除最后两位数之后,使用ISNUMERIC判断是否为有效的数值,如果不是返回NULL
IF (ISNUMERIC(@n) = 0)
RETURN NULL
--下面做单位转算,如果遇上有新单位时,可以作相应添加
IF (@Ov LIKE '%TB')
SET @v = @n * 1024 * 1024 * 1024
IF (@Ov LIKE '%GB')
SET @v = @n * 1024 * 1024
IF (@Ov LIKE '%MB')
SET @v = @n * 1024
IF (@Ov LIKE '%KB')
SET @v = @n
RETURN @v
END
CREATE TABLE test(id int identity(1,1),size NVARCHAR(50))
GO
INSERT INTO [test] values('23.5mb'),('10gb'),('12.7mb'),('8GB')
go
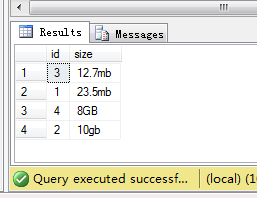
SELECT [id],[size] FROM test ORDER BY [dbo].[udf_OrderLimitSize]([size])
执行结果:
相关推荐
-

SQLSever导入数据图文方法
首先登录到远程数据库服务器:1. 右击您准备导入数据的数据库,选择"所有任务"下的"导入数据" 2. 进入DTS导入/导出向导,点击"下一步"按钮继续 3. 选择数据源,输入数据源所在的数据库服务器名称.用户名.密码和要复制数据的源数据库,点击"下一步"按钮 4. 选择目的,输入目的数据库所在的数据库服务器名称.用户名.密码和要复制数据的目的数据库,点击"下一步"按钮 5. 选择复制方式,一般选"
-
sqlsever实现更改字段名
新建表:create table [表名]([自动编号字段] int IDENTITY (1,1) PRIMARY KEY ,[字段1] nVarChar(50) default '默认值' null ,[字段2] ntext null ,[字段3] datetime,[字段4] money null ,[字段5] int default 0,[字段6] Decimal (12,4) default 0,[字段7] image null ,) 删除表:Drop table [表名] 插入数据:I
-
SQL Sever2008r2 数据库服务各种无法启动问题的解决办法(详解)
一.Sql Server服务远程过程调用失败解决 以前出现过这个问题,那时候是因为把实例安装在了D盘,后来D盘被格式化了.然后,这些就没了.今天早上打开电脑,竟然又出现这个问题,可是Server2008R2全部装在C盘了呢. 解决方法: 最后查找解决方法,发现故障原因为:安装Visual Studio 2012的时候,自动安装"Microsoft SQL Server 2012 Express LocalDB"服务,导致原本的SQL2008无法正常工作.那么解决方法如下: ①方法一:
-
SQL Sever 2005 Express 安装失败解决办法
后下载sql sever 2005 express单独安装,发现总是到了安装MSXML 6时出错.然而打算在控制面板里删除MSXML 6 Service Pack 2 (KB954459)又删不了,最后终于找到解决办法.详细见http://support.microsoft.com/kb/968749/zh-cn
-
SQL SEVER数据库重建索引的方法
一.查询思路 1.想要判断数据库查询缓慢的问题,可以使用如下语句,可以列出查询语句的平均时间,总时间,所用的CPU时间等信息 SELECT creation_time N'语句编译时间' ,last_execution_time N'上次执行时间' ,total_physical_reads N'物理读取总次数' ,total_logical_reads/execution_count N'每次逻辑读次数' ,total_logical_reads N'逻辑读取总次数' ,total_logic
-
正解SQLSEVER 2005 sql排序(按大小排序)
今天在论坛上看到一个问题,如下: 解决这个问题,Insus.NET写了一个函数,可以方便以后的扩展,如果数值出现TB或是或更高时,可以只改这个函数即可. 复制代码 代码如下: SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO ALTER FUNCTION [dbo].[udf_OrderLimitSize] ( @Ov NVARCHAR(30) ) RETURNS decimal(18,6) AS BEGIN --如果长度少于等于2的数值为返回NU
-
正解SQLSERVER 2005 sql排序(按大小排序)
今天在论坛上看到一个问题,如下: 解决这个问题,Insus.NET写了一个函数,可以方便以后的扩展,如果数值出现TB或是或更高时,可以只改这个函数即可. 复制代码 代码如下: SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO ALTER FUNCTION [dbo].[udf_OrderLimitSize] ( @Ov NVARCHAR(30) ) RETURNS decimal(18,6) AS BEGIN --如果长度少于等于2的数值为返回NU
-
sql获得当前时间以及SQL比较时间大小详解
目录 1. MySQL 2.Oracle 比较字符串类型的时间大小 总结 1. MySQL 1) MySQL中提供了NOW()函数,用于取得当前的日期时间,NOW()汗水.SYSDATE().CURRENT_TIMESTAMP()等别名如下: SELECT NOW(), SYSDATE(), CURRENT_TIMESTAMP 2) 如果想得到不包括时间部分的当前日期,则可以使用CURDATE()函数,CURDATE()函数还有CURRENT_DATE等别名.如下: SELECT CURDATE
-
详解MySQL中Order By排序和filesort排序的原理及实现
目录 1.Order By原理 2.filesort排序算法 3.优化排序 1.Order By原理 MySQL的Order By操作用于排序,并且会有多种不同的排序算法,他们的性能都是不一样的. 假设有一个表,建表的sql如下: CREATE TABLE `obtest` ( `id` BIGINT NOT NULL AUTO_INCREMENT, `a` VARCHAR ( 100 ) NOT NULL, `b` VARCHAR ( 100 ) NOT NULL, `c` VARCHAR (
-
Python3将ipa包中的文件按大小排序
给你个ipa包,解压前输出包大小,解压后把里面的文件按大小排序. 代码如下: import os import shutil import zipfile _ipa_zip_path = lambda ipa_path: ipa_path.replace('.ipa', '.zip') _file_size = lambda file_path: os.path.getsize(file_path) / 1024 / 1024 def unzip(zip_path: str) -> str: d
-
Spring data jpa的使用与详解(复杂动态查询及分页,排序)
一. 使用Specification实现复杂查询 (1) 什么是Specification Specification是springDateJpa中的一个接口,他是用于当jpa的一些基本CRUD操作的扩展,可以把他理解成一个spring jpa的复杂查询接口.其次我们需要了解Criteria 查询,这是是一种类型安全和更面向对象的查询.而Spring Data JPA支持JPA2.0的Criteria查询,相应的接口是JpaSpecificationExecutor. 而JpaSpecifica
-
Java中自然排序和比较器排序详解
前言 当指执行插入排序.希尔排序.归并排序等算法时,比较两个对象"大小"的比较操作.我们很容易理解整型的 i>j 这样的比较方式,但当我们对多个对象进行排序时,如何比较两个对象的"大小"呢?这样的比较 stu1 > stu2 显然是不可能通过编译的.为了解决如何比较两个对象大小的问题,JDK提供了两个接口 java.lang.Comparable 和 java.util.Comparator . 一.自然排序:java.lang.Comparable C
-
java字符串数组进行大小排序的简单实现
若是将两个字符串直接比较大小,会包:The operator > is undefined for the argument type(s) java.lang.String, java.lang.String的错误. 字符串比较大小可以用字符串长度或者是比较字符串内字符的ASCII码值,前者太简单,就不进行讲述记录. 字符串用ASCII码比较大小,规则是: 1.比较首字母的ASCII码大小 2.若是前面的字母相同,则比较之后的字母的ASCII码值 3.若是一个字符串从首字母开始包含另一个字符串
-
List集合对象中按照不同属性大小排序的实例
实例如下: package com.huad.luck; import java.util.ArrayList; import java.util.Collections; import java.util.Comparator; import java.util.List; public class Test { public static void main(String[] args) { Person p = new Person(); p.setName("tom"); p.
-
浅谈laravel框架sql中groupBy之后排序的问题
最近在用框架给公司App写接口时,碰到了一个棘手的问题: 对查询结果进行排序并进行分页(进行了简略修改),下面是最终结果代码: $example = Example::select(DB::raw('max(id) as some_id,this_id')) ->where('id', $id) ->groupBy('this_id') ->orderBy('some_id', 'desc') ->skip($offset) ->take($limit) ->get()