Python下载ts文件视频且合并的操作方法
目录
- 一、ts文件的由来
- 二、下载ts文件
- 1.下载index.m3u8,并做相应处理
- 2.下载ts文件
- 三、合并ts文件
- 参考文章:
一、ts文件的由来
ts文件,ts即"Transport Stream"的缩写,特点就是要求从视频流的任一片段开始都是可以独立解码的,非常适合网络视频播放。
打开网址:https://www.kan35.com/play/210314-3-1.html,要怎么才能把这个视频下载到电脑上呢?
按F12发现,这些视频被切割成无数个细小的片断,如图:
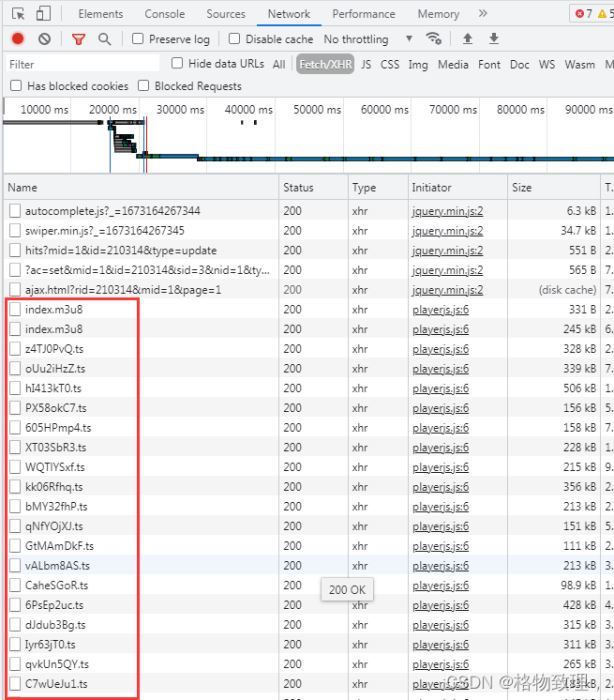
上图中,用红框圈出来的部分很重要,.ts的文件就是被切割的视频文件。但是这些视频文件名字全是乱的,没有规律。它们的顺序是通过index.m3u8实现的,上图中有两个index.m3u8文件,一般是尺寸更大的那个才是存放视频播放顺序的文件。可以在浏览器中打开看下:

可以看出,这个文件里面确实保存了ts文件播放顺序,当然一些其它的网站提供的index.m3u8文件格式会有些不一样,这些都可以后期处理。
二、下载ts文件
1.下载index.m3u8,并做相应处理
这个index.m3u8很重要,直接右键“Open in new tab”就可以下载下来,但是该怎么处理呢?
首先,了解下什么是m3u8:
m3u8是苹果公司推出的视频播放标准,是m3u的一种,只是编码格式采用的是UTF-8。
m3u8准确来说是一种索引文件,使用m3u8文件实际上是通过它来解析对应的放在服务器上的视频网络地址,从而实现在线播放。使用m3u8格式文件主要因为可以实现多码率视频的适配,视频网站可以根据用户的网络带宽情况,自动为客户端匹配一个合适的码率文件进行播放,从而保证视频的流畅度。
其次,怎么解析这个文件?
最简单的方式是复制里面的内容,然后在excel中筛选包含“https”的字符串。
当然,我们可以用更专业的方法,在python中用“pip install m3u8”安装这个模块,然后就可以用代码解析了。
import m3u8
data = m3u8.load("index0.m3u8").data
data
显示内容大概如下:
{'media_sequence': 0,
'is_variant': False,
'is_endlist': True,
'is_i_frames_only': False,
'is_independent_segments': False,
'playlist_type': 'vod',
'playlists': [],
'segments': [
{'duration': 2.667,
'title': '',
'uri': 'https://hey06.cjkypo.com/20211214/lIC8S3qZ1/1000kb/hls/MQJ9iKoM.ts',
'cue_in': False,
'cue_out': False,
'cue_out_start': False,
'scte35': None,
'oatcls_scte35': None,
'scte35_duration': None,
'scte35_elapsedtime': None,
'asset_metadata': None,
'discontinuity': False,
'dateranges': None,
'gap_tag': None},
{'duration': 1.667,
'title': '',
'uri': 'https://hey06.cjkypo.com/20211214/lIC83SqZ1/1000kb/hls/8LeDe7Wu.ts',
'cue_in': False,
'cue_out': False,
'cue_out_start': False,
'scte35': None,
'oatcls_scte35': None,
'scte35_duration': None,
'scte35_elapsedtime': None,
'asset_metadata': None,
'discontinuity': False,
'dateranges': None,
'gap_tag': None},
........................
可以看出,显示的内容很多,但是实际上只有“https://”那个字符串有用。
我们现在要做的是先提取每一个带“https”的字符串,然后还要提取出每个https字符串中的ts文件名。代码如下:
order_ts = []
#将所有的带https的url存入order_ts
for i in data["segments"]:
order_ts.append(i["uri"])
#返回一个dict,将文件名作为key,将url作为value
def read_name_url():
name_url = {}
for url in order_ts:
name = url.split("/")[-1]
name_url[name] = url
return name_url
这个dict内容大概如下:
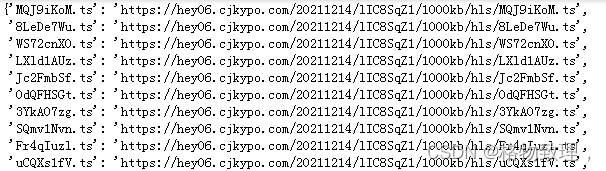
按理说,这个结果已经非常好了,但是我们还要进一步处理下,为我们最后一步的合并ts文件作准备。
list_name= read_name_url().keys()
file = open("order.m3u8", 'w')
for name in list_name:
file.write("file 'D:\\ProgramData\\study\\mov\\tsfiles\\" + name + "'")
file.write("\n")
这个order.m3u8文件的内容大概如下:
file 'D:\ProgramData\study\mov\tsfiles\MQJ9iKoM.ts'
file 'D:\ProgramData\study\mov\tsfiles\8LeDe7Wu.ts'
file 'D:\ProgramData\study\mov\tsfiles\WS72cnXO.ts'
file 'D:\ProgramData\study\mov\tsfiles\LXld1AUz.ts'
file 'D:\ProgramData\study\mov\tsfiles\Jc2FmbSf.ts'...........
2.下载ts文件
ts文件很小,只有几百k,所以一个完整的视频会被分成几千个ts文件,我们可以采用多线程的方式来下载:
import urllib
from concurrent.futures import ThreadPoolExecutor
def download(url,name):
#下载ts文件到D:\ProgramData\study\mov\tsfiles文件夹
urllib.request.urlretrieve(url,'D://ProgramData//study//mov//tsfiles//'+name)
def download_tsfile():
#记录创立的线程
task_list = []
dict_name_url = read_name_url()
#线程池的创立
pool = ThreadPoolExecutor(max_workers=50)
for name in dict_name_url:
# 启动多个线程下载文件,download是函数名,后面两个是参数值
task_list.append(pool.submit(download, dict_name_url[name],name))
# 判断所有下载线程是否全部结束
while (True):
if len(task_list) == 0:
break
for i in task_list:
if i.done():
task_list.remove(i)
print("剩下任务数:{0}".format(len(task_list)))
print("所有下载任务完成!")
下载完成后,就可以在tsfiles文件夹找到这些细小的文件:

三、合并ts文件
有了前面两步的铺垫,现在要进行最重要的一个步骤了,那就是按order.m3u8里面的顺序,依次把这些ts文件合并起来。该怎么合并呢?
我们需要借助ffmpeg这个工具,这个工具非常强大,专门用来处理音频、视频切割、合并、编辑等,当然也非常复杂。安装这个软件,可以点击后面参考文章中的第二篇文章,这里不细说。下面来说说怎么合并这些ts文件。
代码非常简单:
import os
def mixTss(name):
#string前面加上‘r',是为了告诉编译器这个string是个raw string,不要转义 backslash '\' 。
com = r'D:\\ffmpeg\\bin\\ffmpeg.exe -f concat -safe 0 -i D:\\ProgramData\\study\\mov\\order.m3u8 -c copy D:\\ProgramData\\study\\mov\\{}.mp4'.format(name)
os.system(com)
mixTss("hello")
print("合并完成!")
可以看出上面的代码中,最重要的就是执行了一命令:
D:\ffmpeg\bin\ffmpeg.exe -f concat -safe 0 -i D:\ProgramData\study\mov\order.m3u8 -c copy D:\ProgramData\\study\\mov\\hello.mp4
ffmpeg很强大,但是也比较复杂,我也不是很懂这个,大概解释如下。
ffmpeg使用语法:
命令格式: ffmpeg -i [输入文件名] [参数选项] -f [格式] [输出文件] ffmpeg [[options][`-i' input_file]]... {[options] output_file}...
具体一点来说:
1. -f concat,-f 一般设置输出文件的格式,如-f psp(输出psp专用格式),但是如果跟concat,则表示采用concat协议,对文件进行连接合并。
2. -safe 0,用于忽略一些文件名错误,如长路径、空格、非ANSIC字符
3. -i D:\ProgramData\study\mov\order.m3u8,-i后面加输入文件名,当然也可以加输入文件名组成的文件名,即order.m3u8,但是要满足文件格式,即类似于下面这种:
file 'D:\ProgramData\study\mov\tsfiles\MQJ9iKoM.ts'
file 'D:\ProgramData\study\mov\tsfiles\8LeDe7Wu.ts'
4. -c copy D:\ProgramData\\study\\mov\\hello.mp4,-c表示输出文件采用的编码器,后面跟copy,表示不重新编码。
参考文章:
到此这篇关于Python下载ts文件视频且合并的文章就介绍到这了,更多相关Python下载ts文件内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python如何将文件a.txt的内容复制到b.txt中
目录 python将a.txt的内容复制到b.txt 中 python合并多个txt中的内容到一个txt中 总结 python将a.txt的内容复制到b.txt 中 # 1. 用r方式打开a.txt f = open("a.txt","r") # 2. 读取a.txt的内容 buf = f.read() # 3. 关闭a.txt f.close # 4. 用w或者a的方式打开b.txt f = open("b.txt","w"
-
Python实现身份证前六位地区码对照表文件
目录 一.身份证json数据文件 二.python 读取json源码 1.生成了身份证前六位地区码对照表JSON文件 2.python 读取JSON文件 提取码[3297] json文件下载 废话不多说,先上效果图 一.身份证json数据文件 先去百度搜索地区身份证号码前6位查询 ,然后进入网站控制台界面,复制下方的数据,并保存到[1.txt]文件内 然后我们新疆一个py文件,用来处理数据,源码如下:就不一一讲解了 import json import re G = {} F = open('2
-
Python跨文件调用函数以及在一个文件中执行另一个文件
目录 一.项目简介 二.调用类型 1.调用同文件中的函数 2.调用同目录下不同文件中的函数 3.调用同级文件夹文件中的函数 4.调用上一级文件夹文件中的函数 5.调用上一级文件夹子文件夹下文件中的函数 6.执行另一个文件 三.概念区分 总结 一.项目简介 假如现在有这样一个文件树(从其他地方copy的,稍加整改) A |-------- __init__.py |-------- a.py |-------- main.py |-------- B |------
-
如何利用Python将html转为pdf、word文件
目录 前言 转 pdf 安装 pdfkit 库 安装 wkhtmltopdf 文件 url 生成 pdf 本地 html 文件生成 pdf 转 word 安装 pypandoc 库 安装 pandoc 软件 使用 补充:用python把pdf文件转换为word文件 总结 前言 在日常中有时需将 html 文件转换为 pdf.word 文件.网上免费的大多数不支持多个文件转换的情况,而且在转换几个后就开始收费了. 转 pdf 转 pdf 中使用 pdfkit 库,它可以让 web 网页直接转为 p
-
Python小程序编程实现一键自动整理文件解压文件
目录 前言 一.小程序构建思路 1.需求 2.技术 二.编程实现 1.引入库 2.窗口调整 3.选择目录 前言 什么是效率?简单就是效率!但是想要自己做的小程序足够美观可不是一件简单的事.一开始想做个小程序思路就是有个普通的button,一键使用就好了.但是写下来还是发现没用前端和结构话的编程后期维护很麻烦,所以以后的程序格式都应该尽量符合业界规范.世界上那么多种解决问题的方法,为什么大家都认可那么一两钟?肯定是有他的道理的.好了废话不多说,现在开始设计我们的小程序. 一.小程序构建思路 1.需
-
Python下载ts文件视频且合并的操作方法
目录 一.ts文件的由来 二.下载ts文件 1.下载index.m3u8,并做相应处理 2.下载ts文件 三.合并ts文件 参考文章: 一.ts文件的由来 ts文件,ts即"Transport Stream"的缩写,特点就是要求从视频流的任一片段开始都是可以独立解码的,非常适合网络视频播放. 打开网址:https://www.kan35.com/play/210314-3-1.html,要怎么才能把这个视频下载到电脑上呢? 按F12发现,这些视频被切割成无数个细小的片断,如图: 上图中
-

Python下载手机小视频的操作方法
目录 启动 mitmproxy 手机网络配置 下载页 编写下载脚本 今天为大家介绍使用 mitmproxy 这个抓包工具如何监控手机上网,并且通过抓包,把我们想要的数据下载下来. 启动 mitmproxy 首先我们通过执行命令 mitmweb 启动mitmproxy,让它处理监听状态,服务会监听本机 8080 端口,启动后如下: $ mitmweb Web server listening at http://127.0.0.1:8081/ Proxy server listening at h
-
教你如何使用Python下载B站视频的详细教程
前言 众所周知,网页版的B站无法下载视频,然本人喜欢经常在B站学习,奈何没有网时,无法观看视频资源,手机下载后屏幕太小又不想看,遂写此程序以解决此问题 步骤 话不多说,进入正题 1.在电脑上下载python的开发环境,点一下,观看具体步骤 2.下载pycharm开发工具,点一下观看具体步骤 3.同时按键盘上的win键与r键,在弹出的对话框中输入cmd 点击确定进入cmd命令行,在里面输入pip install you-get,之后按键盘enter键,进行you-get的下载,下载完后退出cmd
-
python实现大文件分割与合并
很多时候我们会面临大文件无法加载到内存,或者要传输大文件的问题.这时候就需要考虑将大文件分割为小文件进行处理了. 下面是一种用python分割与合并分件的实现. import os FILE_DIR = os.path.dirname(os.path.abspath(__file__)) #======================================================== # 文件操作 #=======================================
-
python 实现多线程下载m3u8格式视频并使用fmmpeg合并
电影之类的长视频好像都用m3u8格式了,这就导致了多线程下载视频的意义不是很大,都是短视频,线不线程就没什么意义了嘛. 我们知道,m3u8的链接会下载一个文档,相当长,半小时的视频,应该有接近千行ts链接. 这些ts链接下载成ts文件,就是碎片化的视频,加以合并,就成了需要的视频. 那,即便网速很快,下几千行视频,效率也就低了,更何况还要合并.我就琢磨了一下午,怎么样才能多线程下载m3u8格式的视频呢? 先上代码,再说重难点: import datetime import os import r
-
Python合并ts文件至mp4格式及解密教程详解
m3u8是什么格式?m3u8是苹果公司推出的视频播放标准,是m3u的一种,只是编码格式采用的是UTF-8. 使用m3u8格式文件主要因为可以实现多码率视频的适配,视频网站可以根据用户的网络带宽情况,自动为客户端匹配一个合适的码率文件进行播放,从而保证视频的流畅度. m3u8准确来说是一种索引文件,使用m3u8文件实际上是通过它来解析对应的放在服务器上的视频网络地址,从而实现在线播放. 它将视频切割成一小段一小段的ts格式的视频文件,然后存在服务器中(现在为了减少I/o访问次数,一般存在服务器的内
-
使用Python下载抖音各大V视频的思路详解
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 以下文章来源于Python七号 ,作者 somenzz Python爬虫.数据分析.网站开发等案例教程视频免费在线观看 https://space.bilibili.com/523606542 上次写了用 Python 批量下载知乎视频的方式,这次分享用 Python 批量下载抖音个人主页的全部无水印视频,本文重点不是提供一个好用的脚本,而是讲述如何写出这样的脚本,正所谓授人以鱼,不如授人
-
教你用Python下载抖音无水印视频
一.获取抖音视频连接 得到如下信息: "5.1 HV:/ 守门员戴手套没法系鞋带这种体育精神,值得尊敬%遇见足球 %足球 %精彩进球 %意甲 %唯有足球不 https://v.douyin.com/eDFd28P/ 复制此链接,打开Dou音搜索,直接观看视频!" 通过正则取到信息中的地址: share_url='5.1 HV:/ 守门员戴手套没法系鞋带这种体育精神,值得尊敬%遇见足球 %足球 %精彩进球 %意甲 %唯有足球不 https://v.douyin.com/eDFd28P/
-
python爬取基于m3u8协议的ts文件并合并
前言 简单学习过网络爬虫,只是之前都是照着书上做并发,大概能理解,却还是无法自己用到自己项目中,这里自己研究实现一个网页嗅探HTML5播放控件中基于m3u8协议ts格式视频资源的项目,并未考虑过复杂情况,毕竟只是练练手. 源码 # coding=utf-8 import asyncio import multiprocessing import os import re import time from math import floor from multiprocessing import
-
Python爬虫爬取ts碎片视频+验证码登录功能
目标:爬取自己账号中购买的课程视频. 一.实现登录账号 这里采用的是手动输入验证码的方式,有能力的盆友也可以通过图像识别的方式自动填写验证码.登录后,采用session保持登录. 1.获取验证码地址 第一步:首先查看验证码对应的代码,可以从图中看到验证码图片的地址是:https://per.enetedu.com/Common/CreateImage?tmep_seq=1613623257608 颜色标红的部分tmep_seq=1613623257608,是为了解决浏览器缓存问题加的时间戳,因此