SpringCloud Sleuth实现分布式请求链路跟踪流程详解
目录
- 1、概念
- 2、搭建链路监控步骤
- 2.1、zipkin
- 2.2、服务提供者
- 2.3、服务消费者(调用方)
1、概念
Git官网地址:https://github.com/spring-cloud/spring-cloud-sleuth
官网地址:https://spring.io/projects/spring-cloud-sleuth
在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的的服务节点调用来协同产生最后的请求结果,每一个前段请求都会形成一条复杂的分布式服务调用链路,链路中的任何一环出现高延时或错误都会引起整个请求最后的失败。
Spring Cloud Sleuth提供了一套完整的服务跟踪的解决方案,在分布式系统中提供追踪解决方案并且兼容支持了zipkin

2、搭建链路监控步骤
2.1、zipkin
官方地址:https://zipkin.io/
下载地址:https://gitcode.net/mirrors/openzipkin/zipkin?utm_source=csdn_github_accelerator

通过命令启动
需要定位到当前目录下
java -jar zipkin-server-2.23.18-exec.jar

浏览器访问:http://127.0.0.1:9411/
监控流程
一条链路通过Trace Id唯一标识,Span标识发起的请求信息,各span通过parent id 关联起来

整个链路的依赖关系:服务一 调用 服务二 ,服务二又分别调用服务三或四

2.2、服务提供者
修改cloud-provider-payment8001服务提供者模块
1、引入pom.xml依赖
<!--包含了sleuth+zipkin-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
2、添加YAMLA配置文件
spring:
application:
name: cloud-payment-service # 指定程序名称
zipkin: # 链路跟踪
base-url: http://localhost:9411 # 跟踪后展示的地址
sleuth:
sampler:
#采样率值介于 0 到 1 之间,1 则表示全部采集,一般采用0.5
probability: 1
3、业务类实现
在8001PaymentController控制器上面添加有个简单的接口,方便链路进行跟踪
/**
* 请求链路跟踪测试
* @return
*/
@GetMapping("/zipkin")
public String paymentZipkin()
{
return "hi ,i'am paymentzipkin server fall back,welcome to atguigu,O(∩_∩)O哈哈~";
}
4、启动项目
- 启动7001
- 启动8001
2.3、服务消费者(调用方)
修改cloud-consumer-order80消费者模块
引入依赖
与提供者一样
添加YAML配置文件
spring:
application:
name: cloud-order-service # 程序名称
zipkin: # 链路跟踪
base-url: http://localhost:9411 # 监控展示地址
sleuth:
sampler:
probability: 1 # 采样率
添加控制器
// ====================> zipkin+sleuth
/**
* 调用链路跟踪服务接口
* @return
*/
@GetMapping("/payment/zipkin")
public String paymentZipkin()
{
String result = restTemplate.getForObject("http://localhost:8001"+"/payment/zipkin/", String.class);
return result;
}
启动测试
之前启动了7001、8001
启动当前项目80
页面访问:http://localhost/consumer/payment/zipkin
多点击几次产生链路,然后查看链路
查看链路跟踪
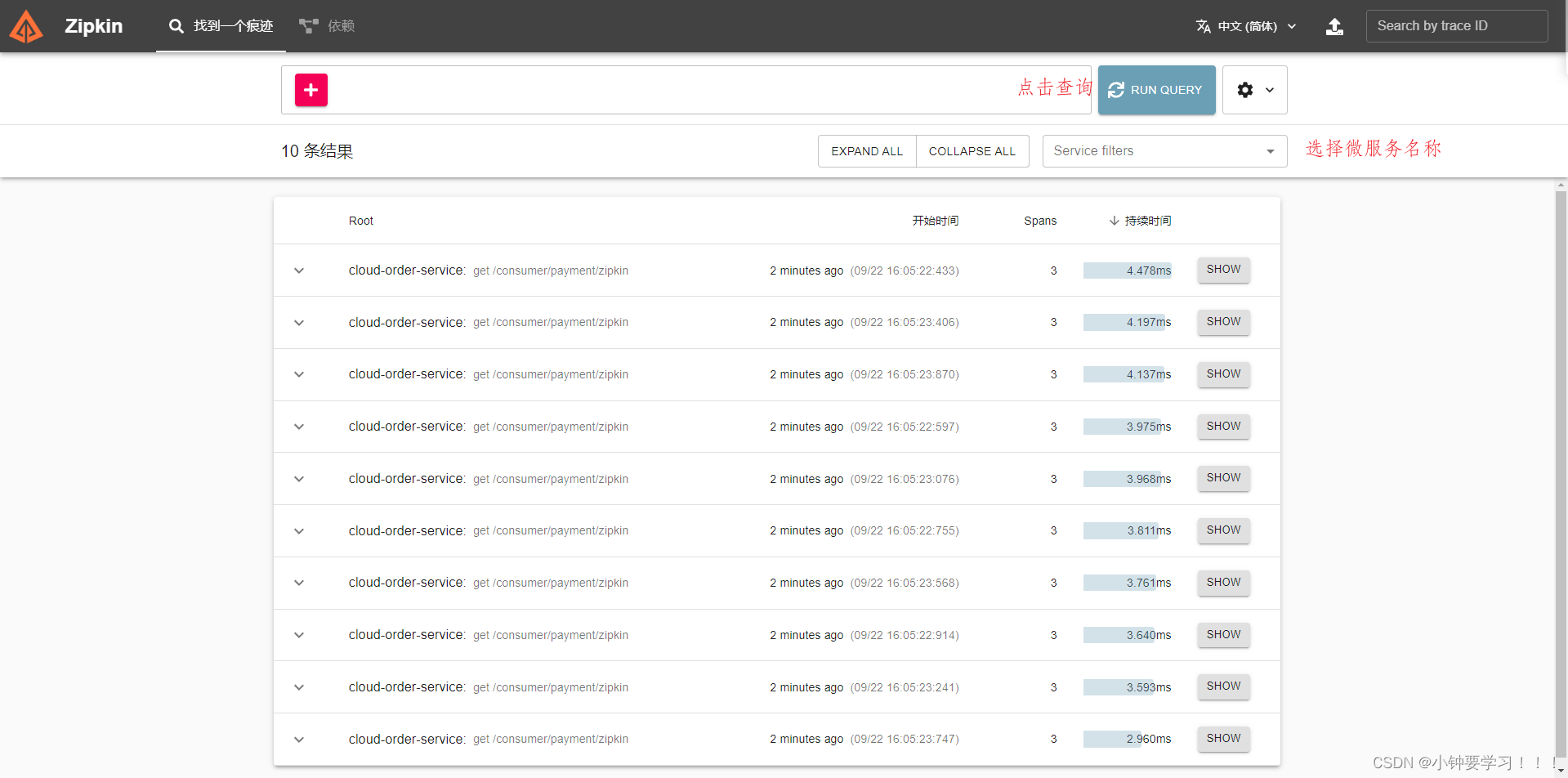
链路详情

到此这篇关于SpringCloud Sleuth实现分布式请求链路跟踪流程详解的文章就介绍到这了,更多相关SpringCloud Sleuth内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
SpringCloud_Sleuth分布式链路请求跟踪的示例代码
目录 一.概述 1.为什么会出现这个技术?需要解决哪些问题? 2.是什么 3.解决 二.搭建链路监控步骤 1.zipkin 2.服务提供者 3.服务消费者(调用方) 4.依次启动eureka7001/8001/80 Spring Cloud Sleuth是一款针对Spring Cloud的分布式跟踪工具.它借鉴了Dapper.Zipkin和HTrace. 特点 将trace Id和 span Id 添加到Slf4J MDC,这样就可以在日志聚合器中从给定的trace或span提取所有日志. 提供
-
java分治思想之ForkJoin详解
目录 前言 分治思想算法 归并排序 快速排序 Fork/Join ForkJoinPool 构造器 工作窃取法 使用 前言 当我们面对需要同时执行多个任务的情况时,往往需要耗费大量的时间和精力来编写复杂的并发代码.但是有一种技术可以帮助我们轻松地处理这种情况.通过forkJoin,我们可以简单地实现多个任务的并行执行,从而提高应用程序的性能和响应能力.在本文中,我们将深入探讨forkJoin的工作原理和使用方法. 分治思想算法 fork-join模式是基于分治思想的并行计算模式之一.该模
-

Spring Cloud Sleuth 和 Zipkin 进行分布式跟踪使用小结
目录 什么是分布式跟踪? 分布式跟踪的关键概念 带有SpringCloudSleuth的SpringBoot示例 使用Zipkin可视化跟踪 分布式跟踪允许您跟踪分布式系统中的请求.本文通过了解如何使用 Spring Cloud Sleuth 和 Zipkin 来做到这一点. 对于一个做所有事情的大型应用程序(我们通常将其称为单体应用程序),跟踪应用程序内的传入请求很容易.我们可以跟踪日志,然后弄清楚请求是如何处理的.除了应用程序日志本身之外,我们无需查看其他任何内容. 随着时间的推移,单体应用
-
微服务链路追踪Spring Cloud Sleuth整合Zipkin解析
目录 前言 何为调用链路 Zipkin + Sleuth Zipkin Spring Cloud Sleuth Zipkin启动 引入jar 服务调用测试 总结 前言 如果在开发过程中,你还在靠查看服务器日志来寻找服务与服务之间的报错信息,那么这篇一定要来看下,通常在我们开发环境自测的时候,我们会将代码发布到开发环境,然后无论是通过postMan请求,还是通过页面请求,遇到报错的信息,我们都会去服务器上去看时实的日志,来寻找报错信息: 如果涉及到多个服务调用,这个时候会登陆多个服务器去查看服务的
-
Spring Cloud 专题之Sleuth 服务跟踪实现方法
目录 准备工作 实现跟踪 抽样收集 整合Zipkin 1.下载Zipkin 2.引入依赖配置 3.测试与分析 持久化到mysql 1.创建zipkin数据库 2.启动zipkin 3.测试与分析 在一个微服务架构中,系统的规模往往会比较大,各微服务之间的调用关系也错综复杂.通常一个有客户端发起的请求在后端系统中会经过多个不同的微服务调用阿里协同产生最后的请求结果.在复杂的微服务架构中,几乎每一个前端请求都会形成一条复杂的分布式的服务调用链路,在每条链路中任何一个依赖服务出现延迟过高或错误的时候都
-
SpringCloud注册中心部署Eureka流程详解
目录 1.Eureka服务 2.服务提供者 3.服务消费者 4.服务调用测试 今天我们开始正式编码,如何创建spring boot项目这篇文章就不再讲述,如果想要了解可以阅读我之前的创建springboot项目. 首先我们先进行Spring cloud五大组件之一的注册中心,之前文章已经讲过注册中心的介绍,今天我们来部署Netflix的Eureka,进行单机部署以及高可用部署,并开发生产者以及消费者来进行测试eureka的注册消费.(ps:系列文章使用的Spring cloud版本为2021.0
-
Hadoop 分布式存储系统 HDFS的实例详解
HDFS是Hadoop Distribute File System 的简称,也就是Hadoop的一个分布式文件系统. 一.HDFS的优缺点 1.HDFS优点: a.高容错性 .数据保存多个副本 .数据丢的失后自动恢复 b.适合批处理 .移动计算而非移动数据 .数据位置暴露给计算框架 c.适合大数据处理 .GB.TB.甚至PB级的数据处理 .百万规模以上的文件数据 .10000+的节点 d.可构建在廉价的机器上 .通过多副本存储,提高可靠性 .提供了容错和恢复机制 2.HDFS缺点 a.低延迟数
-
jmeter接口测试教程及接口测试流程详解(全网仅有)
目录 一.Jmeter简介 二.Jmeter安装 三.设置Jmeter语言为中文环境 四.Jmeter主要元件 五.Jmeter元件的作用域和执行顺序 六.Jmeter进行接口测试流程 七.Jmeter进行接口测试流程步骤详解 八.Jmeter接口测试必定用到的扩展阅读 一.Jmeter简介 Jmeter是由Apache公司开发的一个纯Java的开源项目,即可以用于做接口测试也可以用于做性能测试. Jmeter具备高移植性,可以实现跨平台运行. Jmeter可以实现分布式负载. Jmeter采用
-
Redis Sentinel服务配置流程(详解)
1.Redis Sentinel服务配置 1.1简介 Redis 的 Sentinel 系统用于管理多个 Redis 服务器(instance), 该系统执行以下三个任务: 监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常. 提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过API 向管理员或者其他应用程序发送通知. 自动故障迁移(Automatic failover): 当一个主服务器不
-
Android Bluetooth蓝牙技术使用流程详解
在上篇文章给大家介绍了Android Bluetooth蓝牙技术初体验相关内容,感兴趣的朋友可以点击了解详情. 一:蓝牙设备之间的通信主要包括了四个步骤 设置蓝牙设备 寻找局域网内可能或者匹配的设备 连接设备 设备之间的数据传输 二:具体编程实现 1. 启动蓝牙功能 首先通过调用静态方法getDefaultAdapter()获取蓝牙适配器BluetoothAdapter,如果返回为空,则无法继续执行了.例如: BluetoothAdapter mBluetoothAdapter = Blueto
-
MVC+DAO设计模式下的设计流程详解
DAO设计 : DAO层主要是做数据持久层的工作,负责与数据库进行联络的一些任务都封装在此,DAO层的设计首先是设计DAO的接口,然后在Spring的配置文件中定义此接口的实现类,然后就可在模块中调用此接口来进行数据业务的处理,而不用关心此接口的具体实现类是哪个类,显得结构非常清晰,DAO层的数据源配置,以及有关数据库连接的参数都在Spring的配置文件中进行配置. 在该层主要完成对象-关系映射的建立,通过这个映射,再通过访问业务对象即可实现对数据库的访问,使得开发中不必再用SQL语句编写复杂的
-
微信小程序支付及退款流程详解
首先说明一下,微信小程序支付的主要逻辑集中在后端,前端只需携带支付所需的数据请求后端接口然后根据返回结果做相应成功失败处理即可.我在后端使用的是php,当然在这篇博客里我不打算贴一堆代码来说明支付的具体实现,而主要会侧重于整个支付的流程和一些细节方面的东西.所以使用其他后端语言的朋友有需要也是可以看一下的.很多时候开发的需求和相应问题的解决真的要跳出语言语法层面,去从系统和流程的角度考虑.好的,也不说什么废话了.进入正题. 一. 支付 支付主要分为几个步骤: 前端携带支付需要的数据(商品id,购
-
Redis实现分布式Session管理的机制详解
一. Redis实现分布式Session管理 1. Memcached管理机制 2. Redis管理机制 1.redis的session管理是利用spring提供的session管理解决方案,将一个应用session交给Redis存储,整个应用中所有session的请求都会去redis中获取对应的session数据. 二. SpringBoot项目开发Session管理 1. 引入依赖pop.xml <!--springboot-redis--> <dependency> <
-
Android zygote启动流程详解
对zygote的理解 在Android系统中,zygote是一个native进程,是所有应用进程的父进程.而zygote则是Linux系统用户空间的第一个进程--init进程,通过fork的方式创建并启动的. 作用 zygote进程在启动时,会创建一个Dalvik虚拟机实例,每次孵化新的应用进程时,都会将这个Dalvik虚拟机实例复制到新的应用程序进程里面,从而使得每个应用程序进程都有一个独立的Dalvik虚拟机实例. zygote进程的主要作用有两个: 启动SystemServer. 孵化应用
-
SpringMvc框架的简介与执行流程详解
目录 一.SpringMvc框架简介 1.Mvc设计理念 2.SpringMvc简介 二.SpringMvc执行流程 1.流程图解 2.步骤描述 3.核心组件 三.整合Spring框架配置 1.spring-mvc配置 2.Web.xml配置 3.测试接口 4.常用注解说明 四.常见参数映射 1.普通映射 2.指定参数名 3.数组参数 4.Map参数 5.包装参数 6.Rest风格参数 五.源代码地址 一.SpringMvc框架简介 1.Mvc设计理念 M:代表模型Model 模型就是数据,应用