Go语言k8s kubernetes使用leader election实现选举
目录
- 一、背景
- 二、官网代码示例
- 三、锁的实现
一、背景
在kubernetes的世界中,很多组件仅仅需要一个实例在运行,比如controller-manager或第三方的controller,但是为了高可用性,需要组件有多个副本,在发生故障的时候需要自动切换。因此,需要利用leader election的机制多副本部署,单实例运行的模式。应用程序可以使用外部的组件比如ZooKeeper或Etcd等中间件进行leader eleaction, ZooKeeper的实现是采用临时节点的方案,临时节点存活与客户端与ZooKeeper的会话期间,在会话结束后,临时节点会被立刻删除,临时节点被删除后,其他处于被动状态的服务实例会竞争生成临时节点,生成临时节点的客户端(服务实例)就变成Leader,从而保证整个集群中只有一个活跃的实例,在发生故障的时候,也能快速的实现主从之间的迁移。Etcd是一个分布式的kv存储组件,利用Raft协议维护副本的状态服务,Etcd的Revision机制可以实现分布式锁的功能,Etcd的concurrency利用的分布式锁的能力实现了选Leader的功能(本文更多关注的是k8s本身的能力,Etcd的concurrency机制不做详细介绍)。
kubernetes使用的Etcd作为底层的存储组件,因此我们是不是有可能利用kubernetes的API实现选leader的功能呢?其实kubernetes的SIG已经提供了这方面的能力,主要是通过configmap/lease/endpoint的资源实现选Leader的功能。
二、官网代码示例
kubernetes官方提供了一个使用的例子,源码在:github.com/kubernetes/…
选举的过程中,每个实例的状态有可能是:
- 选择成功->运行业务代码
- 等待状态,有其他实例成为了leader。当leader放弃锁后,此状态的实例有可能会成为新的leader
- 释放leader的锁,在运行的业务代码退出
在稳定的环境中,实例一旦成为了leader,通常情况是不会释放锁的,会保持一直运行的状态,这样有利于业务的稳定和Controller快速的对资源的状态变化做成相应的操作。只有在网络不稳定或误操作删除实例的情况下,才会触发leader的重新选举。
kubernetes官方提供的选举例子详解如下:
package main
import (
"context"
"flag"
"os"
"os/signal"
"syscall"
"time"
"github.com/google/uuid"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
clientset "k8s.io/client-go/kubernetes"
"k8s.io/client-go/rest"
"k8s.io/client-go/tools/clientcmd"
"k8s.io/client-go/tools/leaderelection"
"k8s.io/client-go/tools/leaderelection/resourcelock"
"k8s.io/klog/v2"
)
func buildConfig(kubeconfig string) (*rest.Config, error) {
if kubeconfig != "" {
cfg, err := clientcmd.BuildConfigFromFlags("", kubeconfig)
if err != nil {
return nil, err
}
return cfg, nil
}
cfg, err := rest.InClusterConfig()
if err != nil {
return nil, err
}
return cfg, nil
}
func main() {
klog.InitFlags(nil)
var kubeconfig string
var leaseLockName string
var leaseLockNamespace string
var id string
// kubeconfig 指定了kubernetes集群的配置文文件路径
flag.StringVar(&kubeconfig, "kubeconfig", "", "absolute path to the kubeconfig file")
// 锁的拥有者的ID,如果没有传参数进来,就随机生成一个
flag.StringVar(&id, "id", uuid.New().String(), "the holder identity name")
// 锁的ID,对应kubernetes中资源的name
flag.StringVar(&leaseLockName, "lease-lock-name", "", "the lease lock resource name")
// 锁的命名空间
flag.StringVar(&leaseLockNamespace, "lease-lock-namespace", "", "the lease lock resource namespace")
// 解析命令行参数
flag.Parse()
if leaseLockName == "" {
klog.Fatal("unable to get lease lock resource name (missing lease-lock-name flag).")
}
if leaseLockNamespace == "" {
klog.Fatal("unable to get lease lock resource namespace (missing lease-lock-namespace flag).")
}
// leader election uses the Kubernetes API by writing to a
// lock object, which can be a LeaseLock object (preferred),
// a ConfigMap, or an Endpoints (deprecated) object.
// Conflicting writes are detected and each client handles those actions
// independently.
config, err := buildConfig(kubeconfig)
if err != nil {
klog.Fatal(err)
}
// 获取kubernetes集群的客户端,如果获取不到,就抛异常退出
client := clientset.NewForConfigOrDie(config)
// 模拟Controller的逻辑代码
run := func(ctx context.Context) {
// complete your controller loop here
klog.Info("Controller loop...")
// 不退出
select {}
}
// use a Go context so we can tell the leaderelection code when we
// want to step down
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
// listen for interrupts or the Linux SIGTERM signal and cancel
// our context, which the leader election code will observe and
// step down
// 处理系统的系统,收到SIGTERM信号后,会退出进程
ch := make(chan os.Signal, 1)
signal.Notify(ch, os.Interrupt, syscall.SIGTERM)
go func() {
<-ch
klog.Info("Received termination, signaling shutdown")
cancel()
}()
// we use the Lease lock type since edits to Leases are less common
// and fewer objects in the cluster watch "all Leases".
// 根据参数,生成锁。这里使用的Lease这种类型资源作为锁
lock := &resourcelock.LeaseLock{
LeaseMeta: metav1.ObjectMeta{
Name: leaseLockName,
Namespace: leaseLockNamespace,
},
// 跟kubernetes集群关联起来
Client: client.CoordinationV1(),
LockConfig: resourcelock.ResourceLockConfig{
Identity: id,
},
}
// start the leader election code loop
// 注意,选举逻辑启动时候,会传入ctx参数,如果ctx对应的cancel函数被调用,那么选举也会结束
leaderelection.RunOrDie(ctx, leaderelection.LeaderElectionConfig{
// 选举使用的锁
Lock: lock,
// IMPORTANT: you MUST ensure that any code you have that
// is protected by the lease must terminate **before**
// you call cancel. Otherwise, you could have a background
// loop still running and another process could
// get elected before your background loop finished, violating
// the stated goal of the lease.
//主动放弃leader,当ctx canceled的时候
ReleaseOnCancel: true,
LeaseDuration: 60 * time.Second, // 选举的任期,60s一个任期,如果在60s后没有renew,那么leader就会释放锁,重新选举
RenewDeadline: 15 * time.Second, // renew的请求的超时时间
RetryPeriod: 5 * time.Second, // leader获取到锁后,renew leadership的间隔。非leader,抢锁成为leader的间隔(有1.2的jitter因子,详细看代码)
// 回调函数的注册
Callbacks: leaderelection.LeaderCallbacks{
// 成为leader的回调
OnStartedLeading: func(ctx context.Context) {
// we're notified when we start - this is where you would
// usually put your code
// 运行controller的逻辑
run(ctx)
},
OnStoppedLeading: func() {
// we can do cleanup here
// 退出leader的
klog.Infof("leader lost: %s", id)
os.Exit(0)
},
OnNewLeader: func(identity string) {
// 有新的leader当选
// we're notified when new leader elected
if identity == id {
// I just got the lock
return
}
klog.Infof("new leader elected: %s", identity)
},
},
})
}
启动一个实例,观察日志输出和kubernetes集群上的lease资源,启动命令
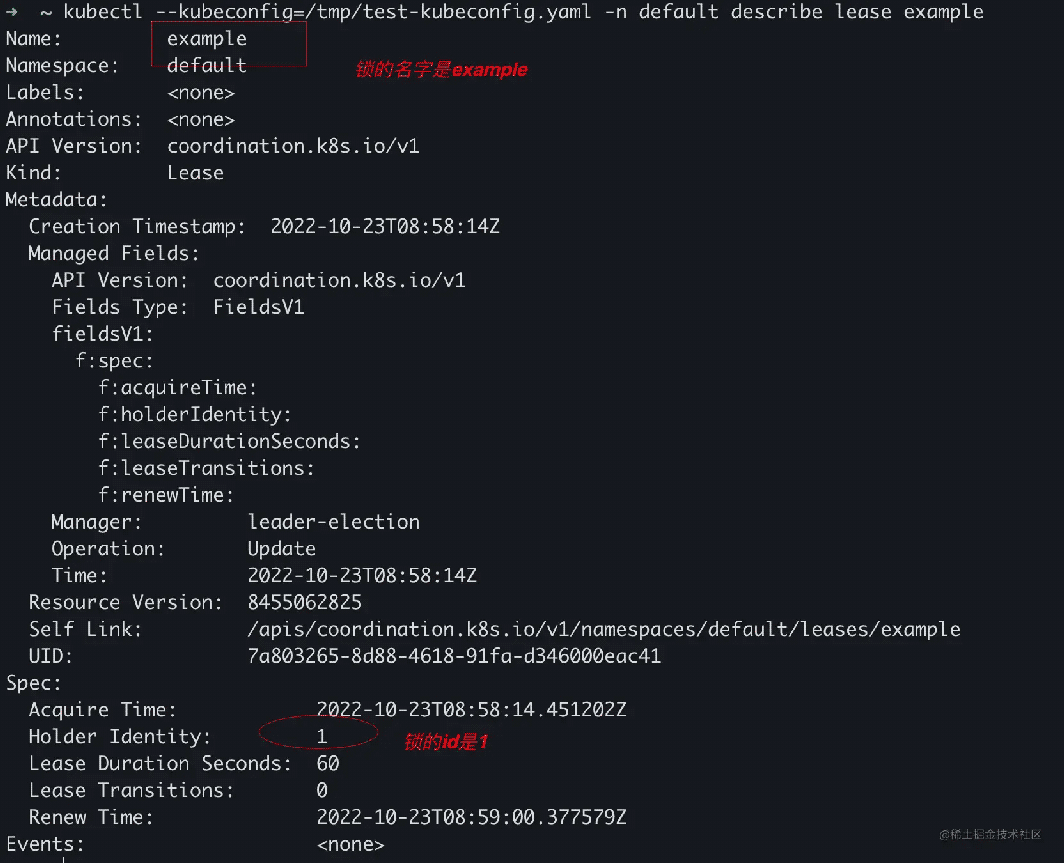
go run main.go --kubeconfig=/tmp/test-kubeconfig.yaml -logtostderr=true -lease-lock-name=example -lease-lock-namespace=default -id=1
可以看到,日志有输出,id=1的实例获取到资源了。
go run main.go --kubeconfig=/tmp/test-kubeconfig.yaml -logtostderr=true -lease-lock-name=example -lease-lock-namespace=default -id=1 I1023 17:00:21.670298 94227 leaderelection.go:248] attempting to acquire leader lease default/example... I1023 17:00:21.784234 94227 leaderelection.go:258] successfully acquired lease default/example I1023 17:00:21.784316 94227 main.go:78] Controller loop...
在kubernetes的集群上,看到
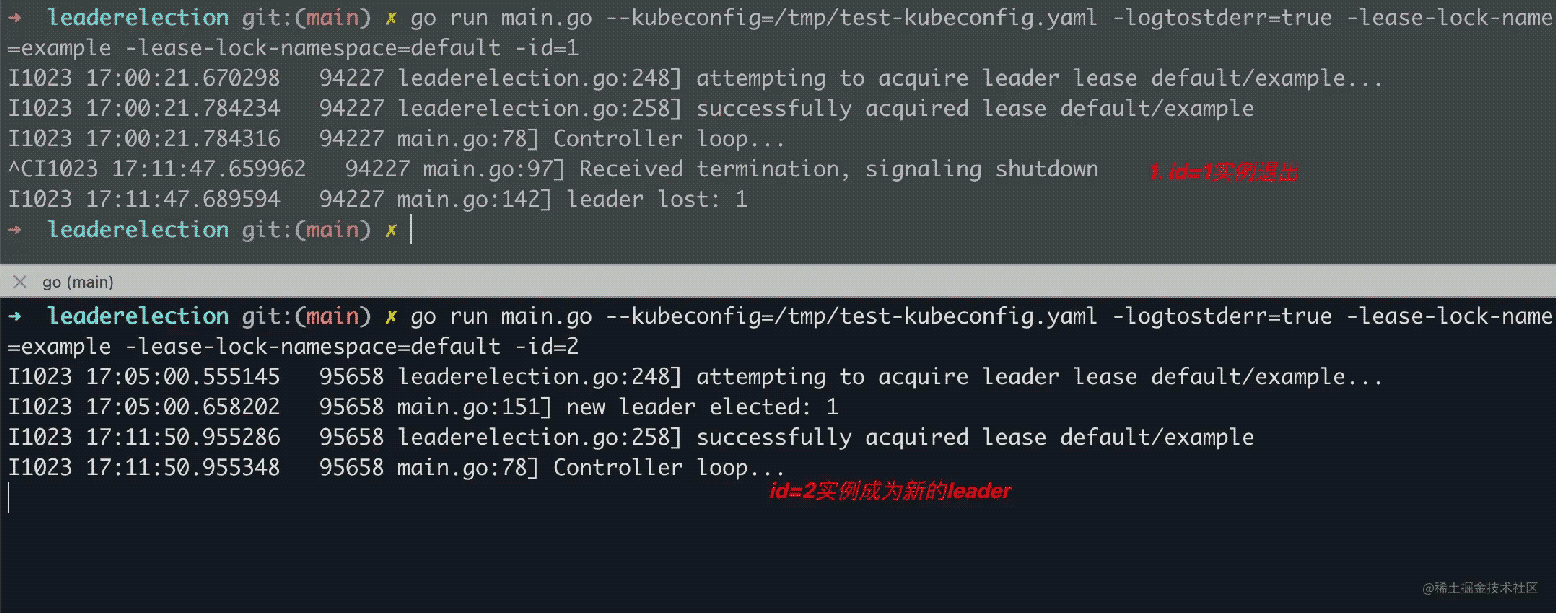
我们接着启动一个实例,id=2,日志中输出
go run main.go --kubeconfig=/tmp/test-kubeconfig.yaml -logtostderr=true -lease-lock-name=example -lease-lock-namespace=default -id=2 I1023 17:05:00.555145 95658 leaderelection.go:248] attempting to acquire leader lease default/example... I1023 17:05:00.658202 95658 main.go:151] new leader elected: 1
可以看出,id=2的实例,没有获取到锁,并且观察到id=1的锁获取到了实例。接着我们尝试退出id=1的实例,观察id=2的实例是否会成为新的leader
三、锁的实现
kubernets的资源都可以实现Get/Create/Update的操作,因此,理论上所有的资源都可以作为锁的底层。kubernetes 提供了Lease/Configmap/Endpoint作为锁的底层。
锁的状态转移如下:

锁需要实现以下的接口
type Interface interface {
// Get returns the LeaderElectionRecord
Get(ctx context.Context) (*LeaderElectionRecord, []byte, error)
// Create attempts to create a LeaderElectionRecord
Create(ctx context.Context, ler LeaderElectionRecord) error
// Update will update and existing LeaderElectionRecord
Update(ctx context.Context, ler LeaderElectionRecord) error
// RecordEvent is used to record events
RecordEvent(string)
// Identity will return the locks Identity
Identity() string
// Describe is used to convert details on current resource lock
// into a string
Describe() string
}
理论上,有Get/Create/Update三个方法,就可以实现锁的机制了。但是,需要保证update和create操作的原子性,这个就是kuberenetes的机制保证了。第二章的官网代码例子中,leaderelection.RunOrDie使用的RunOrDie接口,其实就是调用Run接口,而Run接口实现非常简单:
func (le *LeaderElector) Run(ctx context.Context) {
defer runtime.HandleCrash()
defer func() {
le.config.Callbacks.OnStoppedLeading()
}()
// 获取锁,如果没有获取到,就一直等待
if !le.acquire(ctx) {
return // ctx signalled done
}
ctx, cancel := context.WithCancel(ctx)
defer cancel()
// 获取到锁后,需要调用回调函数中的OnStartedLeading,运行controller的代码
go le.config.Callbacks.OnStartedLeading(ctx)
// 获取到锁后,需要不断地进行renew操作
le.renew(ctx)
}
LeaderElector关键是需要acquire和renew的操作,acquire和renew操作代码如下:
func (le *LeaderElector) acquire(ctx context.Context) bool {
ctx, cancel := context.WithCancel(ctx)
defer cancel()
succeeded := false
desc := le.config.Lock.Describe()
klog.Infof("attempting to acquire leader lease %v...", desc)
// 此接口会阻塞,利用定时的机制,获取锁,如果获取不到一直循环,除非ctx被取消。
wait.JitterUntil(func() {
// 获取锁
succeeded = le.tryAcquireOrRenew(ctx)
le.maybeReportTransition()
if !succeeded {
klog.V(4).Infof("failed to acquire lease %v", desc)
return
}
le.config.Lock.RecordEvent("became leader")
le.metrics.leaderOn(le.config.Name)
klog.Infof("successfully acquired lease %v", desc)
cancel()
}, le.config.RetryPeriod, JitterFactor, true, ctx.Done())
return succeeded
}
// renew loops calling tryAcquireOrRenew and returns immediately when tryAcquireOrRenew fails or ctx signals done.
func (le *LeaderElector) renew(ctx context.Context) {
ctx, cancel := context.WithCancel(ctx)
defer cancel()
// 循环renew机制,renew成功,不会返回true,导致Until会不断循环
wait.Until(func() {
//RenewDeadline的实现在这里,如果renew超过了RenewDeadline,会导致renew失败,主退出
timeoutCtx, timeoutCancel := context.WithTimeout(ctx, le.config.RenewDeadline)
defer timeoutCancel()
err := wait.PollImmediateUntil(le.config.RetryPeriod, func() (bool, error) {
// renew锁
return le.tryAcquireOrRenew(timeoutCtx), nil
}, timeoutCtx.Done())
le.maybeReportTransition()
desc := le.config.Lock.Describe()
if err == nil {
klog.V(5).Infof("successfully renewed lease %v", desc)
// renew成功
return
}
le.config.Lock.RecordEvent("stopped leading")
le.metrics.leaderOff(le.config.Name)
klog.Infof("failed to renew lease %v: %v", desc, err)
cancel()
}, le.config.RetryPeriod, ctx.Done())
// if we hold the lease, give it up
if le.config.ReleaseOnCancel {
le.release()
}
}
关键的实现在于tryAcquireOrRenew,而tryAcquireOrRenew就是依赖锁的状态转移机制完成核心逻辑。
func (le *LeaderElector) tryAcquireOrRenew(ctx context.Context) bool {
now := metav1.Now()
leaderElectionRecord := rl.LeaderElectionRecord{
HolderIdentity: le.config.Lock.Identity(),
LeaseDurationSeconds: int(le.config.LeaseDuration / time.Second),
RenewTime: now,
AcquireTime: now,
}
// 1. obtain or create the ElectionRecord
// 检查锁有没有
oldLeaderElectionRecord, oldLeaderElectionRawRecord, err := le.config.Lock.Get(ctx)
if err != nil {
// 没有锁的资源,就创建一个
if !errors.IsNotFound(err) {
klog.Errorf("error retrieving resource lock %v: %v", le.config.Lock.Describe(), err)
return false
}
if err = le.config.Lock.Create(ctx, leaderElectionRecord); err != nil {
klog.Errorf("error initially creating leader election record: %v", err)
return false
}
//对外宣称自己成为了leader
le.setObservedRecord(&leaderElectionRecord)
return true
}
// 2. Record obtained, check the Identity & Time
if !bytes.Equal(le.observedRawRecord, oldLeaderElectionRawRecord) {
// 这个机制很重要,会如果leader会不断正常renew这个锁,oldLeaderElectionRawRecord会一直发生变化,发生变化会更新le.observedTime
le.setObservedRecord(oldLeaderElectionRecord)
le.observedRawRecord = oldLeaderElectionRawRecord
}
// 如果还没超时并且此实例不是leader(leader是其他实例),那么就直接退出
if len(oldLeaderElectionRecord.HolderIdentity) > 0 &&
le.observedTime.Add(le.config.LeaseDuration).After(now.Time) &&
!le.IsLeader() {
klog.V(4).Infof("lock is held by %v and has not yet expired", oldLeaderElectionRecord.HolderIdentity)
return false
}
// 3. We're going to try to update. The leaderElectionRecord is set to it's default
// here. Let's correct it before updating.
// 如果是leader,就更新时间RenewTime,保证其他实例(非主)可以观察到:主还活着
if le.IsLeader() {
leaderElectionRecord.AcquireTime = oldLeaderElectionRecord.AcquireTime
leaderElectionRecord.LeaderTransitions = oldLeaderElectionRecord.LeaderTransitions
} else {
// 不是leader,那么锁就发生了转移
leaderElectionRecord.LeaderTransitions = oldLeaderElectionRecord.LeaderTransitions + 1
}
// 更新锁
// update the lock itself
if err = le.config.Lock.Update(ctx, leaderElectionRecord); err != nil {
klog.Errorf("Failed to update lock: %v", err)
return false
}
le.setObservedRecord(&leaderElectionRecord)
return true
}
以上就是Go语言 k8s kubernetes 使用leader election的详细内容,更多关于Go k8s leader election选举的资料请关注我们其它相关文章!
相关推荐
-
Golang 依赖注入经典解决方案uber/fx理论解析
目录 开篇 uber/fx provider 声明依赖关系 invoker 应用的启动器 fx.In 封装多个入参 fx.Out 封装多个出参 基于同类型提供多种实现 Annotate 注解器 小结 开篇 今天继续我们的[依赖注入开源解决方案系列], Dependency Injection 业界的开源库非常多,大家可以凭借自己的喜好也业务的复杂度来选型.基于 github star 数量以及方案的全面性,易用性上.推荐这两个: 1.[代码生成]派系推荐大家用 wire, 做的事情非常轻量级,省
-

使用client-go工具调用kubernetes API接口的教程详解(v1.17版本)
目录 说明 效果 实现 1.拉取工具源码 2.创建目录结构 查询代码实例 创建deployment资源 更新deployment类型服务 删除deployment类型服务 说明 可以调取k8s API 接口的工具有很多,这里我就介绍下client-go gitlab上client-go项目地址: https://github.com/kubernetes/client-go 这个工具是由kubernetes官方指定维护的,大家可以放心使用 效果 运行完成后,可以直接获取k8s集群信息等 实现 1
-
uber go zap 日志框架支持异步日志输出
目录 事件背景 心智负担 前置知识 解决思路 uber-go/zap 代码分析 上手开发 测试代码 同步输出日志 异步输出日志 不输出日志 总结 事件背景 过年在家正好闲得没有太多事情,想起年前一个研发项目负责人反馈的问题:“老李啊,我们组一直在使用你这边的 gin 封装的 webservice 框架开发,我们需要一套标准的异步日志输出模块.现在组内和其他使用 gin 的小伙伴实现的‘各有千秋’不统一,没有一个组或者部门对这部分的代码负责和长期维护.你能不能想想办法.” 这一看就是掉头发的事情,
-
Google Kubernetes Engine 集群实战详解
目录 GKE 集群介绍 K8s 带来的好处 使用 GKE 编排集群 GKE 集群介绍 Google Kubernetes Engine (GKE) 集群由 Kubernetes 开源集群管理系统提供支持.Kubernetes 为用户提供了与容器集群进行交互的机制.您可以使用 Kubernetes 命令和资源来部署和管理应用.执行管理任务.设置政策,以及监控您部署的工作负载的运行状况. K8s 带来的好处 自动管理 对应用容器进行监控和活跃性探测 自动扩缩 滚动更新 Google Cloud 上的
-
go语言K8S 的 informer机制浅析
目录 正文 使用方法 创建Informer工厂 创建对象Informer结构体 注册事件方法 启动Informer 机制解析 Reflector Controller Processer & Listener Indexer 总结 正文 Kubernetes的控制器模式是其非常重要的一个设计模式,整个Kubernetes定义的资源对象以及其状态都保存在etcd数据库中,通过apiserver对其进行增删查改,而各种各样的控制器需要从apiserver及时获取这些对象,然后将其应用到实际中,即将这
-
Kubernetes(K8S)容器集群管理环境完整部署详细教程-中篇
本文系列: Kubernetes(K8S)容器集群管理环境完整部署详细教程-上篇 Kubernetes(K8S)容器集群管理环境完整部署详细教程-中篇 Kubernetes(K8S)容器集群管理环境完整部署详细教程-下篇 接着Kubernetes(K8S)容器集群管理环境完整部署详细教程-上篇继续往下部署: 八.部署master节点 master节点的kube-apiserver.kube-scheduler 和 kube-controller-manager 均以多实例模式运行:kube-sc
-
Kubernetes集群环境初始化
概念 k8s/kubernetes容器化部署解决容器编排问题,kubernetes为容器编排软件的佼佼者kubernets为一组服务器集群 功能 自我修复 一个容器崩溃,另一个容器起来弹性伸缩 根据需要调整容器数量服务发现 自动发现的形式找到所需依赖负载均衡 一起分担流量版本回退 新版本有问题,立马回退到原来的版本存储编排 可以根据容器自身的需求自动创建存储卷.... k8s组件 k8s为控制节点 和 工作节点组成.master节点的组件负责集群的管理ApiServer:资源操作的唯一路口 接受
-
如何给k8s集群里的资源打标签
目录 如何给k8s集群里的资源打标签 补充:k8s kubernetes给node节点添加标签和删除node节点标签 如何给k8s集群里的资源打标签 给节点添加角色: k8s集群,节点如果有多个角色,需要标记出来,可以给对应的节点打上标签,方便后续了解节点的功能 命令:kubectl label nodes 节点名字 node-role.kubernetes.io/你想要的roles(=/-) 最后括号里的加减号,减号就是删除roles,等号就是增加roles 更新标签,在打标签命令后面添加参数
-
硬核 Redis 高频面试题解析
目录 1.Redis 是单线程还是多线程? 2.为什么 Redis 是单线程? 3.Redis 为什么使用单进程.单线程也很快 4.Redis 在项目中的使用场景 5.Redis 常见的数据结构 6.Redis 的字符串(SDS)和C语言的字符串区别 7.Sorted Set底层数据结构 8.Sorted Set 为什么同时使用字典和跳跃表? 9.Sorted Set 为什么使用跳跃表,而不是红黑树? 10.Hash 对象底层结构 11.Hash 对象的扩容流程 12.渐进式 rehash 的优
-
Linux环境下部署Consul集群
目录 1.Consul概念 1.1什么是Consul? 1.2Consul的特点 1.3Consul架构 1.4Consul的应用场景包括服务发现.服务隔离与服务配置 2.Consul在linux上的集群部署 2.1前期准备 2.2集群部署 1.Consul概念 1.1什么是Consul? Consul是一种服务网格解决方案,是HashiCorp公司推出的开源组件,由Go语言开发,部署起来很容易,只需要极少的可执行程序和配置.同时Consul也是一个分布式的,高度可用的系统,它附带了一个简单的内
-
深入解析NoSQL数据库的分布式算法(图文详解)
尽管NoSQL运动并没有给分布式数据处理带来根本性的技术变革,但是依然引发了铺天盖地的关于各种协议和算法的研究以及实践.在这篇文章里,我将针对NoSQL数据库的分布式特点进行一些系统化的描述. 系统的可扩展性是推动NoSQL运动发展的的主要理由,包含了分布式系统协调,故障转移,资源管理和许多其他特性.这么讲使得NoSQL听起来像是一个大筐,什么都能塞进去.尽管NoSQL运动并没有给分布式数据处理带来根本性的技术变革,但是依然引发了铺天盖地的关于各种协议和算法的研究以及实践.正是通过这些尝试逐渐总
-
NoSQL数据库的分布式算法详解
今天,我们将研究一些分布式策略,比如故障检测中的复制,这些策略用黑体字标出,被分为三段: 数据一致性.NoSQL需要在分布式系统的一致性,容错性和性能,低延迟及高可用之间作出权衡,一般来说,数据一致性是一个必选项,所以这一节主要是关于 数据复制 和 数据恢复 . 数据放置.一个数据库产品应该能够应对不同的数据分布,集群拓扑和硬件配置.在这一节我们将讨论如何 分布 以及 调整数据分布 才能够能够及时解决故障,提供持久化保证,高效查询和保证集训中的资源(如内存和硬盘空间)得到均衡使用. 对等系统.像
-
浅谈Zookeeper开源客户端框架Curator
zookeepercurator Curator是Netflix开源的一套ZooKeeper客户端框架. Netflix在使用ZooKeeper的过程中发现ZooKeeper自带的客户端太底层, 应用方在使用的时候需要自己处理很多事情, 于是在它的基础上包装了一下, 提供了一套更好用的客户端框架. Netflix在用ZooKeeper的过程中遇到的问题, 我们也遇到了, 所以开始研究一下, 首先从他在github上的源码, wiki文档以及Netflix的技术blog入手. 看完官方的文档之后,
-
Kafka producer端开发代码实例
一.producer工作流程 producer使用用户启动producer的线程,将待发送的消息封装到一个ProducerRecord类实例,然后将其序列化之后发送给partitioner,再由后者确定目标分区后一同发送到位于producer程序中的一块内存缓冲区中.而producer的另外一个线程(Sender线程)则负责实时从该缓冲区中提取出准备就绪的消息封装进一个批次(batch),统一发送给对应的broker,具体流程如下图: 二.producer示例程序开发 首先引入kafka相关依赖