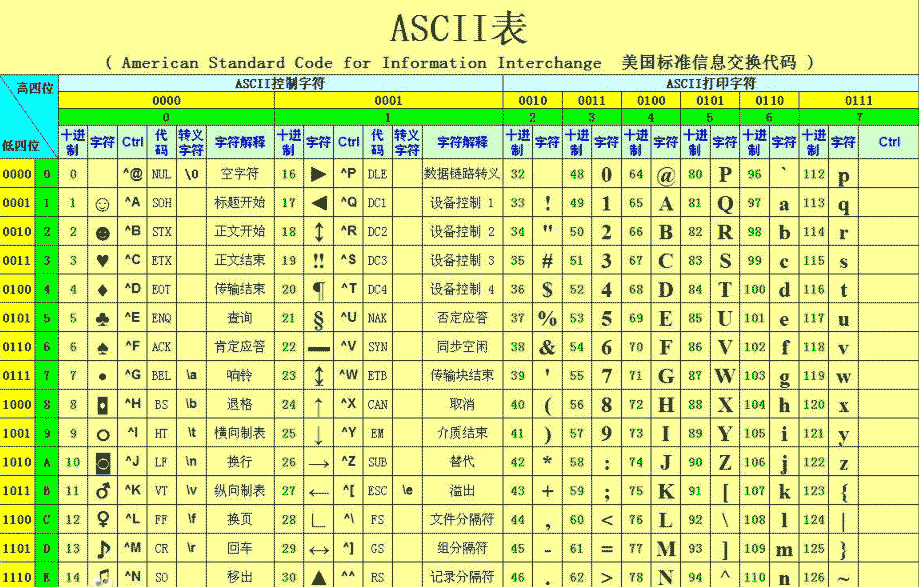
ASCII码表和说明
ASCII码表
信息在计算机上是用二进制表示的,这种表示法让人理解就很困难。因此计算机上都配有输入和输出设备,这些设备的主要目的就是,以一种人类可阅读的形式将信息 在这些设备上显示出来供人阅读理解。为保证人类和设备,设备和计算机之间能进行正确的信息交换,人们编制的统一的信息交换代码,这就是ASCII码表,它的全称是“美国信息交换标准代码”。
| 八进制 | 十六进制 | 十进制 | 字符 | 八进制 | 十六进制 | 十进制 | 字符 |
|---|---|---|---|---|---|---|---|
| 00 | 00 | 0 | nul | 100 | 40 | 64 | @ |
| 01 | 01 | 1 | soh | 101 | 41 | 65 | A |
| 02 | 02 | 2 | stx | 102 | 42 | 66 | B |
| 03 | 03 | 3 | etx | 103 | 43 | 67 | C |
| 04 | 04 | 4 | eot | 104 | 44 | 68 | D |
| 05 | 05 | 5 | enq | 105 | 45 | 69 | E |
| 06 | 06 | 6 | ack | 106 | 46 | 70 | F |
| 07 | 07 | 7 | bel | 107 | 47 | 71 | G |
| 10 | 08 | 8 | bs | 110 | 48 | 72 | H |
| 11 | 09 | 9 | ht | 111 | 49 | 73 | I |
| 12 | 0a | 10 | nl | 112 | 4a | 74 | J |
| 13 | 0b | 11 | vt | 113 | 4b | 75 | K |
| 14 | 0c | 12 | ff | 114 | 4c | 76 | L |
| 15 | 0d | 13 | er | 115 | 4d | 77 | M |
| 16 | 0e | 14 | so | 116 | 4e | 78 | N |
| 17 | 0f | 15 | si | 117 | 4f | 79 | O |
| 20 | 10 | 16 | dle | 120 | 50 | 80 | P |
| 21 | 11 | 17 | dc1 | 121 | 51 | 81 | Q |
| 22 | 12 | 18 | dc2 | 122 | 52 | 82 | R |
| 23 | 13 | 19 | dc3 | 123 | 53 | 83 | S |
| 24 | 14 | 20 | dc4 | 124 | 54 | 84 | T |
| 25 | 15 | 21 | nak | 125 | 55 | 85 | U |
| 26 | 16 | 22 | syn | 126 | 56 | 86 | V |
| 27 | 17 | 23 | etb | 127 | 57 | 87 | W |
| 30 | 18 | 24 | can | 130 | 58 | 88 | X |
| 31 | 19 | 25 | em | 131 | 59 | 89 | Y |
| 32 | 1a | 26 | sub | 132 | 5a | 90 | Z |
| 33 | 1b | 27 | esc | 133 | 5b | 91 | [ |
| 34 | 1c | 28 | fs | 134 | 5c | 92 | \ |
| 35 | 1d | 29 | gs | 135 | 5d | 93 | ] |
| 36 | 1e | 30 | re | 136 | 5e | 94 | ^ |
| 37 | 1f | 31 | us | 137 | 5f | 95 | _ |
| 40 | 20 | 32 | sp | 140 | 60 | 96 | ' |
| 41 | 21 | 33 | ! | 141 | 61 | 97 | a |
| 42 | 22 | 34 | " | 142 | 62 | 98 | b |
| 43 | 23 | 35 | # | 143 | 63 | 99 | c |
| 44 | 24 | 36 | $ | 144 | 64 | 100 | d |
| 45 | 25 | 37 | % | 145 | 65 | 101 | e |
| 46 | 26 | 38 | & | 146 | 66 | 102 | f |
| 47 | 27 | 39 | ` | 147 | 67 | 103 | g |
| 50 | 28 | 40 | ( | 150 | 68 | 104 | h |
| 51 | 29 | 41 | ) | 151 | 69 | 105 | i |
| 52 | 2a | 42 | * | 152 | 6a | 106 | j |
| 53 | 2b | 43 | + | 153 | 6b | 107 | k |
| 54 | 2c | 44 | , | 154 | 6c | 108 | l |
| 55 | 2d | 45 | - | 155 | 6d | 109 | m |
| 56 | 2e | 46 | . | 156 | 6e | 110 | n |
| 57 | 2f | 47 | / | 157 | 6f | 111 | o |
| 60 | 30 | 48 | 0 | 160 | 70 | 112 | p |
| 61 | 31 | 49 | 1 | 161 | 71 | 113 | q |
| 62 | 32 | 50 | 2 | 162 | 72 | 114 | r |
| 63 | 33 | 51 | 3 | 163 | 73 | 115 | s |
| 64 | 34 | 52 | 4 | 164 | 74 | 116 | t |
| 65 | 35 | 53 | 5 | 165 | 75 | 117 | u |
| 66 | 36 | 54 | 6 | 166 | 76 | 118 | v |
| 67 | 37 | 55 | 7 | 167 | 77 | 119 | w |
| 70 | 38 | 56 | 8 | 170 | 78 | 120 | x |
| 71 | 39 | 57 | 9 | 171 | 79 | 121 | y |
| 72 | 3a | 58 | : | 172 | 7a | 122 | z |
| 73 | 3b | 59 | ; | 173 | 7b | 123 | { |
| 74 | 3c | 60 | < | 174 | 7c | 124 | | |
| 75 | 3d | 61 | = | 175 | 7d | 125 | } |
| 76 | 3e | 62 | > | 176 | 7e | 126 | ~ |
| 77 | 3f | 63 | ? | 177 | 7f | 127 | del |
回车、换行、空格的ASCII码值—(附ASCII码表)
回车,ASCII码13,"\r"
换行,ASCII码10,"\n"
空格,ASCII码32
Return = CR = 13 = '\x0d'
NewLine = LF = 10 = '\x0a'
回车符号和换行符号产生背景
关于“回车”(carriage return)和“换行”(line feed)这两个概念的来历和区别。
在计算机还没有出现之前,有一种叫做电传打字机(Teletype Model 33)的玩意,每秒钟可以打10个字符。但是它有一个问题,就是打完一行换行的时候,要用去0.2秒,正好可以打两个字符。要是在这0.2秒里面,又有新的字符传过来,那么这个字符将丢失。
于是,研制人员想了个办法解决这个问题,就是在每行后面加两个表示结束的字符。一个叫做“回车”,告诉打字机把打印头定位在左边界;另一个叫做“换行”,告诉打字机把纸向下移一行。
这就是“换行”和“回车”的来历,从它们的英语名字上也可以看出一二。
后来,计算机发明了,这两个概念也就被般到了计算机上。那时,存储器很贵,一些科学家认为在每行结尾加两个字符太浪费了,加一个就可以。于是,就出现了分歧。
Unix系统里,每行结尾只有“<换行>”,即“\n”;Windows系统里面,每行结尾是“ <回车><换行>”,即“\r\n”;Mac系统里,每行结尾是“<回车>”。一个直接后果是,Unix/Mac系统下的文件在Windows里打开的话,所有文字会变成一行;而Windows里的文件在Unix/Mac下打开的话,在每行的结尾可能会多出一个^M符号
windows创建的文件是 \n\r结束的, 而linux,mac这种unix类系统是\n结束的。
所以unix的文本到windows会出现换行丢失(ultraedit这种软件可以正确识别); 而反过来就会出现^M的符号了
Windows等操作系统用的文本换行符和UNIX/Linux操作系统用的不同,Windows系统下输入的换行符在UNIX/Linux下不会显示为“换行”,而是显示为 ^M 这个符号(这是Linux等系统下规定的特殊标记,占一个字符大小,不是 ^ 和 M 的组合,打印不出来的)。Linux下很多文本编辑器(命令行)会在显示这个标记之后,补上一个自己的换行符,以避免内容混乱(只是用于显示,补充的换行符不会写入文件,有专门的命令将Windows换行符替换为Linux换行符)。 UNIX/Linux系统下的换行符在Windows系统的文本编辑器中会被忽略,整个文本会乱成一团。
windows换行是\r\n,十六进制数值是:0D0A。
LINUX换行是\n,十六进制数值是:0A
所以在linux保存的文件在windows上用记事本看的话会出现黑点,我们可以在LINUX下用命令把linux的文件格式转换成win格式的。
unix2dos 是把linux文件格式转换成windows文件格式
dos2unix 是把windows格式转换成linux文件格式。
linux下删除windows换行符^M
OJ判题时发现一个问题:用%c读入的代码都会报wa。后来发现跟scanf有关。在linux下使用%c会读到\n和\r两个字符。所以需要将^M(也就是\r)字符删掉
删除方法不少。找了一个比较简单的。
要将a.txt里的^M去掉并写入b.txt,则使用如下指令cat a.txt | tr -d "^M" > b.txt
注意:语句中的^M是通过ctrl+V, ctrl+M输入的。特指/r字符
unix 下换行符只有: \r
Dos 下换行符有:\r\n
具体的, \r的ascii 码是:14
\n的ascii 码是:10
A的ASCII码是65,a的ASCII码是97。
ASCII码表中,小写字母排在大写字母的后面,一个字母的大小写数值相差32,一般知道大写字母的ASCII码数值,其对应的小写字母的ASCII码数值就算出来了,是大写字母的ASCII码数值+32。
扩展资料
在ASCII码中,0~31及127(共33个)是控制字符或通信专用字符,如控制符:LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BS(退格)、BEL(响铃)等。
通信专用字符:SOH(文头)、EOT(文尾)、ACK(确认)等。
ASCII值为8、9、10 和13 分别转换为退格、制表、换行和回车字符。它们并没有特定的图形显示,但会依不同的应用程序,而对文本显示有不同的影响。
32~126(共95个)是字符(32是空格),其中48~57为0到9十个阿拉伯数字。
65~90为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。
同时还要注意,在标准ASCII中,其最高位(b7)用作奇偶校验位。
所谓奇偶校验,是指在代码传送过程中用来检验是否出现错误的一种方法,一般分奇校验和偶校验两种。
相关推荐
-

PHP详解ASCII码对照表与字符转换
一,通用的ASCII码对照表 图解ASCII码对照表图,以字符A为例Dec表示十进制,如65Hx表示十六进制,如41Oct表示八进制,如101Char表示显示字符,如A ASCII码对照表图分为两个单元1,控制字符 0-31和1272,可显示字符 32-126(1)48-57为0到9十个阿拉伯数字:(2)65-90为26个大写英文字母:(3)97-122号为26个小写英文字母:(4)其它标点符号.运算符号等: 二,ASCII扩展码对照表 三,PHP字符转换函数说明 具体字符转换函数说明请参考[P
-
常用字符集编码详解(ASCII GB2312 GBK GB18030 unicode UTF-8)
ASCII ASCII码是7位编码,编码范围是0x00-0x7F.ASCII字符集包括英文字母.阿拉伯数字和标点符号等字符.其中0x00-0x20和0x7F共33个控制字符. 只支持ASCII码的系统会忽略每个字节的最高位,只认为低7位是有效位.HZ字符编码就是早期为了在只支持7位ASCII系统中传输中文而设计的编码.早期很多邮件系统也只支持ASCII编码,为了传输中文邮件必须使用BASE64或者其他编码方式. GB2312 GB2312是基于区位码设计的,区位码把编码表分为94个区,每个区对应
-
C#中使用强制类型实现字符串和ASCII码之间的转换
C#貌似没有专门用于ASCII码转字符或字符转ASCII码的系统函数,所以小编这里就借用一下强制类型转换来实现ASCII码与字符之间的互转. 所谓的ASCII码,即American Standard Code for Information Interchange,美国信息互换标准代码的简写,它是基于拉丁字母的编码系统,也是当前最为通用的单字节编码系统.本文讲述在C#中如何实现字母或 数字等字符如何转换为ASCII编码,同时也可以将ASCII编码转换为字符. 一.将字符转换为ASCII码(数字)
-
JS中把字符转成ASCII值的函数示例代码
字符转ascii码:用charCodeAt();ascii码转字符:用fromCharCode(); 看一个小例子 复制代码 代码如下: <script>str="A";code = str.charCodeAt(); str2 = String.fromCharCode(code);str3 = String.fromCharCode(0x60+26); document.write(code+'<br />');document.write(str2+'&l
-
ascii码表(二进制 十进制 十六进制)详细介绍
ascii码表 控制字符 二进制 十进制 十六进制 缩写 解释 0000 0000 0 00 NUL 空字符(Null) 0000 0001 1 01 SOH 标题开始 0000 0010 2 02 STX 正文开始 0000 0011 3 03 ETX 正文结束 0000 0100 4 04 EOT 传输结束 0000 0101 5 05 ENQ 请求 0000 0110 6 06 ACK 收到通知 0000 0111 7 07 BEL 响铃 0000 1000 8 08 BS 退格 0000
-
爱恋千雪-US-AscII加密解密工具(网页加密)下载
<html> <head> <meta http-equiv="Content-Type" content="text/html; charset=US-ASCII" /> <title>爱恋千雪</title> </head><body> 肌南迷傩艩仍吞犘章躺脿壮茂阅犎酝虪串氨盼㈣趑鸷鼢鳟鞒蜱爷梏盱疮篝蜷泗翡⒕娂仍吞炯扰聊炯陨蕴啪无法找到该页集陨蕴啪娂团粤犎栽协叛
-
JS中字符问题(二进制/十进制/十六进制及ASCII码之间的转换)
var a='11160'; alert(parseInt(a,2)); //将111做为2进制来转换,忽略60(不符合二进制),从左至右只将符合二进制数的进行转换 alert(parseInt(a,16)); //将所有的都进行转换 依照此方法,其实可以转换成任何进制 var a='1110'; alert(parseInt(a,10).toString(16)); //将A转换为10进制,然后再转换成16进制 同样也可以是其它进制 下面说下ASCII 码: function test(){
-
javascript实现unicode与ASCII相互转换的方法
本文实例讲述了javascript实现unicode与ASCII相互转换的方法.分享给大家供大家参考,具体如下: <head> <meta http-equiv="Content-Type" content="text/html; charset=gb2312"> <title>Unicode.ASCII相互转换</title> <script type="text/javascript"&g
-
JAVA实现打印ascii码表代码
我就废话不多说了,大家还是直接看代码吧~ package com.jalor; public class AAAA { public static void main(String[] args) { outputA(65); outputA(97); } // 打印ascii码表 public static void outputA(int count){ for (int i = 0; i < 26; i++) { System.out.print((char)(count+ i)); }
-
ASCII码表和说明
ASCII码表 信息在计算机上是用二进制表示的,这种表示法让人理解就很困难.因此计算机上都配有输入和输出设备,这些设备的主要目的就是,以一种人类可阅读的形式将信息 在这些设备上显示出来供人阅读理解.为保证人类和设备,设备和计算机之间能进行正确的信息交换,人们编制的统一的信息交换代码,这就是ASCII码表,它的全称是"美国信息交换标准代码". 八进制 十六进制 十进制 字符 八进制 十六进制 十进制 字符 00 00 0 nul 100 40 64 @ 01 01 1 soh 101 4
-
C语言如何利用ASCII码表统计字符串每个字符出现的次数
目录 利用ASCII码表统计字符串每个字符出现的次数 我的代码 运行正确 总结 利用ASCII码表统计字符串每个字符出现的次数 在C语言里面写个能够统计并打印字符串中字符出现次数心想这不是常规操作吗? 定义两个char数组,输入,赋值给另一个字符数组 通过一个for循环嵌套两个for循环,比较,相同的值数组赋值=‘*’. 然后判断当数组值不等于0的时候和原数组进行比较再打印输出” 我的代码 #include<stdio.h> #include<string.h> #define m
-
ASCII码表 和 说明
Decimal Octal Hex Binary Value 10 08 16 02 ------- ----- *--- ------ ----- 000 000 000 00000000 NUL (Null char.) 001 001 001 00000001 SOH (Sta
-
python中内置函数ord()返回字符串的ASCII数值实例详解
目录 常用 ASCII 码表对照表: ord()函数介绍: 应用实例: 常用 ASCII 码表对照表: 注意如下几点: 0-9:48-57A-Z:65-90a-z:97-122 ord()函数介绍: ord() 函数是 chr() 函数(对于 8 位的 ASCII 字符串)的配对函数,它以一个字符串(Unicode 字符)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值. >>> ord('0') 48 >>> ord('A') 65 >>
-
Perl基本数组排序方法介绍
本文我们学习如何用Perl对字符串或者数字数组进行排序. Perl有个内置函数叫做sort毫无疑问的可以排序一个数组. 其最简单的形式是传递一个数组,它会返回排序后的元素组成的数组.@sorted = sort @original. 基于ASCII码排序 复制代码 代码如下: #!/usr/bin/perl use strict; use warnings; use 5.010; use Data::Dumper qw(Dumper); my @words = qw(foo bar zo
-
Perl数组排序学习笔记
本文我们学习如何用Perl对字符串或者数字数组进行排序. Perl有个内置函数叫做sort毫无疑问的可以排序一个数组. 其最简单的形式是传递一个数组,它会返回排序后的元素组成的数组.@sorted = sort @original. 基于ASCII码排序 复制代码 代码如下: #!/usr/bin/perl use strict; use warnings; use 5.010; use Data::Dumper qw(Dumper); my @words = qw(foo bar zo
-
c语言字符数组与字符串的使用详解
1.字符数组的定义与初始化字符数组的初始化,最容易理解的方式就是逐个字符赋给数组中各元素.char str[10]={ 'I',' ','a','m',' ','h','a','p','p','y'};即把10个字符分别赋给str[0]到str[9]10个元素如果花括号中提供的字符个数大于数组长度,则按语法错误处理:若小于数组长度,则只将这些字符数组中前面那些元素,其余的元素自动定为空字符(即 '\0' ). 2.字符数组与字符串在c语言中,将字符串作为字符数组来处理.(c++中不是)在实际应用
-
GBK字符编码(字符集)缺陷导致web安全漏洞
多字节编码由来 我们先来看看最常用的,最小字符集是ascii,对应的二级制可以表示为:00-7F 编码 .它也是我们计算机使用最早通用的字符集.前期几乎可以表示所有英文字符.后来,更多使用计算机国家加入后,我们就想在计算机中表示中文字符.我们知道常见中文就有7000多个字符.ascii码就只有128字符,只有0-127编码位置,远远不够用了.因此,我们就开始制作更大字符集,并且保证兼容ascii编码.要支持更多字符,选择更大字符集.我们只能用多个字节来描述一个字符了.为了很好的与ascii码,区