使用 Python 清理收藏夹里已失效的网站
失效的书签们
我们日常浏览网站的时候,时不时会遇到些新奇的东西( 你懂的.jpg ),于是我们就默默的点了个收藏或者加书签。然而当我们面对成百上千的书签和收藏夹的时候,总会头疼不已……
尤其是昨天还在更新的程序设计博客,今天就挂了永不更新。或者是昨天看的起劲的电影网站,今天直接404。失效页面这么多,每次我打开才知道失效了,并且需要手动删除,这能是一个程序员干的事情吗?
可是无论是Google浏览器还是国内浏览器,最多也就提供一个对于收藏夹的备份服务,那只能Python走起了。
Python支持的收藏夹文件格式
对于收藏夹提供的支持很少,主要还是因为收藏夹藏在浏览器里面,我们只能手动导出htm文件进行管理

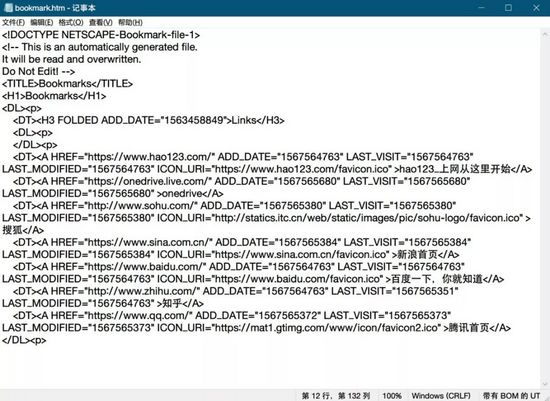
内容比较简单,对前端没什么了解的我,也可以很明显看出其中的树形结构和内在逻辑。
固定格式 网址 固定格式 页面名 固定格式
很简单的想到了正则匹配,其中有两个子串。 提取出来再挨个访问,看看哪个失效了,就删除,就能获得清理后的收藏夹了。
读取收藏夹文件
path = "C:\\Users\\XU\\Desktop" fname = "bookmarks.html" os.chdir(path) bookmarks_f = open(fname, "r+" ,encoding='UTF-8') booklists = bookmarks_f.readlines() bookmarks_f.close()
因为对于前端的不熟悉,这个导出的收藏夹可以抽象的分成
- 结构代码
- 保存网页书签的关键代码
其中结构代码我们不能动,要原封不动的保留,而保存网页书签的关键代码,我们要提取内容并且进行判断保留和删除。
所以这里采用readlines函数,每行读取,单独判断。
正则匹配
pattern = r'href="(.*?)" rel="external nofollow" .*?>(.*?)</A>' while len(booklists)> 0 : bookmark = booklists.pop( 0 ) detail = re.search(pattern, bookmark)
如果是关键代码:提取出的子串在 detail.group(1) 和 detail.group(2) 里面
而如果是结构代码:detail == None
访问页面
import requests r = requests. get (detail. group ( 1 ),timeout= 500 )
编代码尝试之后发现会有这四种情况
r.status_code == requests.codes.ok r.status_code==404 r.status_code!=404 && 无法访问 (可能是屏蔽爬虫,建议保留) requests.exceptions.ConnectionError
类似知乎、简书基本都反爬了,所以简单的get还不能有效访问,细节不值得大费周章,直接保留就好。 而error,直接用try抛出异常就好,不然程序会停止运行。
添加逻辑后: (代码可左右拖动)
while len ( booklists )>0: = booklists.pop( 0 ) detail = re.search(pattern, bookmark) if detail: #print(detail.group(1) +"----"+ detail.group(2)) try : #访问 r = requests. get (detail. group ( 1 ),timeout= 500 ) #如果可则添加 if r.status_code == requests.codes.ok: new_lists.append(bookmark) print( "ok------ 保留:" + detail. group ( 1 )+ " " + detail. group ( 2 )) else : if (r.status_code== 404 ): print( "不可访问 删除:" + detail. group ( 1 )+ " " + detail. group ( 2 ) + '错误码 ' +str(r.status_code)) else : print( "其他原因 保留:" + detail. group ( 1 )+ " " + detail. group ( 2 ) + '错误码 ' +str(r.status_code)) new_lists.append(bookmark) except: print( "不可访问 删除:" + detail. group ( 1 )+ " " + detail. group ( 2 )) #new_lists.append(bookmark) else : #没匹配到是结构语句 new_lists.append(bookmark)
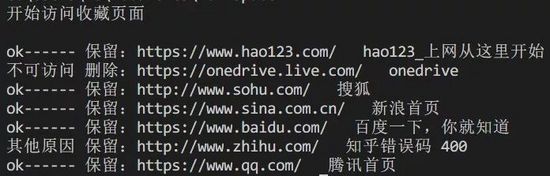
程序执行情况
导出htm
bookmarks_f = open ( 'new_' +fname, "w+" ,encoding= 'UTF-8' ) bookmarks_f.writelines(new_lists) bookmarks_f. close ()
导入浏览器
实际应用于我的浏览器
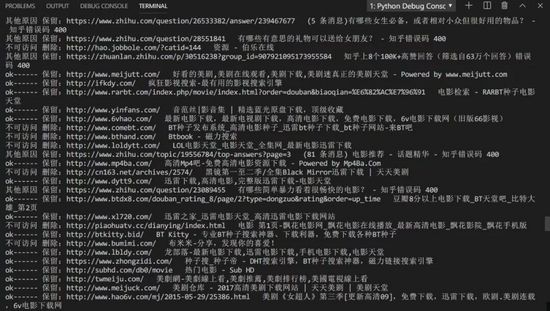
确实有很多电影网都失效了,通过Python能够一键清理其中无法访问的书签。人生苦短,P ython 的确可以让生活更高效~
总结
以上所述是小编给大家介绍的使用 Python 清理收藏夹里已失效的网站,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
使用 Python 清理收藏夹里已失效的网站
失效的书签们 我们日常浏览网站的时候,时不时会遇到些新奇的东西( 你懂的.jpg ),于是我们就默默的点了个收藏或者加书签.然而当我们面对成百上千的书签和收藏夹的时候,总会头疼不已-- 尤其是昨天还在更新的程序设计博客,今天就挂了永不更新.或者是昨天看的起劲的电影网站,今天直接404.失效页面这么多,每次我打开才知道失效了,并且需要手动删除,这能是一个程序员干的事情吗? 可是无论是Google浏览器还是国内浏览器,最多也就提供一个对于收藏夹的备份服务,那只能Python走起了. Python支持
-
Python挑选文件夹里宽大于300图片的方法
本文实例讲述了Python挑选文件夹里宽大于300图片的方法.分享给大家供大家参考.具体分析如下: 这段代码需要用到PIL库.代码如下所示: import sys import os sys.path.append('PIL') from PIL import Image as im path = '/home/hualun/桌面/img/' new_path = '/home/hualun/桌面/img2/' for x in os.listdir(path): if x.endswith('
-
python删除本地夹里重复文件的方法
上次的博文主要说了从网上下载图片,于是我把整个笑话网站的图片都拔下来了,但是在拔取的图片中有很多重复的,比如说页面的其他图片.重复发布的图片等等.所以我又找了python的一些方法,写了一个脚本可以删除指定文件夹里重复的图片. 一.方法和思路 1.比对文件是否相同的方法:hashlib库里提供了获取文件md5值的方法,所以我们可以通过md5值来判定是否图片相同 2.对文件的操作:os库里有对文件的操作方法,比如:os.remove()可以删除指定的文件, os.listdir()可以通过指定文件
-
用vbs 取得收藏夹里的所有链接名称和URL的脚本
另外,可以考虑在输出的时候将链接输出成超链接形式,输出文件改为html文件.GetFavorites.vbs: 复制代码 代码如下: '=================================================================== Const FAVORITES = &H6& Const ForWriting = 2 Set objShell = CreateObject("shell.application") Set objF
-
C#实现创建桌面快捷方式与添加网页到收藏夹的示例
今天来介绍一个小功能,就是把正在浏览的某网页添加到收藏夹中.完成这个功能主要是两步,首先要取得系统用户的收藏夹目录,第二是要根据获得页面地址在收藏夹目录创建一个快捷方式.具体我们就一起来了解一下吧. 一.C#创建快捷方式 要创建快捷方式须引用IWshRuntimeLibrary.dll,引用方式为:对项目添加引用-->选择COM组件-->选择"Windows Script Host Object Model"确定,则添加成功!接下来就是编码: /// <summary
-
Python编程实现两个文件夹里文件的对比功能示例【包含内容的对比】
本文实例讲述了Python编程实现两个文件夹里文件的对比功能.分享给大家供大家参考,具体如下: #-*-coding:utf-8-*- #=============================================================================== # 目录对比工具(包含子目录 ),并列出 # 1.A比B多了哪些文件 # 2.B比A多了哪些文件 # 3.二者相同的文件:文件大小相同 VS 文件大小不同 (Size相同文件不打印:与Size不同文件显
-
python根据list重命名文件夹里的所有文件实例
如下所示: # coding = utf-8 import os path = "D:\\chunyu"#想要重命名所有文件存放的文件夹 filelist = os.listdir(path) #该文件夹下所有的文件(包括文件夹) list = [] fileopen = open('D:\chunyu.txt','r')#之后想要重命名成的所有名字的集合,这个名字为除去文件扩展名的文件名 i =0 for file in filelist: print(file) for line
-

python使用openCV遍历文件夹里所有视频文件并保存成图片
如果你在文件夹里有很多视频,并且文件夹里还有文件夹,文件夹里的文件夹也有视频,怎么能逐个读取并且保存..所以我写了个代码用了os,walk,这个可以遍历所有文件夹里的文件和文件夹 import os import cv2 cut_frame = 250 # 多少帧截一次,自己设置就行 save_path = "C:\文献与资料\手持红外\图片" for root, dirs, files in os.walk(r"C:\文献与资料\手持红外"): # 这里就填文件夹
-
基于python对B站收藏夹按照视频发布时间进行排序的问题
前言 在最一开始,我的B站收藏一直是存放在默认收藏夹中,但是随着视频收藏的越来越多,没有分类的视频放在一起,想在众多视频中找到想要的视频非常困难,因此就对收藏夹里面的视频进行了分类.但是分类之后紧接着又出现了一个新的问题:原来存放在默认收藏夹里面视频的相对顺序被打乱了--明明前几天刚收藏的视频却要翻很多很多页才能找到,因此有了这个程序. 程序的作用 因为我们看到的视频大部分都是通过推荐得到的,而推荐的视频大部分都是刚发布不久,因此大部分收藏的视频的顺序也基本是按照视频发布的顺序来的.那么通过程序
-
python解析Chrome浏览器历史浏览记录和收藏夹数据
目录 前言 (一)查询chrome数据缓存地址 (二)提取收藏夹数据 1.文件路径 2.解析代码 (三)查看浏览历史数据 1.文件路径 2.解析代码 (四)完整代码&测试代码 总结 前言 常使用chrome浏览器作为自己的默认浏览器,也喜欢使用浏览器来收藏自己的喜欢的有用的链接,自己也做了一个记录笔记的小脚本,想扩展收录chrome浏览器收藏夹的内容,,下面,,使用python提取chrome浏览器的历史记录,以及收藏夹. (一)查询chrome数据缓存地址 1.打开 chrome浏览器,输入