pytorch中Tensor.to(device)和model.to(device)的区别及说明
目录
- Tensor.to(device)和model.to(device)的区别
- 区别所在
- 举例
- pytorch学习笔记--to(device)用法
- 这段代码到底有什么用呢?
- 为什么要在GPU上做运算呢?
- .cuda()和.to(device)的效果一样吗?为什么后者更好?
- 如果你有多个GPU
Tensor.to(device)和model.to(device)的区别
区别所在
使用GPU训练的时候,需要将Module对象和Tensor类型的数据送入到device。通常会使用 to.(device)。但是需要注意的是:
- 对于Tensor类型的数据,使用to.(device) 之后,需要接收返回值,返回值才是正确设置了device的Tensor。
- 对于Module对象,只用调用to.(device) 就可以将模型设置为指定的device。不必接收返回值。
来自pytorch官方文档的说明:
Tensor.to(device)

Module.to(device)
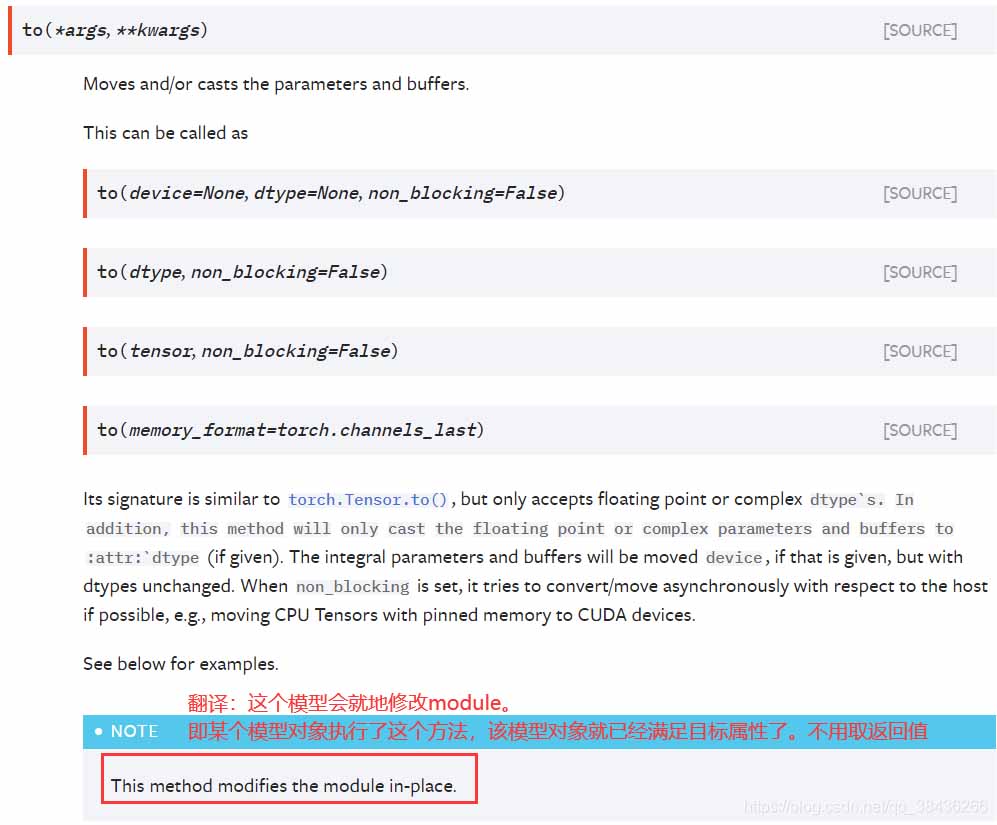
举例
# Module对象设置device的写法 model.to(device) # Tensor类型的数据设置 device 的写法。 samples = samples.to(device)
pytorch学习笔记--to(device)用法
在学习深度学习的时候,我们写代码经常会见到类似的代码:
img = img.to(device=torch.device("cuda" if torch.cuda.is_available() else "cpu"))
model = models.vgg16_bn(pretrained=True).to(device=torch.device("cuda" if torch.cuda.is_available() else "cpu"))
也可以先定义device:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)
img = img.to(device)
这段代码到底有什么用呢?
这段代码的意思就是将所有最开始读取数据时的tensor变量copy一份到device所指定的GPU上去,之后的运算都在GPU上进行。
为什么要在GPU上做运算呢?
首先,在做高维特征运算的时候,采用GPU无疑是比用CPU效率更高,如果两个数据中一个加了.cuda()或者.to(device),而另外一个没有加,就会造成类型不匹配而报错。
tensor和numpy都是矩阵,前者能在GPU上运行,后者只能在CPU运行,所以要注意数据类型的转换。
.cuda()和.to(device)的效果一样吗?为什么后者更好?
两个方法都可以达到同样的效果,在pytorch中,即使是有GPU的机器,它也不会自动使用GPU,而是需要在程序中显示指定。调用model.cuda(),可以将模型加载到GPU上去。这种方法不被提倡,而建议使用model.to(device)的方式,这样可以显示指定需要使用的计算资源,特别是有多个GPU的情况下。
如果你有多个GPU
那么可以参考以下代码:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = Model()
if torch.cuda.device_count() > 1:
model = nn.DataParallel(model,device_ids=[0,1,2])
model.to(device)
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
pytorch中.to(device) 和.cuda()的区别说明
原理 .to(device) 可以指定CPU 或者GPU device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 单GPU或者CPU model.to(device) #如果是多GPU if torch.cuda.device_count() > 1: model = nn.DataParallel(model,device_ids=[0,1,2]) model.to(
-
Pytorch to(device)用法
如下所示: device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") model.to(device) 这两行代码放在读取数据之前. mytensor = my_tensor.to(device) 这行代码的意思是将所有最开始读取数据时的tensor变量copy一份到device所指定的GPU上去,之后的运算都在GPU上进行. 这句话需要写的次数等于需要保存GPU上的tensor变
-
pytorch中的model=model.to(device)使用说明
这代表将模型加载到指定设备上. 其中,device=torch.device("cpu")代表的使用cpu,而device=torch.device("cuda")则代表的使用GPU. 当我们指定了设备之后,就需要将模型加载到相应设备中,此时需要使用model=model.to(device),将模型加载到相应的设备中. 将由GPU保存的模型加载到CPU上. 将torch.load()函数中的map_location参数设置为torch.device('cpu')
-
Pytorch中Tensor与各种图像格式的相互转化详解
前言 在pytorch中经常会遇到图像格式的转化,例如将PIL库读取出来的图片转化为Tensor,亦或者将Tensor转化为numpy格式的图片.而且使用不同图像处理库读取出来的图片格式也不相同,因此,如何在pytorch中正确转化各种图片格式(PIL.numpy.Tensor)是一个在调试中比较重要的问题. 本文主要说明在pytorch中如何正确将图片格式在各种图像库读取格式以及tensor向量之间转化的问题.以下代码经过测试都可以在Pytorch-0.4.0或0.3.0版本直接使用. 对py
-

pytorch中Tensor.to(device)和model.to(device)的区别及说明
目录 Tensor.to(device)和model.to(device)的区别 区别所在 举例 pytorch学习笔记--to(device)用法 这段代码到底有什么用呢? 为什么要在GPU上做运算呢? .cuda()和.to(device)的效果一样吗?为什么后者更好? 如果你有多个GPU Tensor.to(device)和model.to(device)的区别 区别所在 使用GPU训练的时候,需要将Module对象和Tensor类型的数据送入到device.通常会使用 to.(devic
-
在PyTorch中Tensor的查找和筛选例子
本文源码基于版本1.0,交互界面基于0.4.1 import torch 按照指定轴上的坐标进行过滤 index_select() 沿着某tensor的一个轴dim筛选若干个坐标 >>> x = torch.randn(3, 4) # 目标矩阵 >>> x tensor([[ 0.1427, 0.0231, -0.5414, -1.0009], [-0.4664, 0.2647, -0.1228, -1.1068], [-1.1734, -0.6571, 0.7230,
-
pytorch中tensor的合并与截取方法
合并: torch.cat(inputs=(a, b), dimension=1) e.g. x = torch.cat((x,y), 0) 沿x轴合并 截取: x[:, 2:4] 以上这篇pytorch中tensor的合并与截取方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
pytorch中tensor.expand()和tensor.expand_as()函数详解
tensor.expend()函数 >>> import torch >>> a=torch.tensor([[2],[3],[4]]) >>> print(a.size()) torch.Size([3, 1]) >>> a.expand(3,2) tensor([[2, 2], [3, 3], [4, 4]]) >>> a tensor([[2], [3], [4]]) 可以看出expand()函数括号里面为变形
-
pytorch中tensor张量数据类型的转化方式
1.tensor张量与numpy相互转换 tensor ----->numpy import torch a=torch.ones([2,5]) tensor([[1., 1., 1., 1., 1.], [1., 1., 1., 1., 1.]]) # ********************************** b=a.numpy() array([[1., 1., 1., 1., 1.], [1., 1., 1., 1., 1.]], dtype=float32) numpy --
-
对Pytorch中Tensor的各种池化操作解析
AdaptiveAvgPool1d(N) 对一个C*H*W的三维输入Tensor, 池化输出为C*H*N, 即按照H轴逐行对W轴平均池化 >>> a = torch.ones(2,3,4) >>> a[0,1,2] = 0 >>>> a tensor([[[1., 1., 1., 1.], [1., 1., 0., 1.], [1., 1., 1., 1.]], [[1., 1., 1., 1.], [1., 1., 1., 1.], [1.,
-
PyTorch中 tensor.detach() 和 tensor.data 的区别详解
PyTorch0.4中,.data 仍保留,但建议使用 .detach(), 区别在于 .data 返回和 x 的相同数据 tensor, 但不会加入到x的计算历史里,且require s_grad = False, 这样有些时候是不安全的, 因为 x.data 不能被 autograd 追踪求微分 . .detach() 返回相同数据的 tensor ,且 requires_grad=False ,但能通过 in-place 操作报告给 autograd 在进行反向传播的时候. 举例: ten
-
PyTorch中Tensor的数据统计示例
张量范数:torch.norm(input, p=2) → float 返回输入张量 input 的 p 范数 举个例子: >>> import torch >>> a = torch.full([8], 1) >>> b = a.view(2, 4) >>> c = a.view(2, 2, 2) >>> a.norm(1), b.norm(1), c.norm(1) # 求 1- 范数 (tensor(8.),
-
PyTorch中Tensor的数据类型和运算的使用
在使用Tensor时,我们首先要掌握如何使用Tensor来定义不同数据类型的变量.Tensor时张量的英文,表示多维矩阵,和numpy对应,PyTorch中的Tensor可以和numpy的ndarray相互转换,唯一不同的是PyTorch可以在GPU上运行,而numpy的ndarray只能在cpu上运行. 常用的不同数据类型的Tensor,有32位的浮点型torch.FloatTensor, 64位浮点型 torch.DoubleTensor, 16位整形torch.ShortTenso