Mysql InnoDB中B+树索引使用注意事项
目录
- 一、根页面万年不动
- 二、内节点中目录项记录的唯一性
- 三、一个页面至少容纳 2 条记录
一、根页面万年不动
在之前的文章里,为了方便理解,都是先画存储用户记录的叶子节点,然后再画出存储目录项记录的内节点。
但实际上 B+ 树的行成过程是这样的:
- 每当为某个表创建一个 B+ 树索引,都会为这个索引创建一个根节点页面。最开始表里没数据,所以根节点中既没有用户记录,也没有目录项记录。
- 当往表里插入用户记录时,先把用户记录存储到这个根节点上。
- 当根节点页空间用完,继续插入记录,此时会将根节点中所有记录复制到一个新页(比如页 a),然后对这个新页进行页分裂,得到另一个新页(页 b)。这时候新插入的记录就根据键值大小分配到页 a 和 页 b 中。于是,根节点页就升级成了存储目录项记录的页,就需要把页a 和 页b 对应的目录项记录插入到根节点中。
另外,当一个B+树索引的根节点创建后,它的页号就不会再变。
所以只要我们对某个表建立一个索引,那么它的根节点的页号就会被记录到某个地方,后续只要 innodb引擎需要用这个索引,就会从那个固定的地方取出根节点的页号,从而访问这个索引。
二、内节点中目录项记录的唯一性
在B+树索引的内节点中,目录项记录的内容是索引列+页号。但是对于二级索引来说,不太严谨。
因为二级索引的索引列可能存在相同的值,比如某张表里有这4条记录,其中c1列是主键 :

现在为c2列建立索引:

如果这时候继续插入一条记录,3个列分别为9、1、'c',就会遇到问题:
新记录中 c2的值也是1,那么这个新记录到底应该放在页 4,还是放到页 5?
所以,为了能让新插入的记录可以找到自己应该到哪个页中,就需要保证B+树同一层内节点的目录项记录是唯一的。
那么,实际上二级索引的内节点的目录项记录应该由 3 个部分组成:
- 索引列的值
- 主键值
- 页号
所以实际上给c2建立的索引应该是这样:
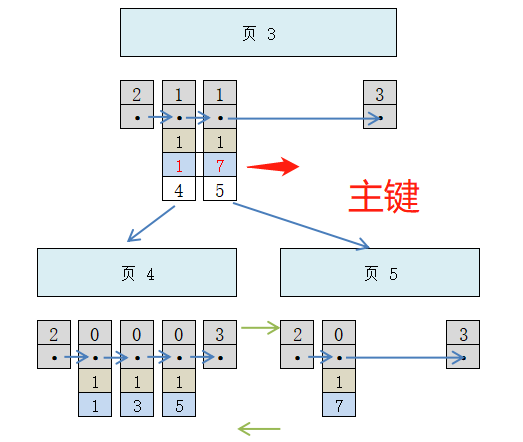
现在,当插入新记录9、1、'c'时:
- 可以先把新记录的 c2 列的值和页 3 中各目录项记录的 c2 列的值进行比较。
- 如果 c2 列的值相同,就接着比较主键值。
所以,对于二级索引来说,给 c2 列建索引,其实就相当于用c2、c1建立了一个联合索引。先按照二级索引的值进行排序,在二级索引列值相同的情况下,再按照主键值进行排序。
三、一个页面至少容纳 2 条记录
在之前的文章里提到过,B+ 树其实只需要很少的层级就可以轻松存储数亿条记录,查询速度还很快。
这是因为 B+ 树本质上就是一个大的多层级目录。每经过一个目录时都会过滤许多无效的子目录,直到最后访问到存储真正数据的目录。
那么现在不妨设想一下:还是同样的数据量,如果一个大的目录只存放一个子目录,又是什么样子?
- 目录层级非常多
- 最后那个存放真正数据的目录中只能存放一条记录
如果是这样的话,这种B+ 树结构就没什么意义了,不能形成一个有效的索引。
于是,设计 innoDB的大佬为了避免 B+树的层级增长得过高,要求所有数据页都至少可以存放2条记录。
本文参考书籍:《mysql是怎样运行的》
以上就是Mysql InnoDB中B+树索引的注意事项的详细内容,更多关于Mysql InnoDB中B+树索引的资料请关注我们其它相关文章!
相关推荐
-

MySQL中B树索引和B+树索引的区别详解
目录 1.多路搜索树 2.B树-多路平衡搜索树 3.B树索引 4.B+树索引 总结 如果用树作为索引的数据结构,每查找一次数据就会从磁盘中读取树的一个节点,也就是一页,而二叉树的每个节点只存储一条数据,并不能填满一页的存储空间,那多余的存储空间岂不是要浪费了?为了解决二叉平衡搜索树的这个弊端,我们应该寻找一种单个节点可以存储更多数据的数据结构,也就是多路搜索树. 1. 多路搜索树 1.完全二叉树高度:O(log2N),其中2为对数,树每层的节点数: 2.完全M路搜索树的高度:O(logmN),其
-
MySQL用B+树作为索引结构有什么好处
前言 在MySQL中,无论是Innodb还是MyIsam,都使用了B+树作索引结构(这里不考虑hash等其他索引).本文将从最普通的二叉查找树开始,逐步说明各种树解决的问题以及面临的新问题,从而说明MySQL为什么选择B+树作为索引结构. 一.二叉查找树(BST):不平衡 二叉查找树(BST,Binary Search Tree),也叫二叉排序树,在二叉树的基础上需要满足:任意节点的左子树上所有节点值不大于根节点的值,任意节点的右子树上所有节点值不小于根节点的值.如下是一颗BST: 当需要快速查
-
MySQL的索引系统采用B+树的原因解析
目录 1.什么是索引? 2.为什么需要索引? 3.如何设计索引系统? 4.MYSQL索引系统是什么呢? 5.哈希表 6.树 6.1 二叉树 6.2 二分查找树(Binary Search Tree ,BST) 6.3 平衡二叉树(Balanced Binary Tree, AVL树) 6.4 红黑树 6.5 B树 6.6 B+树 总结 1.什么是索引? 索引是为了加速对表中数据行的检索而创建的一种分散的存储结构.(就好像我们小时候用的字典,有了字典查到对应的字就会变快) 2.为什么需要索引? 首
-
mysql 使用B+树索引有哪些优势
搞懂这个问题之前,我们首先来看一下MySQL表的存储结构,再分别对比二叉树.多叉树.B树和B+树的区别就都懂了. MySQL的存储结构 表存储结构 单位:表>段>区>页>行 在数据库中, 不论读一行,还是读多行,都是将这些行所在的页进行加载.也就是说存储空间的基本单位是页. 一个页就是一棵树B+树的节点,数据库I/O操作的最小单位是页,与数据库相关的内容都会存储在页的结构里. B+树索引结构 在一棵B+树中,每个节点为都是一个页,每次新建节点的时候,就会申请一个页空间 同一层的节点
-
Mysql InnoDB B+树索引目录项记录页管理
目录 Mysql InnoDB B+树索引目录项记录管理 一.目录项记录页 二.当目录项记录页也变多后 三.B+ 树 Mysql InnoDB B+树索引目录项记录管理 接上一篇内容,InnoDB 的作者想到一种更灵活的方式来管理所有目录项,是什么? 一.目录项记录页 其实这些用户目录项与用户记录很像,只是目录项中的两个列记录的是主键和页号而已,那么就可以复用之前存储用户记录的数据页来存储目录项. 为了区分用户记录和目录项,仍然使用 record_type 这个属性,当值为 1 时,表示目录项记
-
Mysql InnoDB中B+树索引使用注意事项
目录 一.根页面万年不动 二.内节点中目录项记录的唯一性 三.一个页面至少容纳 2 条记录 一.根页面万年不动 在之前的文章里,为了方便理解,都是先画存储用户记录的叶子节点,然后再画出存储目录项记录的内节点. 但实际上 B+ 树的行成过程是这样的: 每当为某个表创建一个 B+ 树索引,都会为这个索引创建一个根节点页面.最开始表里没数据,所以根节点中既没有用户记录,也没有目录项记录. 当往表里插入用户记录时,先把用户记录存储到这个根节点上. 当根节点页空间用完,继续插入记录,此时会将根节点中所有记
-
MySQL优化中B树索引知识点总结
为什么要进行SQL优化呢?很显然,当我们去写sql语句时: 1会发现性能低 2.执行时间太长, 3.或等待时间太长 4.sql语句欠佳,以及我们索引失效 5.服务器参数设置不合理 SQL语句执行过程分析 1.编写过程: 编写过程就是我们平常写sql语句的过程,也可以理解为编写顺序,以下就是我们编写顺序: select from join on where 条件 group by 分组 having过滤组 order by排序 limit限制查询个数 我们虽然是这样去写的,但是它mysql的引擎去
-
Mysql Innodb存储引擎之索引与算法
目录 一.概述 二.数据结构与算法 1.二分查找 2.二叉查找树和平衡二叉树 1)二叉查找树 2)平衡二叉树 三.B+树 1.B+树完整定义 2.关于 M 和 L的选定案例 四.B+树索引 1.聚集索引 2.辅助索引 五.关于 Cardinality 值 1.Cardinality定义 2.Cardinality的更新 六.B+树索引的使用 1.联合索引 2.覆盖索引 3.优化器选择不使用索引的情况 4.索引提示 5.Multi-Range Read 优化 (MRR) 6.Index Condi
-
MySQL InnoDB中的锁机制深入讲解
写在前面 数据库本质上是一种共享资源,因此在最大程度提供并发访问性能的同时,仍需要确保每个用户能以一致的方式读取和修改数据.锁机制(Locking)就是解决这类问题的最好武器. 首先新建表 test,其中 id 为主键,name 为辅助索引,address 为唯一索引. CREATE TABLE `test` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` int(11) NOT NULL, `address` int(11) NOT NULL, P
-
MySQL批量插入和唯一索引问题的解决方法
MySQL批量插入问题 在开发项目时,因为有一些旧系统的基础数据需要提前导入,所以我在导入时做了批量导入操作 ,但是因为MySQL中的一次可接受的SQL语句大小受限制所以我每次批量虽然只有500条,但依然无法插入,这个时候代码报错如下: nested exception is com.mysql.jdbc.PacketTooBigException: Packet for query is too large (5677854 > 1048576). You can change this va
-
浅谈MySQL的B树索引与索引优化小结
MySQL的MyISAM.InnoDB引擎默认均使用B+树索引(查询时都显示为"BTREE"),本文讨论两个问题: 为什么MySQL等主流数据库选择B+树的索引结构? 如何基于索引结构,理解常见的MySQL索引优化思路? 为什么索引无法全部装入内存 索引结构的选择基于这样一个性质:大数据量时,索引无法全部装入内存. 为什么索引无法全部装入内存?假设使用树结构组织索引,简单估算一下: 假设单个索引节点12B,1000w个数据行,unique索引,则叶子节点共占约100MB,整棵树最多20
-
深入讲解MySQL Innodb索引的原理
引言 回想四年前,我在学习mysql的索引这块的时候,老师在讲索引的时候,是像下面这么说的 索引就像一本书的目录.而当用户通过索引查找数据时,就好比用户通过目录查询某章节的某个知识点.这样就帮助用户有效地提高了查找速度.所以,使用索引可以有效地提高数据库系统的整体性能. 嗯,这么说其实也对.但是呢,大家看完这种说法,其实可能还是觉得太抽象了!因此呢,我还想再深入的细说一下,所以就有了此文! 需要说明的是,我说的内容只在Mysql的Innodb引擎中是成立的.在Sql Server.oracle.
-
Mysql InnoDB引擎的索引与存储结构详解
前言 在Oracle 和SQL Server等数据库中只有一种存储引擎,所有数据存储管理机制都是一样的. 而MySql数据库提供了多种存储引擎.用户可以根据不同的需求为数据表选择不同的存储引擎,用户也可以根据自己的需要编写自己的存储引擎. MySQL主要存储引擎的区别 MySQL默认的存储引擎是MyISAM,其他常用的就是InnoDB,另外还有MERGE.MEMORY(HEAP)等. 主要的几个存储引擎 MyISAM管理非事务表,提供高速存储和检索,以及全文搜索能力. MyISAM是Mysql的