Python-jenkins模块获取jobs的执行状态操作
1 获取jobs的当前任务状态
server_1 = jenkins.Jenkins('http://%s:%s@192.168.37.134:8081/',username, password)
获取状态前先确认2019文件夹下的get_node_list任务是否存在:
server_1.assert_job_exists('2019/get_node_list')
获取最后一次完成(不包括执行中的)的job任务执行number:
server_1.get_job_info('2019/get_node_list')['lastCompletedBuild']['number']
查看job状态(SUCCESS/FAILURE/ABORTED):
server_1.get_build_info('2019/get_node_list',3)['result']
server_1.get_build_console_output('2019/get_node_list',7).split('\n')[-2].split(':')[-1].strip()
启动jobs:
server_1.build_job('2019/get_node_list')
在job执行结束前使用server_1.get_build_console_output(‘2019/get_node_list',7).split('\n')[-2].split(':')[-1].strip()获取的状态信息不符合预期。
job状态应该还包括running,pending状态,那么获取job的当前状态正确姿势如下:
job_name = '2019/get_node_list'
def get_jobs_status(job_name,server):
try:
server.assert_job_exists(job_name)
except Exception as e:
print(e)
job_statue = '1'
#判断job是否处于排队状态
inQueue = server.get_job_info(job_name)['inQueue']
if str(inQueue) == 'True':
job_statue = 'pending'
running_number = server.get_job_info(job_name)['nextBuildNumber']
else:
#先假设job处于running状态,则running_number = nextBuildNumber -1 ,执行中的job的nextBuildNumber已经更新
running_number = server.get_job_info(job_name)['nextBuildNumber'] -1
try:
running_status = server.get_build_info(job_name,running_number)['building']
if str(running_status) == 'True':
job_statue = 'running'
else:
#若running_status不是True说明job执行完成
job_statue = server.get_build_info(job_name,running_number)['result']
except Exception as e:
#上面假设job处于running状态的假设不成立,则job的最新number应该是['lastCompletedBuild']['number']
lastCompletedBuild_number = server.get_job_info(job_name)['lastCompletedBuild']['number']
job_statue = server.get_build_info(job_name,lastCompletedBuild_number)['result']
return job_statue,running_number
注意:
可能还存在下图的情况,这个时候获取的是26的状态,这时候也许你想获取25的状态,26是不小心误操作触发的,这个时候任务的最新状态也许就无法满足预期要求,或者是支持并发构建的job场景中就不适用了,关键还是需要结合应用场景制定对应的方案。

2 统计jobs的执行成功率和平均执行时间
统计场景说明:
设计了一个统计job执行成功率的工程,主要从执行时间以及视图两个维度来划定需要统计的jobs及jobs对应的运行范围。
在这里我在job里面添加了DAYS和VIEWS两个参数:
**DAYS:**默认统计最近一天的运行情况,如果执行的时候输入的是0则代表统计所有的运行情况。
**VIEWS:**对应的是视图名称,“2019-1,test”代表统计这两个视图的运行情况

对应的视图如下:

执行成功后以表格形式列出统计的数据,表头如下

列出了序号、视图名称、job名称、job执行成功的平均执行时间、job执行成功次数、总的执行时间、job执行成功率
job执行演示:
执行构建时配置的参数如下
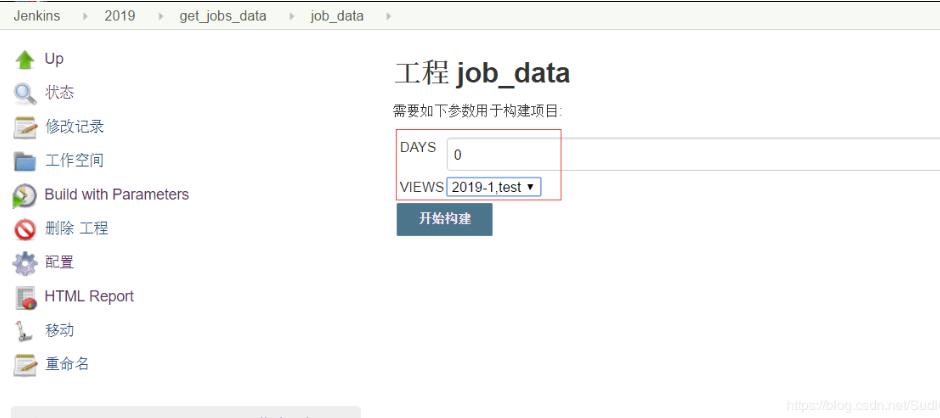
job_data任务的主要执行内容如下:

执行成功后查看HTML_Report统计的数据如下:

get_job_data.py源码如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: Sudley
# ctime: 2020/02/12
import sys
import jenkins
import time
from dominate.tags import *
def Count_the_success_rate_of_jobs(days,views):
username = 'sudley'
password = '******'
with open('//home/Sudley/python-jenkins/get_job_data.txt','w') as f:
print('create a new file //home/Sudley/python-jenkins/get_job_data.txt')
serial_number = 0 #统计任务的累计序号
for view in views.split(','):
#根据视图名称拼接视图的URL,多个视图间用','分隔
URL = ('http://%s:%s@192.168.37.134:8081/job/2019/view/%s/')%(username, password, view)
server = jenkins.Jenkins(URL)
#依次获取当前view视图中jobs的信息
for num in range(0,len(server.get_all_jobs())):
job_name = server.get_all_jobs()[num]['fullname']
#获取最后一次完成构建的编号,用于划定时间范围(如果需要的话)
try:
lastCompletedBuild_num = server.get_job_info(job_name)['lastCompletedBuild']['number']
except:
#假如job下面一个构建记录都没有则补0
print('There is not build number in',job_name)
average_success_duration = success_count = all_count = success_rate = 0
line = str(serial_number) + ' ' + view + ' ' + job_name + ' ' + str(int(average_success_duration)) + ' ' + str(success_count) + ' ' + str(all_count) + ' ' + str(success_rate) + '%'
with open('//home/Sudley/python-jenkins/get_job_data.txt','a') as f:
f.write(str(line))
f.write('\n')
serial_number = serial_number + 1
continue
#获取最后一次完成构建的时间戳,单位由毫秒转换为秒
lastCompletedBuild_timestamp = server.get_build_info(job_name,lastCompletedBuild_num)['timestamp'] / 1000
#将时间先由秒转化为元组在转化为字符串并取到天数
lastCompletedBuild_date = time.strftime("%Y%m%d",time.localtime(lastCompletedBuild_timestamp))
#print(lastCompletedBuild_date)
#根据变量days和lastCompletedBuild_timestamp计算出days天前的日期,若days为0则没有日期限制,统计之前运行的所有任务
if str(days) == '0':
end_date = 'false'
else:
end_timestamp = float(lastCompletedBuild_timestamp) - float(days) * 24 * 3600
end_date = time.strftime("%Y%m%d",time.localtime(end_timestamp))
#print(end_date)
#获取days天内job的执行情况
success_count = 0 #job执行成功的总数
success_duration = 0 #执行成功的job执行时间之和,单位是s
for number in range(0,len(server.get_job_info(job_name)['builds'])):
job_build_number = server.get_job_info(job_name)['builds'][number]['number']
job_build_timestamp = server.get_build_info(job_name,job_build_number)['timestamp'] / 1000
job_build_date = time.strftime("%Y%m%d",time.localtime(job_build_timestamp))
#如果日期和end_date相同则终止此job数据的累计
if job_build_date == end_date:
number = number - 1
break
#累计执行成功的次数和duration执行时间
job_build_result = server.get_build_info(job_name,job_build_number)['result']
if str(job_build_result) == 'SUCCESS':
job_build_duration = server.get_build_info(job_name,job_build_number)['duration']
success_duration = success_duration + job_build_duration / 1000
success_count = success_count + 1
#计算执行成功的平均执行时间和成功率,打印关键信息
all_count = number + 1
success_rate = success_count * 1.0 / all_count * 100
if success_count == 0:
average_success_duration = success_duration
else:
average_success_duration = success_duration * 1.0 / success_count
#将关心的数据按照一定的格式写到/home/Sudley/python-jenkins/get_job_data.txt文件中
line = str(serial_number) + ' ' + view + ' ' + job_name + ' ' + str(int(average_success_duration)) + ' ' + str(success_count) + ' ' + str(all_count) + ' ' + str(round(success_rate,2)) + '%'
with open('//home/Sudley/python-jenkins/get_job_data.txt','a') as f:
f.write(str(line))
f.write('\n')
serial_number = serial_number + 1
def txt2xml():
h = html()
with h.add(body()):
h2('job执行效率统计')
caption('summary:')
with table(border="2",cellspacing="0"):
l = tr(bgcolor="#0000FF")
l += th('序号')
l += th('view_name')
l += th('job_name')
l += th('average_success_duration')
l += th('success_count')
l += th('all_count')
l += th('success_rate')
file=open('/home/Sudley/python-jenkins/get_job_data.txt')
for line in file.readlines():
curLine=line.strip().split(" ")
l = tr()
for i in range(0,len(curLine)):
l += td(curLine[i])
with open('/home/Sudley/python-jenkins/get_job_data.html','w') as f:
f.write(h.render())
if __name__ == '__main__' :
days = sys.argv[1]
views = sys.argv[2]
Count_the_success_rate_of_jobs(days,views)
txt2xml()
以上这篇Python-jenkins模块获取jobs的执行状态操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
基于Python的Jenkins的二次开发操作
背景 最近我们在整一个云执行的平台,底层用的是Jenkins来做执行引擎,方便的把我们的脚本做一个统一的调度. Jenkins确实是一个非常方便的框架,它提供了一整套的RESTful的API,可以非常方便的做二次开发,而且提供了一个python的库,操作起来就更加方便了. 常用的Jenkins概念 我们在使用Jenkins的时候,一般看到的都是Jenkins的View. 也就是说我们看到的基本上都是一些视图. 每一个构建的内容,无论是执行用例,跑脚本,还是打包编译发布,都是一个job. 每一个j
-
Python-jenkins 获取job构建信息方式
官方文档: 需求:当1个job启动构建后,获取它的构建状态.(成功,失败,驳回,构建中,正在排队) 关键函数: 获取job是否在排队的结果 获取正在排队构建的job队列 即pending状态中的所有job,如果没有 pending状态的job即返回1个空列表 queue_info = server.get_queue_info() 获取job构建结果 server.get_build_info(name, build_number)[ 'result'] # 构建结束 SUCCESS|FAILU
-
jenkins配置python脚本定时任务过程图解
这篇文章主要介绍了jekins配置python脚本定时任务过程图解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.首先安装jekins环境,访问网页https://jenkins.io/zh/download/,下载长期稳定版如下: 2.下载安装包后直接运行,进行选择安装路径,傻瓜式安装.安装完成后,点Finished,弹出jekins输入密匙网页,根据网页提示路径,找到 对应的jekins密匙输入后,选择推荐插件安装即可.(也可以不安装插
-
python jenkins 打包构建代码的示例代码
python jenkins 打包构建代码 # pip install python-jenkins import jenkins import pprint import time # 在jenkins 的Configure Global Security下 , 取消"防止跨站点请求伪造(Prevent Cross Site Request Forgery exploits)"的勾选 server = jenkins.Jenkins('http://192.168.100.151:8
-
Python-jenkins模块获取jobs的执行状态操作
1 获取jobs的当前任务状态 server_1 = jenkins.Jenkins('http://%s:%s@192.168.37.134:8081/',username, password) 获取状态前先确认2019文件夹下的get_node_list任务是否存在: server_1.assert_job_exists('2019/get_node_list') 获取最后一次完成(不包括执行中的)的job任务执行number: server_1.get_job_info('2019/get
-

python简单直接获取windows明文密码操作技巧
目录 01.Procdump+Mimikatz 02.Window 2012 R2抓取密码 03.MSF kiwi模块 01.Procdump+Mimikatz 利用procdump+Mimikatz 绕过杀软获取Windows明文密码. (1)工具准备: ProcDump: https://docs.microsoft.com/zh-cn/sysinternals/downloads/procdump mimikatz: https://github.com/gentilkiwi/mimika
-
Python wxpython模块响应鼠标拖动事件操作示例
本文实例讲述了Python wxpython模块响应鼠标拖动事件操作.分享给大家供大家参考,具体如下: wxpython鼠标拖动事件小案例: #coding:UTF-8 import wx app = wx.App() def dragEVT(event): if event.ButtonDown(): panel1.SetPosition(event.GetPosition()) elif event.Dragging(): panel1.SetPosition(event.GetPositi
-
python wav模块获取采样率 采样点声道量化位数(实例代码)
安装: pip install wave 在wav 模块中 ,主要介绍一种方法:getparams(),该方法返回的结果如下: _wave_params(nchannels=1, sampwidth=2, framerate=48000, nframes=171698592, comptype='NONE', compname='not compressed') 参数解释: nchannels:声道数 sampwidth:量化位数(byte) framerate:采样频率 nframes:采样点
-
Node.js path模块,获取文件后缀名操作
我就废话不多说了,大家还是直接看代码吧~ demo.js: //path模块 var path=require('path'); /*nodejs自带的模块*/ var extname=path.extname("123.html"); //获取文件的后缀名 console.log(extname); 补充知识:node 的path模块中 path.resolve()和path.join()的区别 一.path模块的引入. 直接引用.node中自带的模块 const path = re
-
Python xlrd模块导入过程及常用操作
简介 读取Excle文档,支持xls,xlsx格式 安装:pip3 install xlrd 导入:import xlrd xlrd 模块方法 读取Excel file = 'route_info.xls' # 读取Excel信息,生成对象 read_book = xlrd.open_workbook(file) 获取sheet[表]相关方法,返回xlrd.sheet.Sheet()对象 sheet = read_book.sheets() # 获取全部sheet列表 print(sheet)
-
python—sys模块之获取参数的操作
sys模块:全称system,指的是解释器. 常用操作,用于接收系统操作系统调用解释器传入的参数 1. sys.argv 获取脚本传递的所有参数,返回一个列表.列表中的所有元素均为脚本传递的参数. sys.argv[0] # 脚本传递的第一个参数,固定为脚本名称,可以通过次方式获得脚本名称 可以使用索引依次获得脚本传递的其他参数 2. sys.version 获取解释器的版本信息,返回一个字符串.根据python版本编写符合不同版本的程序 使程序可兼容 3.6.4 (default, Aug 1
-
Python Image模块基本图像处理操作小结
本文实例讲述了Python Image模块基本图像处理操作.分享给大家供大家参考,具体如下: Python 里面最常用的图像操作库是Image library(PIL),功能上,虽然还不能跟Matlab比较,但是还是比较强大的,废话补多少,写点记录笔记. 1. 首先需要导入需要的图像库: import Image 2. 读取一张图片: im=Image.open('/home/Picture/test.jpg') 3. 显示一张图片: im.show() 4. 保存图片: im.save("sa
-
Python使用crontab模块设置和清除定时任务操作详解
本文实例讲述了Python使用crontab模块设置和清除定时任务操作.分享给大家供大家参考,具体如下: centos7下安装Python的pip root用户使用yum install -y python-pip 时会报如下错误: No package python-pip available Error:Nothing to do 解决方法如下: 首先安装epel扩展源: yum -y install epel-release 更新完成之后,就可安装pip: yum -y install p
-
使用Python paramiko模块利用多线程实现ssh并发执行操作
1.paramiko概述 ssh是一个协议,OpenSSH是其中一个开源实现,paramiko是Python的一个库,实现了SSHv2协议(底层使用cryptography). 有了Paramiko以后,我们就可以在Python代码中直接使用SSH协议对远程服务器执行操作,而不是通过ssh命令对远程服务器进行操作. 由于paramiko属于第三方库,所以需要使用如下命令先行安装 2.安装paramiko pip install paramiko 3.常用方法 connect():实现远程服务器的