一次因表变量导致SQL执行效率变慢的实战记录
目录
- 场景
- JOB执行流程分析
- 逐一排除问题
- 解决问题
- 1.通过使用临时表代替表变量
- 2.修改目标TableB的写入逻辑
- 总结
场景
最近工作中,发现某同步JOB在执行中经常抛出SQL执行超时的问题,查看日志发现每次SQL执行的时间都是线性增长的,循环执行50次以后执行时间甚至超过了5分钟
JOB执行流程分析
首先,对于JOB流程进行分析,查看是否是JOB设计上的问题
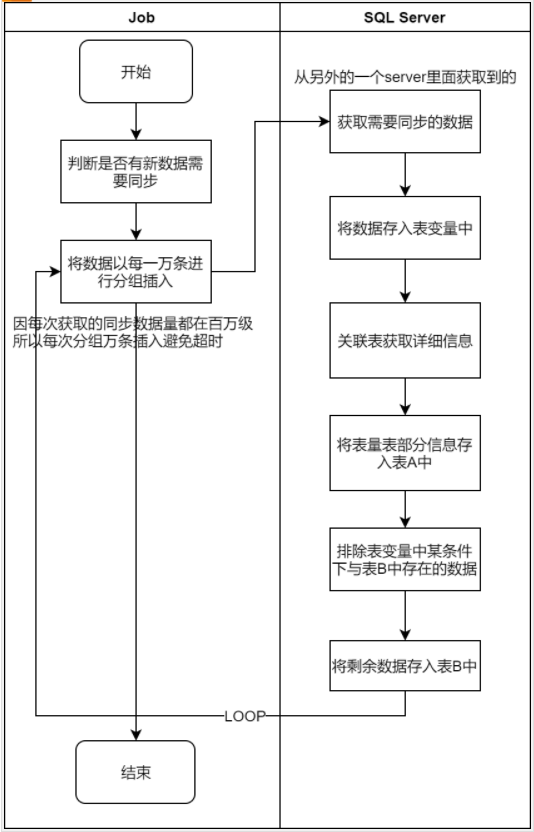
通过对流程的分析,发现每次获取的需要同步的数据最多只有一万条,不存在大数据写入导致超时的问题。
那么在对获取详细信息这个过程进行分析,发现关联的表中最多的数据已经上亿了,可能是这里导致了整体SQL执行变慢的原因。这里能算可疑点一。
再接着往下一个流程看与表B对比重复数据时,随着循环执行表B的数据会越来越多,那么会不会这里是导致循环执行下执行时间称线性增长的主要原因呢。
逐一排除问题
之前我们通过分析JOB执行流程,发现了两个可疑点,那么现在具体分析SQL的问题
CREATE TABLE #TableTemp (
字段A int null,
字段B int null,
字段C int null
)
INSERT INTO #TableTemp(
字段A,
字段B
)SELECT
a.字段A,
字段B
FROM ServerA.dbo.TableB a WITH(NOLOCK)
LEFT JOIN dbo.TableA b WITH(NOLOCK) a.Id = b.Id
UPDATE a
SET a.字段C = b.字段D
FROM #TableTemp a
LEFT JOIN dbo.TableC b WITH(NOLOCK) ON a.字段A =b.id
INSERT INTO dbo.目标TableA(
字段A,
字段B
)
SELECT
字段A,
字段B
FROM #TableTemp WITH(NOLOCK)
INSERT INTO dbo.目标TableB(
字段A,
字段B,
字段C
)
SELECT DISTINCT
a.字段A,
a.字段B,
a.字段C
FROM #TableTemp a WITH(NOLOCK)
LEFT JOIN dbo.目标TableB b ON a.字段A = b.字段A AND a.字段B = b.字段B
WHERE a.PK IS NULL
先来查看可疑点一,是不是这里出了问题。因为表TableC数据已经是几亿的量,但单独将该SQL执行发现,因为索引的存在发现执行并不是特别慢,所以可以排除掉该问题
那么来看看可疑点二呢
INSERT INTO dbo.目标TableB(
字段A,
字段B,
字段C
)
SELECT DISTINCT
a.字段A,
a.字段B,
a.字段C
FROM #TableTemp a WITH(NOLOCK)
LEFT JOIN dbo.目标TableB b ON a.字段A = b.字段A AND a.字段B = b.字段B
WHERE a.PK IS NULL
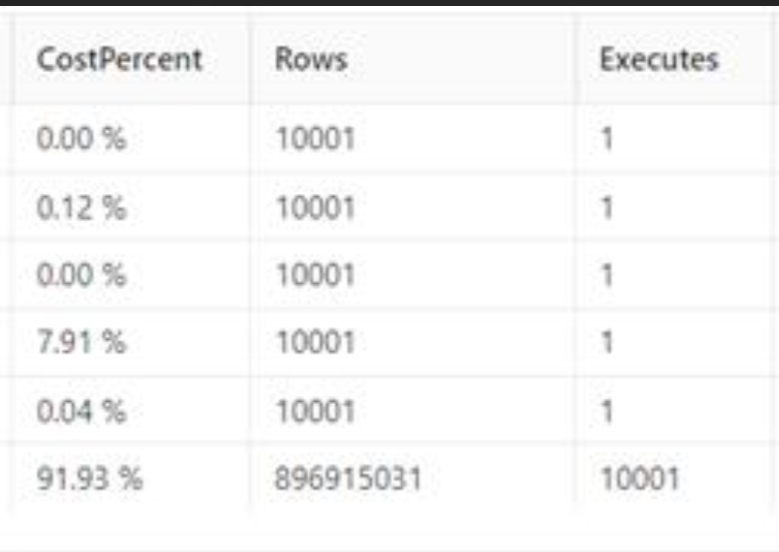
可以看到该SQL插入的同时还查询了自身是否存在条件下相同的数据,查看表目标TableB发现,该表没有主键也没有索引,再通过DBA那边提供的SQL分析发现,这句SQL对于dbo.目标TableB进行了全表扫描,再加上插入的1W条数据,相当于对于dbo.目标TableB全表扫描了1w次,随着循环的执行该表数据越来越多,执行时间也就越来越长,看来这里就是导致执行时间线性增长的主要原因了。
解决问题
根据上面问题的排除,我们已经得知问题的关键所在就是进行了1w次的全表扫描,导致了SQL执行时间过长,那么解决问题的关键所在就是避免这么多次的全表扫描。那么最直接的解决方法,就是建立索引避免全表扫描
1.通过使用临时表代替表变量
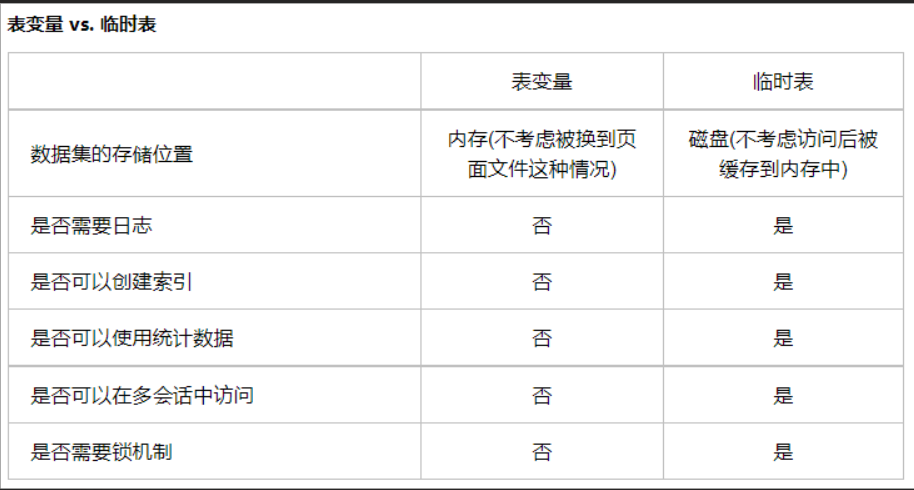
先来看看,表变量与临时表的区别,可以看到表变量是无法使用索引的,所以我们使用索引避免全表扫描的话必须要代替掉表变量,然后在临时表的字段A上我们创建索引
2.修改目标TableB的写入逻辑
现有写入逻辑会先判断是否在目标TableB中是否存在,不存在时则写入表中,保持业务的情况下,我们稍微修改下逻辑,再写入之前先排除掉与目标TableB中的数据,将剩余数据写入表中,就能避免循环1W次的目标TableB表查询了
通过这两处修改后,再执行该JOB发现问题得到了完美的解决。
总结
到此这篇关于因表变量导致SQL执行效率变慢的文章就介绍到这了,更多相关表变量导致SQL执行变慢内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
腾讯面试:一条SQL语句执行得很慢的原因有哪些?---不看后悔系列(推荐)
说实话,这个问题可以涉及到 MySQL 的很多核心知识,可以扯出一大堆,就像要考你计算机网络的知识时,问你"输入URL回车之后,究竟发生了什么"一样,看看你能说出多少了. 之前腾讯面试的实话,也问到这个问题了,不过答的很不好,之前没去想过相关原因,导致一时之间扯不出来.所以今天,我带大家来详细扯一下有哪些原因,相信你看完之后一定会有所收获,不然你打我. 开始装逼:分类讨论 一条 SQL 语句执行的很慢,那是每次执行都很慢呢?还是大多数情况下是正常的,偶尔出现很慢呢?所以我觉得,我们还得
-
根据mysql慢日志监控SQL语句执行效率
根据mysql慢日志监控SQL语句执行效率 启用MySQL的log-slow-queries(慢查询记录). 在Linux环境下先要找到my.cnf文件(一般在/etc/mysql/),然后可能会发现该文件修改后无法保存,原因是你没有相应的权限,可以从属性中看到该文件的所有者是root,这时要先以root的身份打开它: sudo nautilus /etc/mysql 接着再打开my.cnf文件然后找到[mysqld]标签在下面加上: log-slow-queries=/path/slow.lo
-

一次因表变量导致SQL执行效率变慢的实战记录
目录 场景 JOB执行流程分析 逐一排除问题 解决问题 1.通过使用临时表代替表变量 2.修改目标TableB的写入逻辑 总结 场景 最近工作中,发现某同步JOB在执行中经常抛出SQL执行超时的问题,查看日志发现每次SQL执行的时间都是线性增长的,循环执行50次以后执行时间甚至超过了5分钟 JOB执行流程分析 首先,对于JOB流程进行分析,查看是否是JOB设计上的问题 通过对流程的分析,发现每次获取的需要同步的数据最多只有一万条,不存在大数据写入导致超时的问题. 那么在对获取详细信息这个过程进行
-
MySql批量插入优化Sql执行效率实例详解
MySql批量插入优化Sql执行效率实例详解 itemcontractprice数量1万左右,每条itemcontractprice 插入5条日志. updateInsertSql.AppendFormat("UPDATE itemcontractprice AS p INNER JOIN foreigncurrency AS f ON p.ForeignCurrencyId = f.ContractPriceId SET p.RemainPrice = f.RemainPrice * {0},
-
Oracle提高sql执行效率的心得建议
复制代码 代码如下: -->FROM子句中包含多个表的情况下,选择记录条数最少的表作为基础表 -->解析WHERE子句是自下而上的 过滤条件要有顺序 -->ORACLE会将'*'转换成列名 -->DELETE会在rollback segment中存放可恢复信息,可以试试TRUNCATE -->COMMIT会释放:1.rollback segment 2.被程序语句获得的锁 3.redo log buffer -->把Alias前缀于每个Column上可以减少解析的时间
-
Oracle提高SQL执行效率的3种方法
Oracle提供了多种方法用于减少花在剖析Oracle SQL表达式上的时间,在执行带有大量执行计划的复杂查询时剖析过程会拖累系统的性能.现在我们来简要地看看这些方法中的几种. 1.使用ordered提示 Oracle必须花费大量的时间来剖析多表格的合并,用以确定表格合并的最佳顺序.如果SQL表达式涉及七个乃至更多的表格合并,那么有时就会需要超过30分钟的时间来剖析,因为Oracle必须评估表格合并所有可能的顺序.八个表格就会有40,000多种顺序.Ordered这个提示(hint)和其他的提示
-
SQL Server2019安装的详细步骤实战记录(亲测可用)
目录 共存问题 安装 总结 共存问题 我之前一直使用的是SQL2012版本的数据库管理工具,为了与时俱进,我也尝试更新一下版本,当然SQLServer管理工具是可以多版本并存的,也就是你可以不用卸载你之前的版本,继续安装新版本使用. 安装 第一步:打开微软官方,下载数据库,通常我们下载Express版本. 数据库下载地址:https://www.microsoft.com/zh-cn/sql-server/sql-server-downloads 第二步:将下载下来的程序打开安装,会显示如下对话
-
SQL Server 表变量和临时表的区别(详细补充篇)
一.表变量 表变量在SQL Server 2000中首次被引入.表变量的具体定义包括列定义,列名,数据类型和约束.而在表变量中可以使用的约束包括主键约束,唯一约束,NULL约束和CHECK约束(外键约束不能在表变量中使用).定义表变量的语句是和正常使用Create Table定义表语句的子集.只是表变量通过DECLARE @local_variable语句进行定义. 表变量的特征: 1.表变量拥有特定作用域(在当前批处理语句中,但不在任何当前批处理语句调用的存储过程和函数中),表变量在批处理结束
-
关于SQL执行计划错误导致临时表空间不足的问题
故障现象:临时表空间不足的问题已经报错过3次,客户也烦了,前两次都是同事添加5G的数据文件,目前已经达到40G,占用临时表空间主要是distinct 和group by 以及Union all 表数据量在200W左右,也不至于把40G的临时表空间撑爆. 原因分析:既然排序用不了这么多临时表空间应该是别的原因造成. 从包含故障时间段的AWR报告中可以看出这一阶段DBtime蛮高的,并且sql execute elapsed time 竟然占到了99.43%,可以断定是SQL语句引起的. 通过TOP
-
SQL Server并行操作优化避免并行操作被抑制而影响SQL的执行效率
为什么我也要说SQL Server的并行: 这几天园子里写关于SQL Server并行的文章很多,不管怎么样,都让人对并行操作有了更深刻的认识. 我想说的是:尽管并行操作可能(并不是一定)存在这样或者那样的问题,但是我们不能否认并行,仍然要利用好并行. 但是,实际开发中,某些SQL语句的写法会导致用不到并行,从而影响到SQL的执行效率 所以,本文要表达的是:我们要利用好并行,不要让一些SQL的写法问题"抑制"了并行,让我们享受不了并行带来的快感 关于SQL Server的并行: 所谓的
-
sqlserver 临时表 Vs 表变量 详细介绍
这里我们在SQL Server 2005\SQL Server 2008版本上通过举例子,说明临时表和表变量两者的一些特征,让我们对临时表和表变量有进一步的认识.在本章中,我们将从下面几个方面去进行描述,对其中的一些特征举例子说明: 约束(Constraint) 索引(Index) I/0开销 作用域(scope) 存儲位置 其他 例子描述 约束(Constraint) 在临时表和表变量,都可以创建Constraint.针对表变量,只有定义时能加Constraint. e.g.在Microsof
-
查询mysql中执行效率低的sql语句的方法
一些小技巧1. 如何查出效率低的语句?在MySQL下,在启动参数中设置 --log-slow-queries=[文件名],就可以在指定的日志文件中记录执行时间超过long_query_time(缺省为10秒)的SQL语句.你也可以在启动配置文件中修改long query的时间,如: 复制代码 代码如下: # Set long query time to 8 seconds long_query_time=8 2. 如何查询某表的索引?可使用SHOW INDEX语句,如: 复制代码 代码如下