Python多线程编程之threading模块详解
一、介绍
线程是什么?线程有啥用?线程和进程的区别是什么?
线程是操作系统能够进行运算调度的最小单位。被包含在进程中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
二、Python如何创建线程
2.1 方法一:
创建Thread对象
步骤:
1.目标函数
2.实例化Thread对象
3.调用start()方法
import threading
# 目标函数1
def fun1(num):
for i in range(num):
print('线程1: 第%d次循环:' % i)
# 目标函数2
def fun2(lst):
for ele in lst:
print('线程2: lst列表中元素 %d' % ele)
def main():
num = 10
# 实例化Thread对象
# target参数一定为一个函数,且不带括号
# args参数为元组类型,参数为一个时一定要加逗号
t1 = threading.Thread(target=fun1, args=(num,))
t2 = threading.Thread(target=fun2, args=([1, 2, 3, 4, 5],))
# 调用start方法
t1.start()
t2.start()
if __name__ == '__main__':
main()
2.2 方法二:
创建子类继承threading.Thread类
import threading
import os
class Person(threading.Thread):
def run(self):
self.sing(5)
self.cook()
@staticmethod
def sing(num):
for i in range(num):
print('线程[%d]: The person sing %d song.' % (os.getpid(), i))
@staticmethod
def cook():
print('线程[%d]:The person has cooked breakfast.' % os.getpid())
def main():
p1 = Person()
p1.start()
p2 = Person()
p2.start()
if __name__ == '__main__':
main()
三、线程的用法
3.1 确定当前的线程
import threading
import time
import logging
def fun1():
print(threading.current_thread().getName(), 'starting')
time.sleep(0.2)
print(threading.current_thread().getName(), 'exiting')
def fun2():
# print(threading.current_thread().getName(), 'starting')
# time.sleep(0.3)
# print(threading.current_thread().getName(), 'exiting')
logging.debug('starting')
time.sleep(0.3)
logging.debug('exiting')
logging.basicConfig(
level=logging.DEBUG,
format='[%(levelname)s] (%(threadName)-10s) %(message)s'
)
def main():
t1 = threading.Thread(name='线程1', target=fun1)
t2 = threading.Thread(name='线程2', target=fun2)
t1.start()
t2.start()
if __name__ == '__main__':
main()
3.2 守护线程
区别
- 普通线程:主线程等待子线程关闭后关闭
- 守护线程:管你子线程关没关,主线程到时间就关闭
守护线程如何搞
- 方法1:构造线程时传入dameon=True
- 方法2:调用setDaemon()方法并提供参数True
import threading
import time
import logging
def daemon():
logging.debug('starting')
# 添加延时,此时主线程已经退出,exiting不会打印
time.sleep(0.2)
logging.debug('exiting')
def non_daemon():
logging.debug('starting')
logging.debug('exiting')
logging.basicConfig(
level=logging.DEBUG,
format='[%(levelname)s] (%(threadName)-10s) %(message)s'
)
def main():
# t1 = threading.Thread(name='线程1', target=daemon)
# t1.setDaemon(True)
t1 = threading.Thread(name='线程1', target=daemon, daemon=True)
t2 = threading.Thread(name='线程2', target=non_daemon)
t1.start()
t2.start()
# 等待守护线程完成工作需要调用join()方法,默认情况join会无限阻塞,可以传入浮点值,表示超时时间
t1.join(0.2)
t2.join(0.1)
if __name__ == '__main__':
main()
3.3 控制资源访问
目的:
Python线程中资源共享,如果不对资源加上互斥锁,有可能导致数据不准确。
import threading
import time
g_num = 0
def fun1(num):
global g_num
for i in range(num):
g_num += 1
print('线程1 g_num = %d' % g_num)
def fun2(num):
global g_num
for i in range(num):
g_num += 1
print('线程2 g_num = %d' % g_num)
def main():
t1 = threading.Thread(target=fun1, args=(1000000,))
t2 = threading.Thread(target=fun1, args=(1000000,))
t1.start()
t2.start()
if __name__ == '__main__':
main()
time.sleep(1)
print('主线程 g_num = %d' % g_num)
互斥锁
import threading
import time
g_num = 0
L = threading.Lock()
def fun1(num):
global g_num
L.acquire()
for i in range(num):
g_num += 1
L.release()
print('线程1 g_num = %d' % g_num)
def fun2(num):
global g_num
L.acquire()
for i in range(num):
g_num += 1
L.release()
print('线程2 g_num = %d' % g_num)
def main():
t1 = threading.Thread(target=fun1, args=(1000000,))
t2 = threading.Thread(target=fun1, args=(1000000,))
t1.start()
t2.start()
if __name__ == '__main__':
main()
time.sleep(1)
print('主线程 g_num = %d' % g_num)
互斥锁引发的另一个问题:死锁
死锁产生的原理:
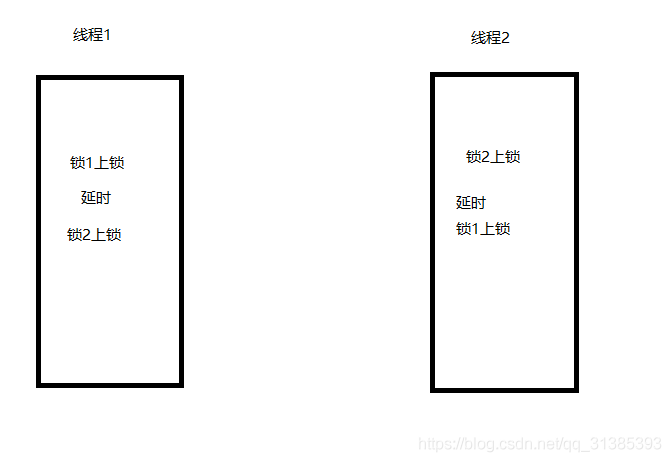
import threading
import time
g_num = 0
L1 = threading.Lock()
L2 = threading.Lock()
def fun1():
L1.acquire(timeout=5)
time.sleep(1)
L2.acquire()
print('产生死锁,并不会打印信息')
L2.release()
L1.release()
def fun2():
L2.acquire(timeout=5)
time.sleep(1)
L1.acquire()
print('产生死锁,并不会打印信息')
L1.release()
L2.release()
def main():
t1 = threading.Thread(target=fun1)
t2 = threading.Thread(target=fun2)
t1.start()
t2.start()
if __name__ == '__main__':
main()
time.sleep(1)
print('主线程 g_num = %d' % g_num)
如何避免产生死锁:
锁超时操作
import threading
import time
g_num = 0
L1 = threading.Lock()
L2 = threading.Lock()
def fun1():
L1.acquire()
time.sleep(1)
L2.acquire(timeout=5)
print('超时异常打印信息1')
L2.release()
L1.release()
def fun2():
L2.acquire()
time.sleep(1)
L1.acquire(timeout=5)
print('超时异常打印信息2')
L1.release()
L2.release()
def main():
t1 = threading.Thread(target=fun1)
t2 = threading.Thread(target=fun2)
t1.start()
t2.start()
if __name__ == '__main__':
main()
time.sleep(1)
print('主线程 g_num = %d' % g_num)
到此这篇关于Python多线程编程之threading模块详解的文章就介绍到这了,更多相关python threading模块内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python—sys模块之获取参数的操作
sys模块:全称system,指的是解释器. 常用操作,用于接收系统操作系统调用解释器传入的参数 1. sys.argv 获取脚本传递的所有参数,返回一个列表.列表中的所有元素均为脚本传递的参数. sys.argv[0] # 脚本传递的第一个参数,固定为脚本名称,可以通过次方式获得脚本名称 可以使用索引依次获得脚本传递的其他参数 2. sys.version 获取解释器的版本信息,返回一个字符串.根据python版本编写符合不同版本的程序 使程序可兼容 3.6.4 (default, Aug 1
-
Python使用random模块实现掷骰子游戏的示例代码
引入内容 根据人民邮电出版社出版的<Python程序设计现代设计方法>P102习题中的第7题--掷骰子游戏,进行代码编写. 题目要求 一盘游戏中,两人轮流掷骰子5次,并将每次掷出的点数累加,5局之后,累计点数较大者获胜,点数相同则为平局.根据此规则实现掷骰子游戏,并算出50盘之后的胜利者( 50盘中嬴得盘数最多的,即最终胜利者). 审题: 共有50盘游戏.一盘游戏有5局,每一局双方各掷骰子一次,5局结束以后统计分数,分数高的一方获胜.至此,一盘游戏结束.50盘游戏结束后,赢得盘数最多的一方为最
-
python process模块的使用简介
process模块 process模块是一个创建进程的模块,借助这个模块,就可以完成进程的创建. 参数介绍: Process(group=None, target=None, name=None, args=(), kwargs={}) 1 group--参数未使用,值始终为None 2 target--表示调用对象,即子进程要执行的任务 3 args--表示调用对象的位置参数元组,args=(1,2,'egon',) 4 kwargs--表示调用对象的字典,kwargs={'name':'
-
Python collections模块的使用技巧
一般来讲,python的collections是用于存储数据集合(比如列表list, 字典dict, 元组tuple和集合set)的容器.这些容器内置在Python中,可以直接使用.该collections模块提供了额外的,高性能的数据类型,可以增强你的代码,使事情变得更清洁,更容易. 让我们看一看关于集合模块最受欢迎的数据类型以及如何使用它们的教程! Counter Counter()是字典对象的子类.Counter()可接收一个可迭代遍历的对象(例如字符串.列表或元组)作为参数,并返回计数器
-

聊一聊python常用的编程模块
文件流的读写 读取保存数据为数组的txt文件 使用try进行异常发现,使用while检测文件末尾进行读取 file_to_read = raw_input("Enter file name of tests (empty string to end program):") try: infile = open(file_to_read, 'r') while file_to_read != " ": file_to_write = raw_input("E
-
Python爬虫基础之requestes模块
一.爬虫的流程 开始学习爬虫,我们必须了解爬虫的流程框架.在我看来爬虫的流程大概就是三步,即不论我们爬取的是什么数据,总是可以把爬虫的流程归纳总结为这三步: 1.指定 url,可以简单的理解为指定要爬取的网址 2.发送请求.requests 模块的请求一般为 get 和 post 3.将爬取的数据存储 二.requests模块的导入 因为 requests 模块属于外部库,所以需要我们自己导入库 导入的步骤: 1.右键Windows图标 2.点击"运行" 3.输入"cmd&q
-
Python基础之模块相关知识总结
一.什么是模块 容器 -> 数据的封装 函数 -> 语句的封装 类 -> 方法和属性的封装 模块 -> 模块就是程序,模块就是.py文件 导入hello模块,且使用hello命名空间的hi()函数 (1)hello.py模块的创建 注意模块与调用的程序要在同一个文件夹下面 import的时候直接写名字就行了,不用加上.py,eg:hello.py,hello就是模块名 (2)执行 命名空间 在Python中,每个模块都会维护一个独立的命名空间,我们应该将模块名加上,才能够正常使用模
-
Python协程asyncio模块的演变及高级用法
Python协程及asyncio基础知识 协程(coroutine)也叫微线程,是实现多任务的另一种方式,是比线程更小的执行单元,一般运行在单进程和单线程上.因为它自带CPU的上下文,它可以通过简单的事件循环切换任务,比进程和线程的切换效率更高,这是因为进程和线程的切换由操作系统进行. Python实现协程的主要借助于两个库:asyncio和gevent.由于asyncio已经成为python的标准库了无需pip安装即可使用,这意味着asyncio作为Python原生的协程实现方式会更加流行.本
-
python通配符之glob模块的使用详解
通配符是一些特殊符号,主要有星号(*)和问号(?),用来模糊搜索文件,"*"可以匹配任意个数个符号, "?"可以匹配单个字符. 当查找文件夹时,可以使用它来代替一个或多个真正字符:当不知道真正字符或者需要匹配符合一定条件的多个目标文件时,可以使用通配符代替一个或多个真正的字符. 英文 "globbing"意为统配,python在模块glob中定义了glob()函数,实现了对目录内容进行匹配的功能,glob.glob()函数接受通配模式作为输入,并
-
python文件目录操作之os模块
一.os函数目录 1 os.access(path, mode) 检验权限模式 2 os.chdir(path) 改变当前工作目录 3 os.chflags(path, flags) 设置路径的标记为数字标记. 4 os.chmod(path, mode) 更改权限 5 os.chown(path, uid, gid) 更改文件所有者 6 os.chroot(path) 改变当前进程的根目录 7 os.close(fd) 关闭文件描述符 fd 8 os.closerange(fd_low, fd