pytorch实现ResNet结构的实例代码
1.ResNet的创新
现在重新稍微系统的介绍一下ResNet网络结构。 ResNet结构首先通过一个卷积层然后有一个池化层,然后通过一系列的残差结构,最后再通过一个平均池化下采样操作,以及一个全连接层的得到了一个输出。ResNet网络可以达到很深的层数的原因就是不断的堆叠残差结构而来的。
1)亮点
网络中的亮点 :
- 超深的网络结构( 突破1000 层)
- 提出residual 模块
- 使用Batch Normalization 加速训练( 丢弃dropout)
但是,一般来说,并不是一直的加深神经网络的结构就会得到一个更好的结果,一般太深的网络会出现过拟合的现象严重,可能还没有一些浅层网络要好。
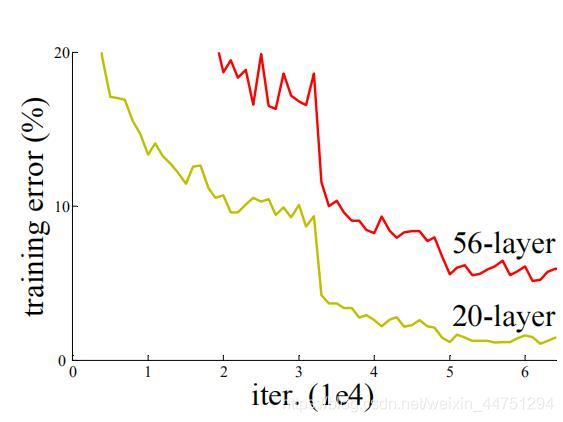
2)原因
其中有两个原因:
- 梯度消失或梯度爆炸
当层数过多的时候,假设每一层的误差梯度都是一个小于1的数值,当进行方向传播的过程中,每向前传播一层,都要乘以一个小于1的误差梯度,当网络越来越深时,所成的小于1的系数也就越来越多,此时梯度便越趋近于0,这样梯度便会越来越小。这便会造成梯度消失的现象。
而当所成的误差梯度是一个大于1的系数,而随着网络层数的加深,梯度便会越来越大,这便会造成梯度爆炸的现象。
- 退化问题(degradation problem)
当解决了梯度消失或者梯度爆炸的问题之后,其实网络的效果可能还是不尽如意,还可能有退化问题。为此,ResNet提出了残差结构来解决这个退化问题。 也正是因为有这个残差的结构,所以才可以搭建这么深的网络。
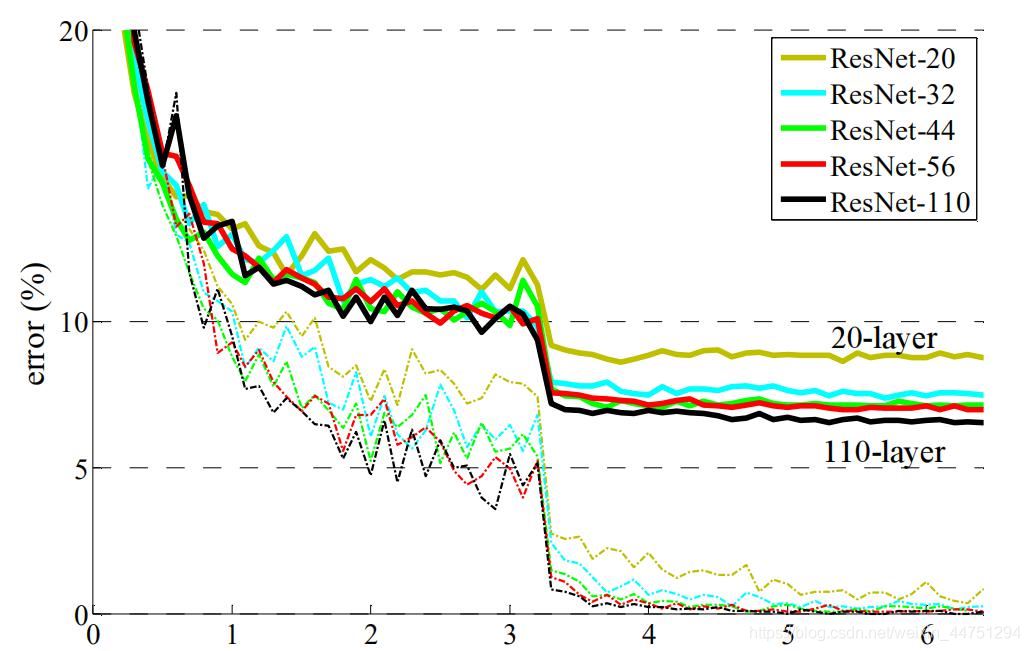
2.ResNet的结构
残差结构如图所示
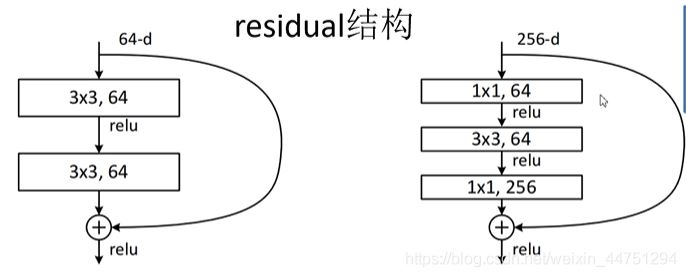
作图是针对ResNet-18/34层浅层网络的结构,右图是ResNet-50/101/152层深层网络的结构,其中注意:主分支与shortcut 的输出特征矩阵shape。
一下表格为网络的一些主要参数
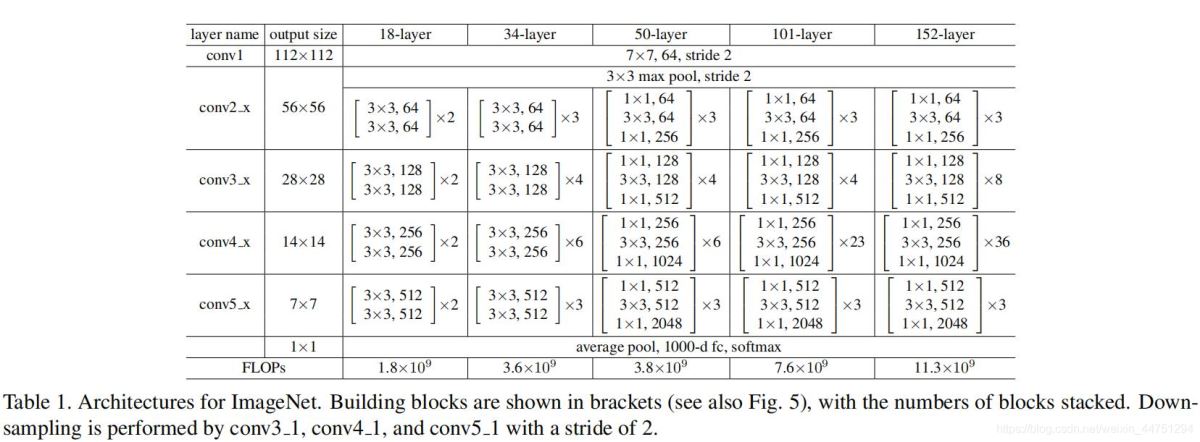
可以看见,不同层数的网络结构其实框架是类似的,不同的至少堆叠的残差结构的数量。
1)浅层的残差结构

需要注意,有些残差结构的ShortCut是实线,而有的是虚线,这两者是不同的。对于左图来说,ShortCut是实线,这表明输入与输出的shape是一样的,所以可以直接的进行相加。而对于右图来说,其输入的shape与输出的shape是不一样的,这时候需要调整步长stribe与kernel size来使得两条路(主分支与捷径分支)所处理好的shape是一模一样的。
2)深层的残差结构

同样的,需要注意,主分支与shortcut 的输出特征矩阵shape必须相同,同样的通过步长来调整。
但是注意原论文中:
右侧虚线残差结构的主分支上、第一个1x1卷积层的步距是2,第二个3x3卷积层的步距是1.
而在pytorch官方实现的过程中是第一个1x1卷积层的步距是1,第二个3x3卷积层步距是2,这样能够在ImageNet的top1上提升大概0.5%的准确率。
所以在conv3_x,conv4_x,conv5_x中所对应的残差结构的第一层,都是指虚线的残差结构,其他的残差结构是实线的残差结构。
3)总结
对于每个大模块中的第一个残差结构,需要通过虚线分支来调整残差结构的输入与输出是同一个shape。此时使用了下采样的操作函数。
对于每个大模块中的其他剩余的残差结构,只需要通过实线分支来调整残差网络结构,因为其输出和输入本身就是同一个shape的。
对于第一个大模块的第一个残差结构,其第二个3x3的卷积中,步长是1的,而其他的三个大模块的步长均为2.
在每一个大模块的维度变换中,主要是第一个残差结构使得shape减半,而模块中其他的残差结构都是没有改变shape的。也真因为没有改变shape,所以这些残差结构才可以直接的通过实线进行相加。
3.Batch Normalization
Batch Normalization的目的是使我们的一批(Batch)特征矩阵feature map满足均值为0,方差为1的分布规律。

其中:
μ,σ_2在正向传播过程中统计得到
γ,β在反向传播过程中训练得到
Batch Normalization是google团队在2015年论文《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》提出的。通过该方法能够加速网络的收敛并提升准确率。
具体的相关原理见:Batch Normalization详解以及pytorch实验
4.参考代码
import torch
import torch.nn as nn
# 分类数目
num_class = 5
# 各层数目
resnet18_params = [2, 2, 2, 2]
resnet34_params = [3, 4, 6, 3]
resnet50_params = [3, 4, 6, 3]
resnet101_params = [3, 4, 23, 3]
resnet152_params = [3, 8, 36, 3]
# 定义Conv1层
def Conv1(in_planes, places, stride=2):
return nn.Sequential(
nn.Conv2d(in_channels=in_planes,out_channels=places,kernel_size=7,stride=stride,padding=3, bias=False),
nn.BatchNorm2d(places),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# 浅层的残差结构
class BasicBlock(nn.Module):
def __init__(self,in_places,places, stride=1,downsampling=False, expansion = 1):
super(BasicBlock,self).__init__()
self.expansion = expansion
self.downsampling = downsampling
# torch.Size([1, 64, 56, 56]), stride = 1
# torch.Size([1, 128, 28, 28]), stride = 2
# torch.Size([1, 256, 14, 14]), stride = 2
# torch.Size([1, 512, 7, 7]), stride = 2
self.basicblock = nn.Sequential(
nn.Conv2d(in_channels=in_places, out_channels=places, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(places),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=places, out_channels=places, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(places * self.expansion),
)
# torch.Size([1, 64, 56, 56])
# torch.Size([1, 128, 28, 28])
# torch.Size([1, 256, 14, 14])
# torch.Size([1, 512, 7, 7])
# 每个大模块的第一个残差结构需要改变步长
if self.downsampling:
self.downsample = nn.Sequential(
nn.Conv2d(in_channels=in_places, out_channels=places*self.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(places*self.expansion)
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
# 实线分支
residual = x
out = self.basicblock(x)
# 虚线分支
if self.downsampling:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
# 深层的残差结构
class Bottleneck(nn.Module):
# 注意:默认 downsampling=False
def __init__(self,in_places,places, stride=1,downsampling=False, expansion = 4):
super(Bottleneck,self).__init__()
self.expansion = expansion
self.downsampling = downsampling
self.bottleneck = nn.Sequential(
# torch.Size([1, 64, 56, 56]),stride=1
# torch.Size([1, 128, 56, 56]),stride=1
# torch.Size([1, 256, 28, 28]), stride=1
# torch.Size([1, 512, 14, 14]), stride=1
nn.Conv2d(in_channels=in_places,out_channels=places,kernel_size=1,stride=1, bias=False),
nn.BatchNorm2d(places),
nn.ReLU(inplace=True),
# torch.Size([1, 64, 56, 56]),stride=1
# torch.Size([1, 128, 28, 28]), stride=2
# torch.Size([1, 256, 14, 14]), stride=2
# torch.Size([1, 512, 7, 7]), stride=2
nn.Conv2d(in_channels=places, out_channels=places, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(places),
nn.ReLU(inplace=True),
# torch.Size([1, 256, 56, 56]),stride=1
# torch.Size([1, 512, 28, 28]), stride=1
# torch.Size([1, 1024, 14, 14]), stride=1
# torch.Size([1, 2048, 7, 7]), stride=1
nn.Conv2d(in_channels=places, out_channels=places * self.expansion, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(places * self.expansion),
)
# torch.Size([1, 256, 56, 56])
# torch.Size([1, 512, 28, 28])
# torch.Size([1, 1024, 14, 14])
# torch.Size([1, 2048, 7, 7])
if self.downsampling:
self.downsample = nn.Sequential(
nn.Conv2d(in_channels=in_places, out_channels=places*self.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(places*self.expansion)
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
# 实线分支
residual = x
out = self.bottleneck(x)
# 虚线分支
if self.downsampling:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self,blocks, blockkinds, num_classes=num_class):
super(ResNet,self).__init__()
self.blockkinds = blockkinds
self.conv1 = Conv1(in_planes = 3, places= 64)
# 对应浅层网络结构
if self.blockkinds == BasicBlock:
self.expansion = 1
# 64 -> 64
self.layer1 = self.make_layer(in_places=64, places=64, block=blocks[0], stride=1)
# 64 -> 128
self.layer2 = self.make_layer(in_places=64, places=128, block=blocks[1], stride=2)
# 128 -> 256
self.layer3 = self.make_layer(in_places=128, places=256, block=blocks[2], stride=2)
# 256 -> 512
self.layer4 = self.make_layer(in_places=256, places=512, block=blocks[3], stride=2)
self.fc = nn.Linear(512, num_classes)
# 对应深层网络结构
if self.blockkinds == Bottleneck:
self.expansion = 4
# 64 -> 64
self.layer1 = self.make_layer(in_places = 64, places= 64, block=blocks[0], stride=1)
# 256 -> 128
self.layer2 = self.make_layer(in_places = 256,places=128, block=blocks[1], stride=2)
# 512 -> 256
self.layer3 = self.make_layer(in_places=512,places=256, block=blocks[2], stride=2)
# 1024 -> 512
self.layer4 = self.make_layer(in_places=1024,places=512, block=blocks[3], stride=2)
self.fc = nn.Linear(2048, num_classes)
self.avgpool = nn.AvgPool2d(7, stride=1)
# 初始化网络结构
for m in self.modules():
if isinstance(m, nn.Conv2d):
# 采用了何凯明的初始化方法
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def make_layer(self, in_places, places, block, stride):
layers = []
# torch.Size([1, 64, 56, 56]) -> torch.Size([1, 256, 56, 56]), stride=1 故w,h不变
# torch.Size([1, 256, 56, 56]) -> torch.Size([1, 512, 28, 28]), stride=2 故w,h变
# torch.Size([1, 512, 28, 28]) -> torch.Size([1, 1024, 14, 14]),stride=2 故w,h变
# torch.Size([1, 1024, 14, 14]) -> torch.Size([1, 2048, 7, 7]), stride=2 故w,h变
# 此步需要通过虚线分支,downsampling=True
layers.append(self.blockkinds(in_places, places, stride, downsampling =True))
# torch.Size([1, 256, 56, 56]) -> torch.Size([1, 256, 56, 56])
# torch.Size([1, 512, 28, 28]) -> torch.Size([1, 512, 28, 28])
# torch.Size([1, 1024, 14, 14]) -> torch.Size([1, 1024, 14, 14])
# torch.Size([1, 2048, 7, 7]) -> torch.Size([1, 2048, 7, 7])
# print("places*self.expansion:", places*self.expansion)
# print("block:", block)
# 此步需要通过实线分支,downsampling=False, 每个大模块的第一个残差结构需要改变步长
for i in range(1, block):
layers.append(self.blockkinds(places*self.expansion, places))
return nn.Sequential(*layers)
def forward(self, x):
# conv1层
x = self.conv1(x) # torch.Size([1, 64, 56, 56])
# conv2_x层
x = self.layer1(x) # torch.Size([1, 256, 56, 56])
# conv3_x层
x = self.layer2(x) # torch.Size([1, 512, 28, 28])
# conv4_x层
x = self.layer3(x) # torch.Size([1, 1024, 14, 14])
# conv5_x层
x = self.layer4(x) # torch.Size([1, 2048, 7, 7])
x = self.avgpool(x) # torch.Size([1, 2048, 1, 1]) / torch.Size([1, 512])
x = x.view(x.size(0), -1) # torch.Size([1, 2048]) / torch.Size([1, 512])
x = self.fc(x) # torch.Size([1, 5])
return x
def ResNet18():
return ResNet(resnet18_params, BasicBlock)
def ResNet34():
return ResNet(resnet34_params, BasicBlock)
def ResNet50():
return ResNet(resnet50_params, Bottleneck)
def ResNet101():
return ResNet(resnet101_params, Bottleneck)
def ResNet152():
return ResNet(resnet152_params, Bottleneck)
if __name__=='__main__':
# model = torchvision.models.resnet50()
# 模型测试
# model = ResNet18()
# model = ResNet34()
# model = ResNet50()
# model = ResNet101()
model = ResNet152()
# print(model)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
以上就是pytorch实现ResNet结构的实例代码的详细内容,更多关于pytorch ResNet结构的资料请关注我们其它相关文章!
相关推荐
-
PyTorch实现ResNet50、ResNet101和ResNet152示例
PyTorch: https://github.com/shanglianlm0525/PyTorch-Networks import torch import torch.nn as nn import torchvision import numpy as np print("PyTorch Version: ",torch.__version__) print("Torchvision Version: ",torchvision.__version__) _
-
pytorch实现用Resnet提取特征并保存为txt文件的方法
接触pytorch一天,发现pytorch上手的确比TensorFlow更快.可以更方便地实现用预训练的网络提特征. 以下是提取一张jpg图像的特征的程序: # -*- coding: utf-8 -*- import os.path import torch import torch.nn as nn from torchvision import models, transforms from torch.autograd import Variable import numpy as np
-
Pytorch修改ResNet模型全连接层进行直接训练实例
之前在用预训练的ResNet的模型进行迁移训练时,是固定除最后一层的前面层权重,然后把全连接层输出改为自己需要的数目,进行最后一层的训练,那么现在假如想要只是把 最后一层的输出改一下,不需要加载前面层的权重,方法如下: model = torchvision.models.resnet18(pretrained=False) num_fc_ftr = model.fc.in_features model.fc = torch.nn.Linear(num_fc_ftr, 224) model =
-

pytorch实现ResNet结构的实例代码
1.ResNet的创新 现在重新稍微系统的介绍一下ResNet网络结构. ResNet结构首先通过一个卷积层然后有一个池化层,然后通过一系列的残差结构,最后再通过一个平均池化下采样操作,以及一个全连接层的得到了一个输出.ResNet网络可以达到很深的层数的原因就是不断的堆叠残差结构而来的. 1)亮点 网络中的亮点 : 超深的网络结构( 突破1000 层) 提出residual 模块 使用Batch Normalization 加速训练( 丢弃dropout) 但是,一般来说,并不是一直的加深神经
-
Node.js 文件夹目录结构创建实例代码
第一次接触NodeJS的文件系统就被它的异步的响应给搞晕了,后来发现NodeJS判断文件夹是否存在和创建文件夹是还有同步方法的,但是还是想尝试使用异步的方法去实现. 使用的方法: fs.exists(path, callback); fs.mkdir(path, [mode], callback); 实现文件夹目录结构的创建代码实现如下: //创建文件夹 function mkdir(pos, dirArray,_callback){ var len = dirArray.length; con
-
Angular中实现树形结构视图实例代码
近两年当中使用Angular开发过很多项目,其中也涉及到一些树形结构视图的显示,最近的在项目中封装了大量的组件,一些组件也有树形结构的展示,所以写出来总结一下. 相信大家都知道,树结构最典型的例子就是目录结构了吧,一个目录可以包含很多子目录,子目录又可以包含若干个子孙目录,那咱们今天就以目录结构为例来说明一下Angular中树结构的实现. 首先,我们希望封装一个组件,用于显示整个目录的树形机构,代码如下: <!DOCTYPE html> <html ng-app="treeDe
-
基于Pytorch实现的声音分类实例代码
目录 前言 环境准备 安装libsora 安装PyAudio 安装pydub 训练分类模型 生成数据列表 训练 预测 其他 总结 前言 本章我们来介绍如何使用Pytorch训练一个区分不同音频的分类模型,例如你有这样一个需求,需要根据不同的鸟叫声识别是什么种类的鸟,这时你就可以使用这个方法来实现你的需求了. 源码地址:https://github.com/yeyupiaoling/AudioClassification-Pytorch 环境准备 主要介绍libsora,PyAudio,pydub
-
Java创建树形结构算法实例代码
在JavaWeb的相关开发中经常会涉及到多级菜单的展示,为了方便菜单的管理需要使用数据库进行支持,本例采用相关算法讲数据库中的条形记录进行相关组装和排序讲菜单组装成树形结构. 首先是需要的JavaBean import java.io.Serializable; import java.util.ArrayList; import java.util.Collections; import java.util.Comparator; import java.util.Date; import j
-
pytorch常用函数定义及resnet模型修改实例
目录 模型定义常用函数 利用nn.Parameter()设计新的层 nn.Sequential nn.ModuleList() nn.ModuleDict() nn.Flatten 模型修改案例 修改模型层 添加外部输入 模型定义常用函数 利用nn.Parameter()设计新的层 import torch from torch import nn class MyLinear(nn.Module): def __init__(self, in_features, out_features):
-
spring security数据库表结构实例代码
PD建模图 建模语句 alter table SYS_AUTHORITIES_RESOURCES drop constraint FK_SYS_AUTH_REFERENCE_SYS_AUTH; alter table SYS_AUTHORITIES_RESOURCES drop constraint FK_SYS_AUTH_REFERENCE_SYS_RESO; alter table SYS_RESOURCES drop constraint FK_SYS_RESO_REFERENCE_SYS
-
vue实现树形结构样式和功能的实例代码
一.主要运用element封装的控件并封装成组件运用,如图所示 代码如图所示: 下面是子组件的代码: <template> <ul class="l_tree"> <li class="l_tree_branch" v-for="item in model" :key="item.id"> <div class="l_tree_click"> <butt
-
golang结构体与json格式串实例代码
具体代码如下所示: package main import ( "encoding/json" "fmt" ) type IT struct { //一定要注意这里的成员变量的名字首字母必须是大写 Company string Subjects []string Isok bool Price float64 } func main() { s := IT{"zyg", []string{"go", "python&
-
c++ qsort 与sort 对结构体排序实例代码
#include<bits/stdc++.h> using namespace std; typedef struct { string book; int num; }Book; //qsort的比较函数 int cmp(const void * a, const void * b) { return (*(Book*)a).num > (*(Book*)b).num ? 1 : 0; } //sort的比较函数 bool cmp_(Book a, Book b) { return a