python 计算t分布的双侧置信区间
如下所示:
interval=stats.t.interval(a,b,mean,std)
t分布的置信区 间
a:置信水平
b:检验量的自由度
mean:样本均值
std:样本标准差
from scipy import stats import numpy as np x=[10.1,10,9.8,10.5,9.7,10.1,9.9,10.2,10.3,9.9] x1=np.array(x) mean=x1.mean() std=x1.std() interval=stats.t.interval(0.95,len(x)-1,mean,std)
interval Out[9]: (9.531674678392644, 10.568325321607357)
补充:用Python学分析 - t分布
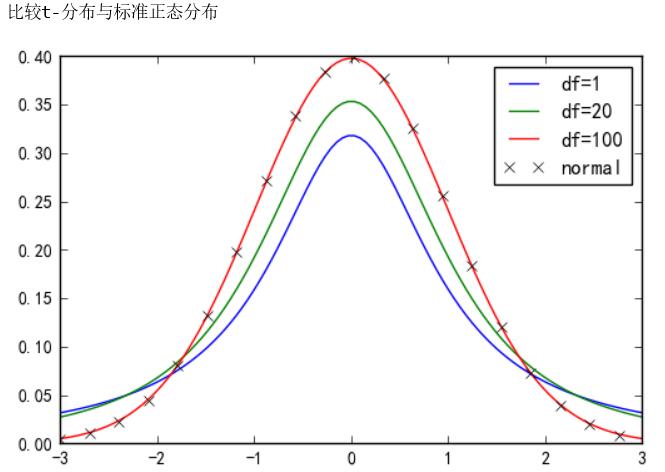
1. t分布形状类似于标准正态分布
2. t分布是对称分布,较正态分布离散度强,密度曲线较标准正态分布密度曲线更扁平
3. 对于大型样本,t-值与z-值之间的差别很小
作用
- t分布纠正了未知的真实标准差的不确定性
- t分布明确解释了估计总体方差时样本容量的影响,是适合任何样本容量都可以使用的合适分布
应用
- 根据小样本来估计呈正态分布且方差未知的总体的均值
- 对于任何一种样本容量,真正的平均值抽样分布是t分布,因此,当存在疑问时,应使用t分布
样本容量对分布的影响
- 当样本容量在 30-35之间时,t分布与标准正态分布难以区分
- 当样本容量达到120时,t分布与标准正态分布实际上完全相同了
自由度df对分布的影响
- 样本方差使用一个估计的参数(平均值),所以计算置信区间时使用的t分布的自由度为 n - 1
- 由于引入额外的参数(自由度df),t分布比标准正态分布的方差更大(置信区间更宽)
- 与标准正态分布曲线相比,自由度df越小,t分布曲线愈平坦,曲线中间愈低,曲线双侧尾部翘得愈高
- 自由度df愈大,t分布曲线愈接近正态分布曲线,当自由度df= ∞ 时,t分布曲线为标准正态分布曲线
图表显示t分布
代码:
# 不同自由度的学生t分布与标准正态分布
import numpy as np
from scipy.stats import norm
from scipy.stats import t
import matplotlib.pyplot as plt
print('比较t-分布与标准正态分布')
x = np.linspace( -3, 3, 100)
plt.plot(x, t.pdf(x,1), label='df=1')
plt.plot(x, t.pdf(x,2), label='df=20')
plt.plot(x, t.pdf(x,100), label = 'df=100')
plt.plot( x[::5], norm.pdf(x[::5]),'kx', label='normal')
plt.legend()
plt.show()
运行结果:
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
Python求解正态分布置信区间教程
正态分布和置信区间 正态分布(Normal Distribution)又叫高斯分布,是一种非常重要的概率分布.其概率密度函数的数学表达如下: 置信区间是对该区间能包含未知参数的可置信的程度的描述. 使用SciPy求解置信区间 import numpy as np import matplotlib.pyplot as plt from scipy import stats N = 10000 x = np.random.normal(0, 1, N) # ddof取值为1是因为在统计学中样本的标
-
Python求区间正整数内所有素数之和的方法实例
前言 Python的学习记录与分享--PTA程序设计类教学平台.如果你也正在学习关于此类的题目可以仔细阅读这篇文章,了解一下循环结构.素数的基本语法知识. 题目: 7-5就区间正整数内所有素数之和 (20分) [描述]求m-n以内所有素数之和并输出.素数指从大于1,且仅能被1和自己整除的整数.
-
python如何遍历指定路径下所有文件(按按照时间区间检索)
需求 要求 查找文件夹里某个日期区间内的word文档,全部word的名称和路径列出来,比如 7月5号到7月31号 D盘下的所有word文档. 修改文件类型 修改文件路径 检索文件修改时间区间 #conding=utf8 import os import time g = os.walk(r"F:\学习资料\week_home") def judge_time_file(path, file, update_time): if not file.endswith(('.doc','.do
-
Python 日期区间处理 (本周本月上周上月...)
工具类 class CalendarUtils: """ 日期工具类 """ @staticmethod def delta_day(delta=0): """ :param delta: 偏移量 :return: 0今天, 1昨天, 2前天, -1明天 ... """ return (datetime.now() + timedelta(days=delta)).strftime('%
-
Python 数值区间处理_对interval 库的快速入门详解
使用 Python 进行数据处理的时候,常常会遇到判断一个数是否在一个区间内的操作.我们可以使用 if else 进行判断,但是,既然使用了 Python,那我们当然是想找一下有没有现成的轮子可以用.事实上,我们可以是用 interval 这一个库来完成我们需要的操作. 区间判断基础 最基础的区间判断操作就是先创建一个区间几个,然后使用 in 来判断一个数是否存在于区间之内.代码如下: from interval import Interval zoom_2_5 = Interval(2, 5)
-
Python 判断时间是否在时间区间内的实例
判断时间是否在时间区间内 大家都知道 3<4<5这种连等式判断在python中是可行的 >>> 3<4<5 True 那么给定时间是否在时间区间内,也可以用连等式来判断 # 给定两个时间来比较下 >>> from datetime import datetime >>> a=datetime.now() >>> b=datetime.now() >>> a datetime.datetime(
-

python 计算t分布的双侧置信区间
如下所示: interval=stats.t.interval(a,b,mean,std) t分布的置信区 间 a:置信水平 b:检验量的自由度 mean:样本均值 std:样本标准差 from scipy import stats import numpy as np x=[10.1,10,9.8,10.5,9.7,10.1,9.9,10.2,10.3,9.9] x1=np.array(x) mean=x1.mean() std=x1.std() interval=stats.t.interv
-
python 计算概率密度、累计分布、逆函数的例子
计算概率分布的相关参数时,一般使用 scipy 包,常用的函数包括以下几个: pdf:连续随机分布的概率密度函数 pmf:离散随机分布的概率密度函数 cdf:累计分布函数 百分位函数(累计分布函数的逆函数) 生存函数的逆函数(1 - cdf 的逆函数) 函数里面不仅能跟一个数据,还能跟一个数组.下面用正态分布举例说明: >>> import scipy.stats as st >>> st.norm.cdf(0) # 标准正态分布在 0 处的累计分布概率值 0.5 &g
-
Python计算字符宽度的方法
本文实例讲述了Python计算字符宽度的方法.分享给大家供大家参考,具体如下: 最近在用python写一个CLI小程序,其中涉及到计算字符宽度,目标是以友好的方式将一个长字符串截取为等宽的片段. 对于unicode字符,python的len函数可以准确的计算其中所包含的字符个数,但是个数并不代表宽度,如: >>>len(u'你好a') 3 因此无法简单的使用这种方式来计算宽度. GBK decode 首先我想到GBK编码,00–7F范围内的字符是一字节编码,其余是双字节编码,正好与字符的
-
python实现beta分布概率密度函数的方法
如下所示: beta分布的最大特点是其多样性, 从下图可以看出, beta分布具有各种形态, 有U形, 类似正态分布的形状, 类似uniform分布的形状等, 正式这一特质使beta分布在共轭先验的计算中起到重要作用: import matplotlib.pyplot as plt import numpy as np from scipy import stats from matplotlib import style style.use('ggplot') params = [0.5, 1
-
python计算无向图节点度的实例代码
废话不多说了,直接上代码吧: #Copyright (c)2017, 东北大学软件学院学生 # All rightsreserved #文件名称:a.py # 作 者:孔云 #问题描述:统计图中的每个节点的度,并生成度序列 #问题分析:利用networkx.代码如下: import networkx as nx G=nx.random_graphs.barabasi_albert_graph(1000,3)#生成n=1000,m=3的无标度的图 print ("某个节点的度:",G.d
-
Python计算不规则图形面积算法实现解析
这篇文章主要介绍了Python计算不规则图形面积算法实现解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 介绍:大三上做一个医学影像识别的项目,医生在原图上用红笔标记病灶点,通过记录红色的坐标位置可以得到病灶点的外接矩形,但是后续会涉及到红圈内的面积在外接矩形下的占比问题,有些外接矩形内有多个红色标记,在使用网上的opencv的fillPoly填充效果非常不理想,还有类似python计算任意多边形方法也不理想的情况下,自己探索出的一种效果还不
-
利用Python计算KS的实例详解
在金融领域中,我们的y值和预测得到的违约概率刚好是两个分布未知的两个分布.好的信用风控模型一般从准确性.稳定性和可解释性来评估模型. 一般来说.好人样本的分布同坏人样本的分布应该是有很大不同的,KS正好是有效性指标中的区分能力指标:KS用于模型风险区分能力进行评估,KS指标衡量的是好坏样本累计分布之间的差值. 好坏样本累计差异越大,KS指标越大,那么模型的风险区分能力越强. 1.crosstab实现,计算ks的核心就是好坏人的累积概率分布,我们采用pandas.crosstab函数来计算累积概率
-
在python中求分布函数相关的包实例
为了了解(正态)分布的方法和属性,我们首先引入norm >>>from scipy.stats import norm >>>rv = norm() >>>dir(rv) # reformatted ['__class__', '__delattr__', '__dict__', '__doc__', '__getattribute__', '__hash__', '__init__', '__module__', '__new__', '__redu
-
使用python计算方差方式——pandas.series.std()
目录 如何计算方差 Python计算方差.标准差 方差.标准差 1.方差 2.标准差 如何计算方差 简单展示一下pandas里怎么计算方差: 官方文档: def def_std(df): for ix,row in df.iterrows(): std = row.std() df.loc[ix,"std"] = std return df Python计算方差.标准差 方差.标准差 1.离散程度的测度值之一 2.最常用的测度值 3.反应了数据的分布 4.反应了
-
python 计算文件的md5值实例
较小文件处理方法: import hashlib import os def get_md5_01(file_path): md5 = None if os.path.isfile(file_path): f = open(file_path,'rb') md5_obj = hashlib.md5() md5_obj.update(f.read()) hash_code = md5_obj.hexdigest() f.close() md5 = str(hash_code).lower() re