Springboot整合kafka的示例代码
目录
- 1. 整合kafka
- 2. 消息发送
- 2.1 发送类型
- 2.2 序列化
- 2.3 分区策略
- 3. 消息消费
- 3.1 消息组别
- 3.2 位移提交
1. 整合kafka
1、引入依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
2、设置yml文件
spring:
application:
name: demo
kafka:
bootstrap-servers: 52.82.98.209:10903,52.82.98.209:10904
producer: # producer 生产者
retries: 0 # 重试次数
acks: 1 # 应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
batch-size: 16384 # 批量大小
buffer-memory: 33554432 # 生产端缓冲区大小
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# value-serializer: com.itheima.demo.config.MySerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer: # consumer消费者
group-id: javagroup # 默认的消费组ID
enable-auto-commit: true # 是否自动提交offset
auto-commit-interval: 100 # 提交offset延时(接收到消息后多久提交offset)
# earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
# latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
# none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
auto-offset-reset: latest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# value-deserializer: com.itheima.demo.config.MyDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
3、启动项目

2. 消息发送
2.1 发送类型
KafkaTemplate调用send时默认采用异步发送,如果需要同步获取发送结果,调用get方法
异步发送生产者:
@RestController
public class KafkaProducer {
@Resource
private KafkaTemplate<String, Object> kafkaTemplate;
@GetMapping("/kafka/test/{msg}")
public void sendMessage(@PathVariable("msg") String msg) {
Message message = new Message();
message.setMessage(msg);
kafkaTemplate.send("test", JSON.toJSONString(message));
}
}
同步发送生产者:
//测试同步发送与监听
@RestController
public class AsyncProducer {
private final static Logger logger = LoggerFactory.getLogger(AsyncProducer.class);
@Resource
private KafkaTemplate<String, Object> kafkaTemplate;
//同步发送
@GetMapping("/kafka/sync/{msg}")
public void sync(@PathVariable("msg") String msg) throws Exception {
Message message = new Message();
message.setMessage(msg);
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send("test", JSON.toJSONString(message));
//注意,可以设置等待时间,超出后,不再等候结果
SendResult<String, Object> result = future.get(3,TimeUnit.SECONDS);
logger.info("send result:{}",result.getProducerRecord().value());
}
}
消费者:
@Component
public class KafkaConsumer {
private final Logger logger = LoggerFactory.getLogger(KafkaConsumer.class);
//不指定group,默认取yml里配置的
@KafkaListener(topics = {"test"})
public void onMessage1(ConsumerRecord<?, ?> consumerRecord) {
Optional<?> optional = Optional.ofNullable(consumerRecord.value());
if (optional.isPresent()) {
Object msg = optional.get();
logger.info("message:{}", msg);
}
}
}
那么我们怎么看出来同步发送和异步发送的区别呢?
①首先在服务器上,将kafka暂停服务。
②在swagger发送消息
调同步发送:请求被阻断,一直等待,超时后返回错误

而调异步发送的(默认发送接口),请求立刻返回。

那么,异步发送的消息怎么确认发送情况呢?
我们使用注册监听
即新建一个类:KafkaListener.java
@Configuration
public class KafkaListener {
private final static Logger logger = LoggerFactory.getLogger(KafkaListener.class);
@Autowired
KafkaTemplate kafkaTemplate;
//配置监听
@PostConstruct
private void listener() {
kafkaTemplate.setProducerListener(new ProducerListener<String, Object>() {
@Override
public void onSuccess(ProducerRecord<String, Object> producerRecord, RecordMetadata recordMetadata) {
logger.info("ok,message={}", producerRecord.value());
}
public void onError(ProducerRecord<String, Object> producerRecord, Exception exception) {
logger.error("error!message={}", producerRecord.value());
});
}
}
查看控制台,等待一段时间后,异步发送失败的消息会被回调给注册过的listener

如果是正常发送异步消息,则会获得该消息。可以看到,在内部类 KafkaListener$1 中,即注册的Listener的消息。

2.2 序列化
消费者使用:KafkaConsumer.java
@Component
public class KafkaConsumer {
private final Logger logger = LoggerFactory.getLogger(KafkaConsumer.class);
//不指定group,默认取yml里配置的
@KafkaListener(topics = {"test"})
public void onMessage1(ConsumerRecord<?, ?> consumerRecord) {
Optional<?> optional = Optional.ofNullable(consumerRecord.value());
if (optional.isPresent()) {
Object msg = optional.get();
logger.info("message:{}", msg);
}
}
}
1)序列化详解
- 前面用到的是Kafka自带的字符串序列化器(
org.apache.kafka.common.serialization.StringSerializer) - 除此之外还有:ByteArray、ByteBuffer、Bytes、Double、Integer、Long 等
- 这些序列化器都实现了接口(
org.apache.kafka.common.serialization.Serializer) - 基本上,可以满足绝大多数场景
2)自定义序列化
自己实现,实现对应的接口即可,有以下方法:
public interface Serializer<T> extends Closeable {
default void configure(Map<String, ?> configs, Boolean isKey) {
}
//理论上,只实现这个即可正常运行
byte[] serialize(String var1, T var2);
//默认调上面的方法
default byte[] serialize(String topic, Headers headers, T data) {
return this.serialize(topic, data);
}
default void close() {
}
}
我们来自己实现一个序列化器:MySerializer.java
public class MySerializer implements Serializer {
@Override
public byte[] serialize(String s, Object o) {
String json = JSON.toJSONString(o);
return json.getBytes();
}
}
3)解码MyDeserializer.java,实现方式与编码器几乎一样.
public class MyDeserializer implements Deserializer {
private final static Logger logger = LoggerFactory.getLogger(MyDeserializer.class);
@Override
public Object deserialize(String s, byte[] bytes) {
try {
String json = new String(bytes,"utf-8");
return JSON.parse(json);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return null;
}
}
4)在yaml中配置自己的编码器、解码器

再次收发,消息正常

2.3 分区策略
分区策略决定了消息根据key投放到哪个分区,也是顺序消费保障的基石。
- 给定了分区号,直接将数据发送到指定的分区里面去
- 没有给定分区号,给定数据的key值,通过key取上hashCode进行分区
- 既没有给定分区号,也没有给定key值,直接轮循进行分区(默认)
- 自定义分区,你想怎么做就怎么做
1)验证默认分区规则
发送者代码参考:PartitionProducer.java
//测试分区发送
@RestController
public class PartitionProducer {
@Resource
private KafkaTemplate<String, Object> kafkaTemplate;
// 指定分区发送
// 不管你key是什么,到同一个分区
@GetMapping("/kafka/partitionSend/{key}")
public void setPartition(@PathVariable("key") String key) {
kafkaTemplate.send("test", 0, key, "key=" + key + ",msg=指定0号分区");
}
// 指定key发送,不指定分区
// 根据key做hash,相同的key到同一个分区
@GetMapping("/kafka/keysend/{key}")
public void setKey(@PathVariable("key") String key) {
kafkaTemplate.send("test", key, "key=" + key + ",msg=不指定分区");
}
消费者代码使用:PartitionConsumer.java
@Component
public class PartitionConsumer {
private final Logger logger = LoggerFactory.getLogger(PartitionConsumer.class);
//分区消费
@KafkaListener(topics = {"test"},topicPattern = "0")
public void onMessage(ConsumerRecord<?, ?> consumerRecord) {
Optional<?> optional = Optional.ofNullable(consumerRecord.value());
if (optional.isPresent()) {
Object msg = optional.get();
logger.info("partition=0,message:[{}]", msg);
}
}
@KafkaListener(topics = {"test"},topicPattern = "1")
public void onMessage1(ConsumerRecord<?, ?> consumerRecord) {
Optional<?> optional = Optional.ofNullable(consumerRecord.value());
if (optional.isPresent()) {
Object msg = optional.get();
logger.info("partition=1,message:[{}]", msg);
}
}
}
通过swagger访问setKey(也就是只给了key的方法):

可以看到key相同的被hash到了同一个分区
再访问setPartition来设置分区号0来发送:

可以看到无论key是什么,都是分区0来消费
2)自定义分区
参考代码:MyPartitioner.java , MyPartitionTemplate.java。
发送使用:MyPartitionProducer.java。
public class MyPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 定义自己的分区策略
// 如果key以0开头,发到0号分区
// 其他都扔到1号分区
String keyStr = key+"";
if (keyStr.startsWith("0")){
return 0;
}else {
return 1;
}
}
public void close() {
public void configure(Map<String, ?> map) {
}
@Configuration
public class MyPartitionTemplate {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
KafkaTemplate kafkaTemplate;
@PostConstruct
public void setKafkaTemplate() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
//注意分区器在这里!!!
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyPartitioner.class);
this.kafkaTemplate = new KafkaTemplate<String, String>(new DefaultKafkaProducerFactory<>(props));
}
public KafkaTemplate getKafkaTemplate(){
return kafkaTemplate;
}
//测试自定义分区发送
@RestController
public class MyPartitionProducer {
@Autowired
MyPartitionTemplate template;
// 使用0开头和其他任意字母开头的key发送消息
// 看控制台的输出,在哪个分区里?
@GetMapping("/kafka/myPartitionSend/{key}")
public void setPartition(@PathVariable("key") String key) {
template.getKafkaTemplate().send("test", key,"key="+key+",msg=自定义分区策略");
}
}
使用swagger,发送0开头和非0开头两种key

3. 消息消费
3.1 消息组别
发送者使用:KafkaProducer.java
@RestController
public class KafkaProducer {
@Resource
private KafkaTemplate<String, Object> kafkaTemplate;
@GetMapping("/kafka/test/{msg}")
public void sendMessage(@PathVariable("msg") String msg) {
Message message = new Message();
message.setMessage(msg);
kafkaTemplate.send("test", JSON.toJSONString(message));
}
}
1)代码参考:GroupConsumer.java,Listener拷贝3份,分别赋予两组group,验证分组消费:
//测试组消费
@Component
public class GroupConsumer {
private final Logger logger = LoggerFactory.getLogger(GroupConsumer.class);
//组1,消费者1
@KafkaListener(topics = {"test"},groupId = "group1")
public void onMessage1(ConsumerRecord<?, ?> consumerRecord) {
Optional<?> optional = Optional.ofNullable(consumerRecord.value());
if (optional.isPresent()) {
Object msg = optional.get();
logger.info("group:group1-1 , message:{}", msg);
}
}
//组1,消费者2
public void onMessage2(ConsumerRecord<?, ?> consumerRecord) {
logger.info("group:group1-2 , message:{}", msg);
//组2,只有一个消费者
@KafkaListener(topics = {"test"},groupId = "group2")
public void onMessage3(ConsumerRecord<?, ?> consumerRecord) {
logger.info("group:group2 , message:{}", msg);
}
2)启动
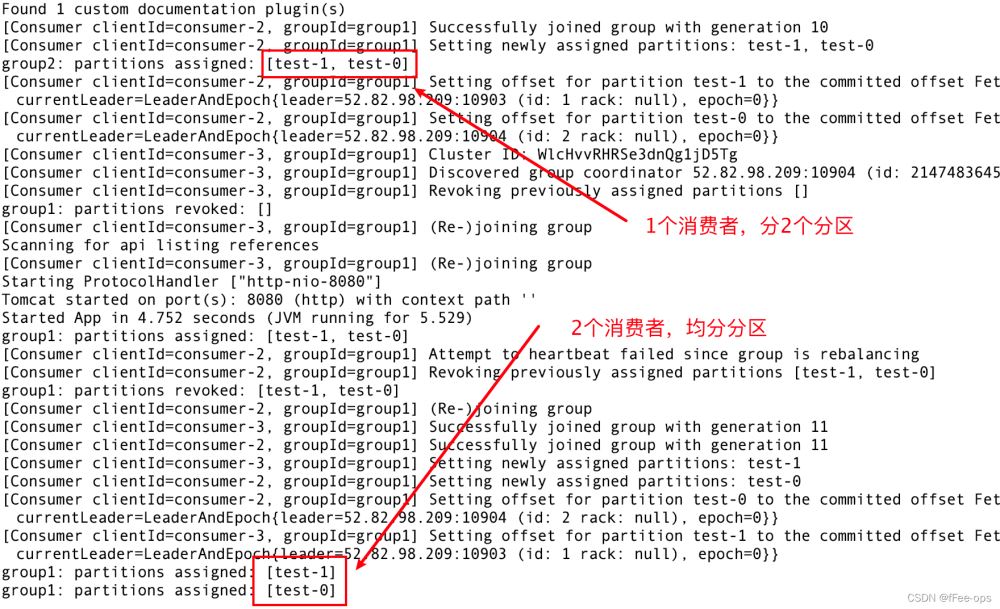
3)通过swagger发送2条消息

- 同一group下的两个消费者,在group1均分消息
- group2下只有一个消费者,得到全部消息
4)消费端闲置
注意分区数与消费者数的搭配,如果 ( 消费者数 > 分区数量 ),将会出现消费者闲置(因为一个分区只能分配给一个消费者),浪费资源!
验证方式:
停掉项目,删掉test主题,重新建一个 ,这次只给它分配一个分区。
重新发送两条消息,试一试

- group2可以消费到1、2两条消息
- group1下有两个消费者,但是只分配给了 1 , 2这个进程被闲置
3.2 位移提交
1)自动提交
前面的案例中,我们设置了以下两个选项,则kafka会按延时设置自动提交
enable-auto-commit: true # 是否自动提交offset auto-commit-interval: 100 # 提交offset延时(接收到消息后多久提交offset,默认单位为ms)
2)手动提交
有些时候,我们需要手动控制偏移量的提交时机,比如确保消息严格消费后再提交,以防止丢失或重复。
下面我们自己定义配置,覆盖上面的参数
代码参考:MyOffsetConfig.java
@Configuration
public class MyOffsetConfig {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Bean
public KafkaListenerContainerFactory<?> manualKafkaListenerContainerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
configProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
configProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// 注意这里!!!设置手动提交
configProps.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
ConcurrentKafkaListenerContainerFactory<String, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(new DefaultKafkaConsumerFactory<>(configProps));
// ack模式:
// AckMode针对ENABLE_AUTO_COMMIT_CONFIG=false时生效,有以下几种:
//
// RECORD
// 每处理一条commit一次
// BATCH(默认)
// 每次poll的时候批量提交一次,频率取决于每次poll的调用频率
// TIME
// 每次间隔ackTime的时间去commit(跟auto commit interval有什么区别呢?)
// COUNT
// 累积达到ackCount次的ack去commit
// COUNT_TIME
// ackTime或ackCount哪个条件先满足,就commit
// MANUAL
// listener负责ack,但是背后也是批量上去
// MANUAL_IMMEDIATE
// listner负责ack,每调用一次,就立即commit
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);
return factory;
}
}
然后通过在消费端的Consumer来提交偏移量
MyOffsetConsumer:
@Component
public class MyOffsetConsumer {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
@KafkaListener(topics = "test", groupId = "myoffset-group-1", containerFactory = "manualKafkaListenerContainerFactory")
public void manualCommit(@Payload String message,
@Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition,
@Header(KafkaHeaders.RECEIVED_TOPIC) String topic,
Consumer consumer,
Acknowledgment ack) {
logger.info("手动提交偏移量 , partition={}, msg={}", partition, message);
// 同步提交
consumer.commitSync();
//异步提交
//consumer.commitAsync();
// ack提交也可以,会按设置的ack策略走(参考MyOffsetConfig.java里的ack模式)
// ack.acknowledge();
}
@KafkaListener(topics = "test", groupId = "myoffset-group-2", containerFactory = "manualKafkaListenerContainerFactory")
public void noCommit(@Payload String message,
@Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition,
@Header(KafkaHeaders.RECEIVED_TOPIC) String topic,
Consumer consumer,
Acknowledgment ack) {
logger.info("忘记提交偏移量, partition={}, msg={}", partition, message);
// 不做commit!
/**
* 现实状况:
* commitSync和commitAsync组合使用
* <p>
* 手工提交异步 consumer.commitAsync();
* 手工同步提交 consumer.commitSync()
* commitSync()方法提交最后一个偏移量。在成功提交或碰到无怯恢复的错误之前,
* commitSync()会一直重试,但是commitAsync()不会。
* 一般情况下,针对偶尔出现的提交失败,不进行重试不会有太大问题
* 因为如果提交失败是因为临时问题导致的,那么后续的提交总会有成功的。
* 但如果这是发生在关闭消费者或再均衡前的最后一次提交,就要确保能够提交成功。否则就会造成重复消费
* 因此,在消费者关闭前一般会组合使用commitAsync()和commitSync()。
*/
// @KafkaListener(topics = "test", groupId = "myoffset-group-3",containerFactory = "manualKafkaListenerContainerFactory")
public void manualOffset(@Payload String message,
try {
logger.info("同步异步搭配 , partition={}, msg={}", partition, message);
//先异步提交
consumer.commitAsync();
//继续做别的事
} catch (Exception e) {
System.out.println("commit failed");
} finally {
try {
consumer.commitSync();
} finally {
consumer.close();
}
}
* 甚至可以手动提交,指定任意位置的偏移量
* 不推荐日常使用!!!
// @KafkaListener(topics = "test", groupId = "myoffset-group-4",containerFactory = "manualKafkaListenerContainerFactory")
public void offset(ConsumerRecord record, Consumer consumer) {
logger.info("手动指定任意偏移量, partition={}, msg={}", record.partition(), record);
Map<TopicPartition, OffsetAndMetadata> currentOffset = new HashMap<>();
currentOffset.put(new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1));
consumer.commitSync(currentOffset);
}
3)重复消费问题
如果手动提交模式被打开,一定不要忘记提交偏移量。否则会造成重复消费!
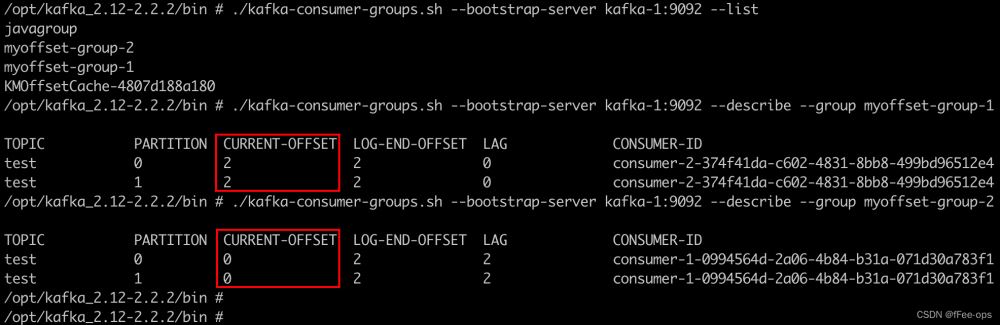
用km将test主题删除,新建一个test空主题。方便观察消息偏移 注释掉其他Consumer的Component注解,只保留当前MyOffsetConsumer.java 启动项目,使用swagger的KafkaProducer发送连续几条消息 留心控制台,都能消费,没问题:

但是!重启项目:

无论重启多少次,不提交偏移量的消费组,会重复消费一遍!!!
再通过命令行查询偏移量
4)经验与总结
commitSync()方法,即同步提交,会提交最后一个偏移量。在成功提交或碰到无怯恢复的错误之前,commitSync()会一直重试,但是commitAsync()不会。
这就造成一个陷阱:
如果异步提交,针对偶尔出现的提交失败,不进行重试不会有太大问题,因为如果提交失败是因为临时问题导致的,那么后续的提交总会有成功的。只要成功一次,偏移量就会提交上去。
但是!如果这是发生在关闭消费者时的最后一次提交,就要确保能够提交成功,如果还没提交完就停掉了进程。就会造成重复消费!
因此,在消费者关闭前一般会组合使用commitAsync()和commitSync()。
详细代码参考:MyOffsetConsumer.manualOffset()
到此这篇关于Springboot整合kafka的文章就介绍到这了,更多相关Springboot整合kafka内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

SpringBoot集成kafka全面实战记录
本文是SpringBoot+Kafka的实战讲解,如果对kafka的架构原理还不了解的读者,建议先看一下<大白话kafka架构原理>.<秒懂kafka HA(高可用)>两篇文章. 一.生产者实践 普通生产者 带回调的生产者 自定义分区器 kafka事务提交 二.消费者实践 简单消费 指定topic.partition.offset消费 批量消费 监听异常处理器 消息过滤器 消息转发 定时启动/停止监听器 一.前戏 1.在项目中连接kafka,因为是外网,首先要开放kafka配置文件
-
Springboot集成Kafka实现producer和consumer的示例代码
本文介绍如何在springboot项目中集成kafka收发message. Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性: 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能.高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息.支持通过Kafka服务器和消费机集群来分区消息.支持Hadoop并行数据加载. 安装Kafka 因为安装kafka需要zookeeper的支持,所以Windows安装时需要将zookee
-
SpringBoot集成Kafka的步骤
SpringBoot集成Kafka 本篇主要讲解SpringBoot 如何集成Kafka ,并且简单的 编写了一个Demo 来测试 发送和消费功能 前言 选择的版本如下: springboot : 2.3.4.RELEASE spring-kafka : 2.5.6.RELEASE kafka : 2.5.1 zookeeper : 3.4.14 本Demo 使用的是 SpringBoot 比较高的版本 SpringBoot 2.3.4.RELEASE 它会引入 spring-kafka 2.5
-
SpringBoot Kafka 整合使用及安装教程
前提 假设你了解过 SpringBoot 和 Kafka. 1.SpringBoot 如果对 SpringBoot 不了解的话,建议去看看 DD 大佬 和 纯洁的微笑 的系列博客. 2.Kafka Kafka 的话可以看看我前两天写的博客 : Kafka 安装及快速入门 学习的话自己开台虚拟机自己手动搭建环境吧,有条件的买服务器. 注意:一定要亲自自己安装实践,接下来我们将这两个进行整合. 创建项目 项目整体架构: 使用 IDEA 创建 SpringBoot 项目,这个很简单了,这里不做过多的讲
-
Springboot整合kafka的示例代码
目录 1. 整合kafka 2. 消息发送 2.1 发送类型 2.2 序列化 2.3 分区策略 3. 消息消费 3.1 消息组别 3.2 位移提交 1. 整合kafka 1.引入依赖 <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency> 2.设置yml文件 spring:
-
SpringBoot 整合 JMSTemplate的示例代码
1.1 添加依赖 可以手动在 SpringBoot 项目添加依赖,也可以在项目创建时选择使用 ActiveMQ 5 自动添加依赖.高版本 SpringBoot (2.0 以上) 在添加 activemq 连接池依赖启动时会报 Error creating bean with name 'xxx': Unsatisfied dependency expressed through field 'jmsTemplate'; 可以将 activemq 连接池换成 jms 连接池解决. <depen
-
SpringBoot整合SpringDataRedis的示例代码
本文介绍下SpringBoot如何整合SpringDataRedis框架的,SpringDataRedis具体的内容在前面已经介绍过了,可自行参考. 1.创建项目添加依赖 创建SpringBoot项目,并添加如下依赖: <dependencies> <!-- springBoot 的启动器 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId
-
SpringBoot整合ShardingSphere的示例代码
目录 一.相关依赖 二.Nacos数据源配置 三.项目配置 四.验证 概要: ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC.Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成. 他们均提供标准化的数据分片.分布式事务和数据库治理功能,可适用于如Java同构.异构语言.云原生等各种多样化的应用场景. 官网地址:https://shardingsphere.apache.org/ 一.相关
-
SpringBoot整合MyBatis-Plus的示例代码
目录 前言 源码 环境 开发工具 SQL脚本 正文 单工程 POM文件(注意) application.properties(注意) 自定义配置(注意) 实体类(注意) Mapper接口(注意) Service服务实现类(注意) Controller前端控制器(注意) SpringBoot启动类(注意) 启用项目,调用接口(注意) 多工程 commons工程-POM文件 MyBatis-Plus commons工程-system.properties commons工程- 自定义配置 commo
-
springboot 整合sentinel的示例代码
目录 1. 安装sentinel 2.客户端连接 1. 安装sentinel 下载地址:https://github.com/alibaba/Sentinel/releases/tag/1.7.0 ,由于我无法下载,所以使用docker安装, yuchunfang@yuchunfangdeMacBook-Pro ~ % docker pull bladex/sentinel-dashboard:1.7.0 yuchunfang@yuchunfangdeMacBook-Pro ~ % docker
-
springboot 整合hbase的示例代码
目录 前言 HBase 定义 HBase 数据模型 物理存储结构 数据模型 1.Name Space 2.Region 3.Row 4.Column 5.Time Stamp 6.Cell 搭建步骤 1.官网下载安装包: 2.配置hadoop环境变量 3.修改 hbase-env.cmd配置文件 4.修改hbase-site.xml 文件 5.启动hbase服务 6.hbase客户端测试 Java API详细使用 1.导入客户端依赖 2.DDL相关操作 3.DML相关操作 插入数据与查询数据 H
-
springboot整合xxl-job的示例代码
目录 关于xxl-job 调度中心 执行器 关于xxl-job 在我看来,总体可以分为三大块: 调度中心 执行器 配置定时任务 调度中心 简单来讲就是 xxl-job-admin那个模块,配置: 从doc里面取出xxl-job.sql的脚本文件,创建对应的数据库. 进行配置文件的配置,如下图 进行日志存放位置的修改 然后idea打包之后就能当作调度中心运行了 访问地址:ip:port/xxl-job-admin 默认的账号密码:admin/123456 注意:你进去后修改密码,有些浏览器就算你账
-
SpringBoot整合Liquibase的示例代码
目录 整合1 整合2 SpringBoot整合Liquibase虽然不难但坑还是有一点的,主要集中在配置路径相关的地方,在此记录一下整合的步骤,方便以后自己再做整合时少走弯路,当然也希望能帮到大家~ 整合有两种情况 在启动项目时自动执行脚本,若新添加了Liquibase脚本需要重启项目才能执行脚本 在不启动项目时也能通过插件或指令手动让它执行脚本 整合要么只整合1,要么1.2一起整合 只整合2不整合1的话,项目启动时会生成liquibase相关的bean时报错 整合1 引入Maven依赖 这里导
-
SpringBoot整合JdbcTemplate的示例代码
目录 前言 初始化SpringBoot项目 使用IDEA创建项目 导入JDBC依赖 导入数据库驱动 修改配置文件 数据库sys_user表结构 测试类代码 查询sys_user表数据量 查询sys_user表一条数据 查询sys_user表所有数据 新增sys_user表一条数据 修改sys_user表一条数据 删除sys_user表一条数据 总结 前言 Spring对数据库的操作在jdbc上面做了更深层次的封装,而JdbcTemplate便是Spring提供的一个操作数据库的便捷工具.我们可以