Python实现奇数列与偶数列调换的方法详解
目录
- 一、前言
- 二、实现过程
- 方法一
- 方法二
- 方法三
- 三、总结
一、前言
前几天在Python铂金交流群【瑜亮老师】给大家出了一道Pandas数据处理题目,使用Python实现df的奇数列与偶数列调换位置,比如A列,B列,调换成B列,A列。

下面是原始内容。
en = 'abcdef'
df = pd.DataFrame([[i + j for j in list(en)] for i in list(en)], columns=list(en.upper()), index=list(en.upper()))
print('源数据')
print(df)
# 请补全代码
#
print('转换后')
print(df)
结果如下图所示:

二、实现过程
方法一
这里【kiddo】给出了一个解答,代码和结果如下图所示。

方法二
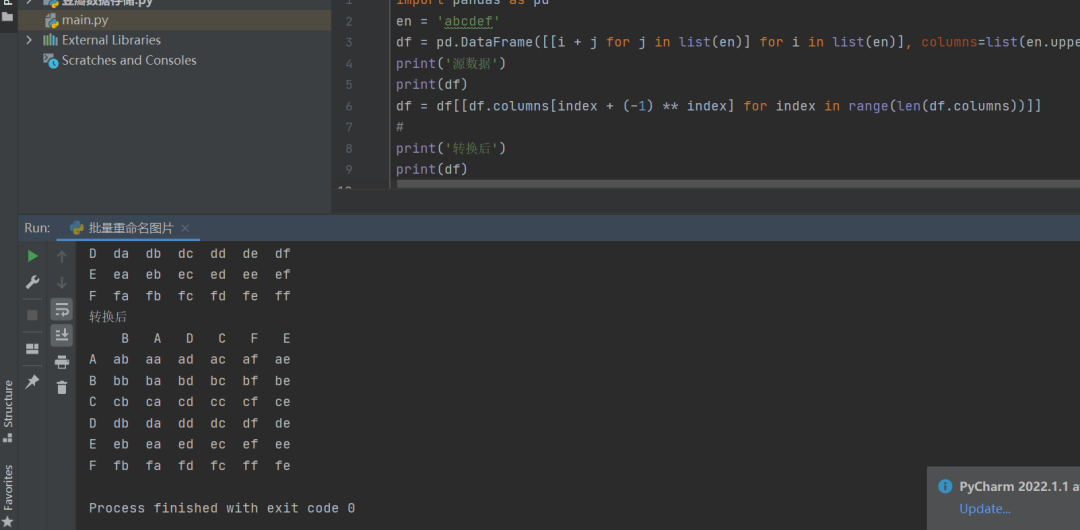
这里【月神】基于第一个方法,也给出了一个简化答案,7到16行就可以写成下面这样,代码如下所示:
df = df[[df.columns[index + (-1) ** index] for index in range(len(df.columns))]]

运行之后,结果如下图所示:
方法三
【月神】后来又给了一个方法,代码如下所示:
import numpy as np
import pandas as pd
# 数据已经帮你写好,请补全剩余代码,实现上述功能。
en = 'abcdef'
df = pd.DataFrame([[i + j for j in list(en)] for i in list(en)], columns=list(en.upper()), index=list(en.upper()))
print('源数据')
print(df)
# 请补全代码
df = df[np.array((df.columns[1::2], df.columns[::2])).flatten('F')]
print('转换后')
print(df)
运行之后,结果如下图所示:

八仙过海,神仙操作,简直太强了!
三、总结
这篇文章主要盘点了使用Python实现df的奇数列与偶数列调换位置,比如A列,B列,调换成B列,A列的问题,文中针对该问题给出了具体的解析和代码演示,一共3个方法。
以上就是Python实现奇数列与偶数列调换的方法详解的详细内容,更多关于Python数列调换的资料请关注我们其它相关文章!
相关推荐
-

利用Python实现外观数列求解
目录 1. 引言 2. 外观数列 3. 代码思路 3.1 提取输出的key 3.2 提取每个key对应的value 3.3 统计每个group对应的长度 3.4 整合输出 3.5 解决方案 4. 总结 1. 引言 事情的由来是这样的,今天遇到一个非常有意思的题目,如下: 1–11–21–1211–111221–312211 观察上述数字,找出其中的规律,并尝试思考给出下一个数字?哇偶,可以先仔细思考一下下... 2. 外观数列 外观数列是一个整数序列,从数字 1 开始,序列中的每一项都是对前一项
-
python斐波那契数列的计算方法
题目: 计算斐波那契数列.具体什么是斐波那契数列,那就是0,1,1,2,3,5,8,13,21,34,55,89,144,233. 要求: 时间复杂度尽可能少 分析: 给出了三种方法: 方法1:递归的方法,在这里空间复杂度非常大.如果递归层数非常多的话,在python里需要调整解释器默认的递归深度.默认的递归深度是1000.我调整了半天代码也没有调整对,因为递归到1000已经让我的电脑的内存有些撑不住了. 方法2:将递归换成迭代,这样时间复杂度也在代码中标注出来了. 方法3:这种方法利用了求幂的
-
python numpy生成等差数列、等比数列的实例
如下所示: import numpy as np # 等差数列 print(np.linspace(0.1, 1, 10, endpoint=True)) print(np.arange(0.1, 1.1, 0.1)) """总结: arange 侧重点在于增量,不管产生多少个数 linspace 侧重于num, 即要产生多少个元素,不在乎增量 """ # 等比数列 np.logspace(1, 4, 4, endpoint=True, base
-
python求质数列表的例子
因为写别的程序想要一边遍历一边删除列表里的元素,就写了一个这样的程序进行测试,这样写出来感觉还挺简洁的,就发出来分享一下. 代码 l=list(range(2,1000)) for n,i in enumerate(l): for j in l[n+1:]: if j%i==0: l.remove(j) print(l) 原理其实就是删除每个数的倍数,如果而没被删除的当然就是质数. 以上这篇python求质数列表的例子就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
python 等差数列末项计算方式
等差数列末项计算 题目内容: 给出一个等差数列的前两项a1,a2,求第n项是多少 可以使用以下语句实现非负整数n的输入: n=int(input()) 输入格式: 三行,包含三个整数a1,a2,n 输出格式: 一个整数,即第n项的值 输入样例: 1 4 100 输出样例: 298 My answer 思路一:等差数列,先求差m是多少,第n项的值很多种方法算,我就采用这种a1 + m*(n-1) a1 = int(input()) a2 = int(input()) m = a2 - a1 n =
-
python 实现单一数字取对数与数列取对数
python取对数可以采用两种工具包,math包可对单一数字取对数,numpy可以数列整体取对数. 1.仅对单一数字取对数 import math math.log(2) #默认以e为底 math.log(4,2)#以2为底,4的对数 即math.log(c,b) #计算以b为底,c的对数 2.对数列整体求对数 对一个数列取对数 需要numpy包 import numpy numpy.log([2,4,8])#以e为底,分别对2,4,8取对数 numpy.log2([2,4,8])#以2为底,分
-
Python实现奇数列与偶数列调换的方法详解
目录 一.前言 二.实现过程 方法一 方法二 方法三 三.总结 一.前言 前几天在Python铂金交流群[瑜亮老师]给大家出了一道Pandas数据处理题目,使用Python实现df的奇数列与偶数列调换位置,比如A列,B列,调换成B列,A列. 下面是原始内容. en = 'abcdef' df = pd.DataFrame([[i + j for j in list(en)] for i in list(en)], columns=list(en.upper()), index=list(en.u
-
python中读入二维csv格式的表格方法详解(以元组/列表形式表示)
如何去读取一个没有表头的二维csv文件(如下图所示)? 并以元组的形式表现数据: ((1.0, 0.0, 3.0, 180.0), (2.0, 0.0, 2.0, 180.0), (3.0, 0.0, 1.0, 180.0), (4.0, 0.0, 0.0, 180.0), (5.0, 0.0, 3.0, 178.0)) 方法一,使用python内建的数据处理库: #python自带的库 rows = open('allnodes.csv','r',encoding='utf-8').readl
-
Python实现从文件中加载数据的方法详解
前几篇都是手动录入或随机函数产生的数据.实际有许多类型的文件,以及许多方法,用它们从文件中提取数据来图形化. 比如之前python基础(12)介绍打开文件的方式,可直接读取文件中的数据,扩大了我们的数据来源.下面,将展示几种方法. 我们将使用内置的 csv 模块加载CSV文件 CSV文件是一种特殊的文本文件,文件中的数据以逗号作为分隔符,很适合进行数据的解析.先用excle建立如下表格和数据,另存为csv格式文件,放到代码目录下. 包含在Python标准库中自带CSV 模块,我们只需要impor
-
Python 3.6 性能测试框架Locust安装及使用方法(详解)
背景 Python3.6 性能测试框架Locust的搭建与使用 基础 python版本:python3.6 开发工具:pycharm Locust的安装与配置 点击"File"→"setting" 点击"setting",进入设置窗口,选择"Project Interpreter" 点击"+" 输入需要"Locust",点击"Install Package" 安装完成
-
对Python 多线程统计所有csv文件的行数方法详解
如下所示: #统计某文件夹下的所有csv文件的行数(多线程) import threading import csv import os class MyThreadLine(threading.Thread): #用于统计csv文件的行数的线程类 def __init__(self,path): threading.Thread.__init__(self) #父类初始化 self.path=path #路径 self.line=-1 #统计行数 def run(self): reader =
-
对python中xlsx,csv以及json文件的相互转化方法详解
最近需要各种转格式,这里对相关代码作一个记录,方便日后查询. xlsx文件转csv文件 import xlrd import csv def xlsx_to_csv(): workbook = xlrd.open_workbook('1.xlsx') table = workbook.sheet_by_index(0) with codecs.open('1.csv', 'w', encoding='utf-8') as f: write = csv.writer(f) for row_num
-
对Python中一维向量和一维向量转置相乘的方法详解
在Python中有时会碰到需要一个一维列向量(n*1)与另一个一维列向量(n*1)的转置(1*n)相乘,得到一个n*n的矩阵的情况.但是在python中, 我们发现,无论是".T"还是"np.transpose"都无法实现一维向量的转置,相比之下,Matlab一句" a' "就能实现了. 那怎么实现呢?我找了个方法.请看: 即,我们把向量reshape一下,如此便实现了一维向量与一维向量转置相乘为矩阵的目的. 若大家有其他方法望告知. 以上这篇对
-
Python之使用adb shell命令启动应用的方法详解
一直有一个心愿希望可以用Python做安卓自动化功能测试,在一步步摸索中,之前是用monkeyrunner,但是发现对于控件ID的使用非常具有局限性,尤其是ID的内容不便于区分 具有重复性时,后面又发现Uiautomator可以对resorceId.text.packageName等元素进行定位,也找到了xiaochong这位大神关于uiautomator的封装包,链接如下: https://github.com/xiaocong/uiautomator 做为一个小白,这一切都需要摸索,在克服了
-
对Python正则匹配IP、Url、Mail的方法详解
如下所示: """ Created on Thu Nov 10 14:07:36 2016 @author: qianzhewoniuqusanbu """ import re def RegularMatchIP(ip): '''进行正则匹配ip,加re.IGNORECASE是让结果返回bool型''' pattern=re.match(r'\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?
-
对python打乱数据集中X,y标签对的方法详解
今天踩过的两个小坑: 一.用random的shuffle打乱数据集中的数据-标签对 index=[i for i in range(len(X_batch))] # print(type(index)) index=random.shuffle(index) 结果shuffle完以后index变成None了,看了下api,这样说明的: 这个函数如果返回值,就返回None,所以用index=balabala就把index的内容改变了.去掉index=random.shuffle(index)等号前