Python数据合并的concat函数与merge函数详解
目录
- 一、concat函数
- 1)横向堆叠与外连接
- 2) 纵向堆叠与内链接
- 二、merge()函数
- 1)根据行索引合并数据
- 2)合并重叠数据
一、concat函数
1.concat()函数可以沿着一条轴将多个对象进行堆叠,其使用方式类似数据库中的数据表合并
pandas.concat(objs, axis=0, join=’outer’, join_axes=None, ignore_index=False, keys=None, levels=None, verify_integrity=False, sort=None, copy=True)
2.参数含义如下:
| 参数 | 作用 |
|---|---|
| axis | 表示连接的轴向,可以为0或者1,默认为0 |
| join | 表示连接的方式,inner表示内连接,outer表示外连接,默认使用外连接 |
| ignore_index | 接收布尔值,默认为False。如果设置为True,则表示清除现有索引并重置索引值 |
| keys | 接收序列,表示添加最外层索引 |
| levels | 用于构建MultiIndex的特定级别(唯一值) |
| names | 设置了keys和level参数后,用于创建分层级别的名称 |
| verify_integerity | 检查新的连接轴是否包含重复项。接收布尔值,当设置为True时,如果有重复的轴将会抛出错误,默认为False |
3.根据轴方向的不同,可以将堆叠分成横向堆叠与纵向堆叠,默认采用的是纵向堆叠方式

4.在堆叠数据时,默认采用的是外连接(join参数设为outer)的方式进行合并,当然也可以通过join=inner设置为内连接的方式。

1)横向堆叠与外连接
import pandas as pd
df1=pd.DataFrame({'A':['A0','A1','A2'],
'B':['B0','B1','B2']})
df1

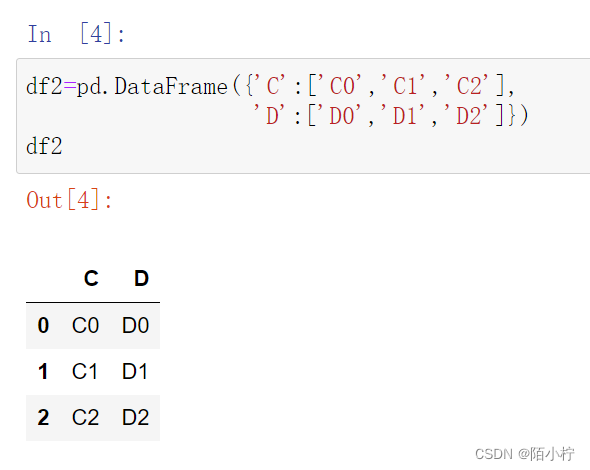
横向堆叠合并df1和df2,采用外连接的方式
pd.concat([df1,df2],join='outer',axis=1)

2) 纵向堆叠与内链接
import pandas as pd
first=pd.DataFrame({'A':['A0','A1','A2'],
'B':['B0','B1','B2'],
'C':['C0','C1','C2']})
first

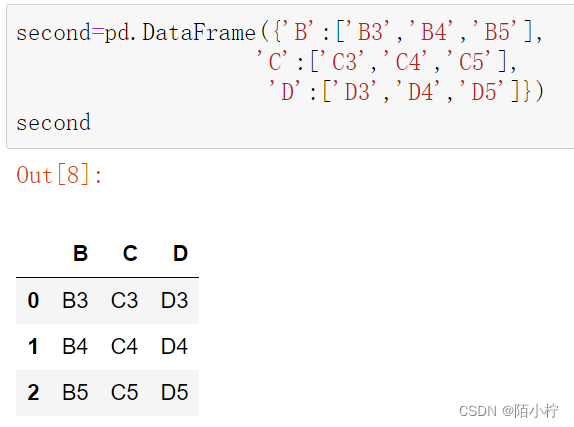
second=pd.DataFrame({'B':['B3','B4','B5'],
'C':['C3','C4','C5'],
'D':['D3','D4','D5']})
second
3.当使用concat()函数合并时,若是将axis参数的值设为0,且join参数的值设为inner,则代表着使用纵向堆叠与内连接的方式进行合并
pd.concat([first,second],join='inner',axis=0)

二、merge()函数
1)主键合并数据
在使用merge()函数进行合并时,默认会使用重叠的列索引做为合并键,并采用内连接方式合并数据,即取行索引重叠的部分。
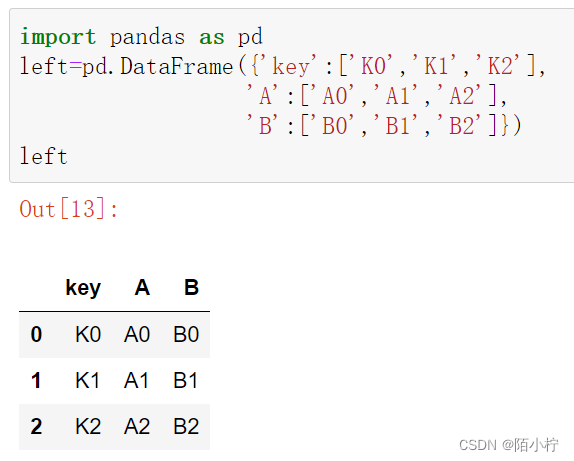
import pandas as pd
left=pd.DataFrame({'key':['K0','K1','K2'],
'A':['A0','A1','A2'],
'B':['B0','B1','B2']})
left
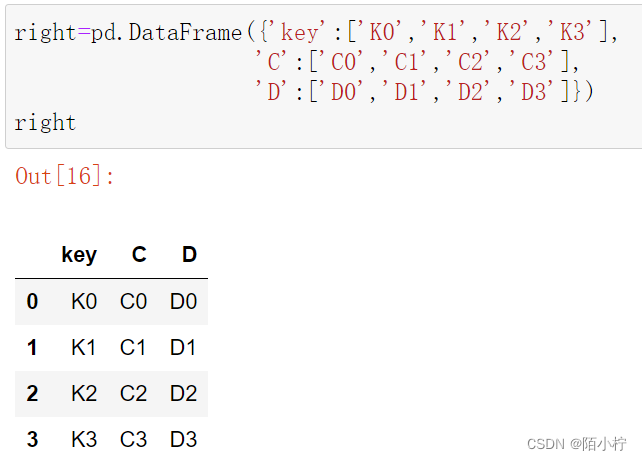
right=pd.DataFrame({'key':['K0','K1','K2','K3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']})
right
pd.merge(left,right,on='key')

2)merge()函数还支持对含有多个重叠列的DataFrame对象进行合并。
import pandas as pd
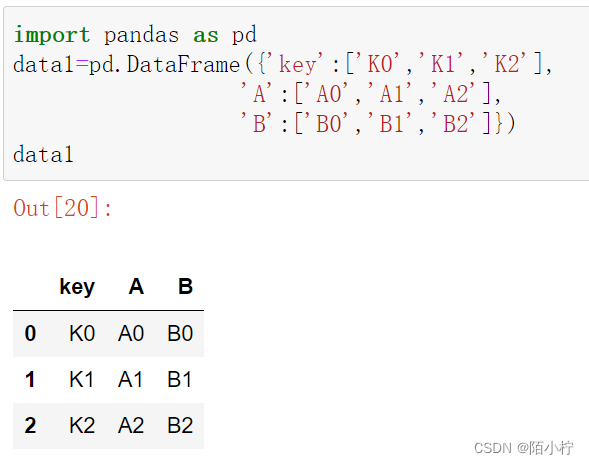
data1=pd.DataFrame({'key':['K0','K1','K2'],
'A':['A0','A1','A2'],
'B':['B0','B1','B2']})
data1
data2=pd.DataFrame({'key':['K0','K5','K2','K4'],
'B':['B0','B1','B2','B5'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']})
data2

pd.merge(data1,data2,on=['key','B'])

1)根据行索引合并数据
join()方法能够通过索引或指定列来连接多个DataFrame对象
join(other,on = None,how =‘left’,lsuffix =‘’,rsuffix =‘’,sort = False )
| 参数 | 作用 |
|---|---|
| on | 名称,用于连接列名 |
| how | 可以从{‘‘left’’ ,‘‘right’’, ‘‘outer’’, ‘‘inner’’}中任选一个,默认使用左连接的方式。 |
| sort | 根据连接键对合并的数据进行排序,默认为False |
import pandas as pd
data3=pd.DataFrame({'A':['A0','A1','A2'],
'B':['B0','B1','B2']})
data3

data4=pd.DataFrame({'C': ['C0', 'C1', 'C2'],
'D': ['D0', 'D1', 'D2']},
index=['a','b','c'])
data3.join(data4,how='outer') # 外连接

data3.join(data4,how='left') #左连接

data3.join(data4,how='right') #右连接

data3.join(data4,how='inner') #内连接

import pandas as pd
left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2'],
'key': ['K0', 'K1', 'K2']})
left

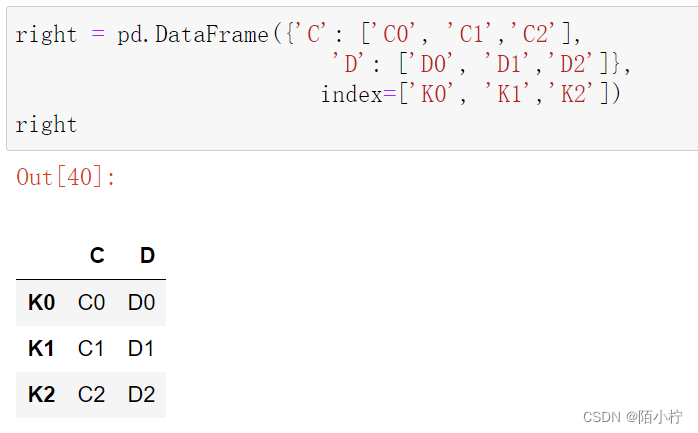
right = pd.DataFrame({'C': ['C0', 'C1','C2'],
'D': ['D0', 'D1','D2']},
index=['K0', 'K1','K2'])
right
on参数指定连接的列名
left.join(right,how='left',on='key') #on参数指定连接的列名

2)合并重叠数据
当DataFrame对象中出现了缺失数据,而我们希望使用其他DataFrame对象中的数据填充缺失数据,则可以通过combine_first()方法为缺失数据填充。
import pandas as pd
import numpy as np
from numpy import NAN
left = pd.DataFrame({'A': [np.nan, 'A1', 'A2', 'A3'],
'B': [np.nan, 'B1', np.nan, 'B3'],
'key': ['K0', 'K1', 'K2', 'K3']})
left

right = pd.DataFrame({'A': ['C0', 'C1','C2'],
'B': ['D0', 'D1','D2']},
index=[1,0,2])
right

用right的数据填充left缺失的部分
left.combine_first(right) # 用right的数据填充left缺失的部分

到此这篇关于Python数据合并的concat函数与merge函数详解的文章就介绍到这了,更多相关python 数据合并concat函数与merge函数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

一文搞懂Python中Pandas数据合并
目录 1.concat() 主要参数 示例 2.merge() 参数 示例 3.append() 参数 示例 4.join() 示例 数据合并是数据处理过程中的必经环节,pandas作为数据分析的利器,提供了四种常用的数据合并方式,让我们看看如何使用这些方法吧! 1.concat() concat() 可用于两个及多个 DataFrame 间行/列方向进行内联或外联拼接操作,默认对行(沿 y 轴)取并集. 使用方式 pd.concat( objs: Union[Iterable[~FrameOr
-
Python基础之pandas数据合并
一.concat concat函数是在pandas底下的方法,可以将数据根据不同的轴作简单的融合 pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False) axis: 需要合并链接的轴,0是行,1是列join:连接的方式 inner,或者outer 二.相同字段的表首尾相接 #现将表构成l
-
python 数据清洗之数据合并、转换、过滤、排序
前面我们用pandas做了一些基本的操作,接下来进一步了解数据的操作, 数据清洗一直是数据分析中极为重要的一个环节. 数据合并 在pandas中可以通过merge对数据进行合并操作. import numpy as np import pandas as pd data1 = pd.DataFrame({'level':['a','b','c','d'], 'numeber':[1,3,5,7]}) data2=pd.DataFrame({'level':['a','b','c','e'], '
-
Python自定义聚合函数merge与transform区别详解
1.自定义聚合函数,结合agg使用 2. 同时使用多个聚合函数 3. 指定某一列使用某些聚合函数 4.merge与transform使用 import pandas as pd import numpy as np np.random.seed(1) dict_data = { 'k1': ['a', 'b', 'c', 'd', 'a', 'b', 'c', 'd'], 'k2': ['A', 'B', 'C', 'D', 'A', 'B', 'C', 'D'], 'data1': np.ra
-
Python必备技巧之Pandas数据合并函数
目录 1. concat 2. append 3. merge 4. join 5. combine 总结 1. concat concat是pandas中专门用于数据连接合并的函数,功能非常强大,支持纵向合并和横向合并,默认情况下是纵向合并,具体可以通过参数进行设置. pd.concat( objs: 'Iterable[NDFrame] | Mapping[Hashable, NDFrame]', axis=0, join='outer', ignore_index: 'bool' = Fa
-
Python Merge函数原理及用法解析
Merge函数的用法 简单来说Merge函数相当于Excel中的vlookup函数.当我们对2个表进行数据合并的时候需要通过指定两个表中相同的列作为key,然后通过key匹配到其中要合并在一起的values值. 然后对于merge函数在Pandas中分为1vs1, 多(m)vs1,以及多(m)vs多(m)这三种场景.但是平时用的最多的往往是多vs1的这种场景.也就是说2个表中其中一个表作为key的值会出现重复,而另外一个表作为key的值则是唯一. 这种场景也很好理解.例如:我们在生产环境中对服务
-
Python数据合并的concat函数与merge函数详解
目录 一.concat函数 1)横向堆叠与外连接 2) 纵向堆叠与内链接 二.merge()函数 1)根据行索引合并数据 2)合并重叠数据 一.concat函数 1.concat()函数可以沿着一条轴将多个对象进行堆叠,其使用方式类似数据库中的数据表合并pandas.concat(objs, axis=0, join=’outer’, join_axes=None, ignore_index=False, keys=None, levels=None, verify_integrity=Fals
-
基于Python数据可视化利器Matplotlib,绘图入门篇,Pyplot详解
Pyplot matplotlib.pyplot是一个命令型函数集合,它可以让我们像使用MATLAB一样使用matplotlib.pyplot中的每一个函数都会对画布图像作出相应的改变,如创建画布.在画布中创建一个绘图区.在绘图区上画几条线.给图像添加文字说明等.下面我们就通过实例代码来领略一下他的魅力. import matplotlib.pyplot as plt plt.plot([1,2,3,4]) plt.ylabel('some numbers') plt.show() 上图是我们通
-
对python实现合并两个排序链表的方法详解
输入两个单调递增的链表,输出两个链表合成后的链表,当然我们需要合成后的链表满足单调不减规则. 1.迭代方法 def Merge(self, pHead1, pHead2): p1, p2 = pHead1, pHead2 if p1 and p2: if p1.val < p2.val: head = p1 p1 = p1.next else: head = p2 p2 = p2.next cur = head elif p1: return p1 else: return p2 while p
-
python数据可视化使用pyfinance分析证券收益示例详解
目录 pyfinance简介 pyfinance包含六个模块 returns模块应用实例 收益率计算 CAPM模型相关指标 风险指标 基准比较指标 风险调整收益指标 综合业绩评价指标分析实例 结语 pyfinance简介 在查找如何使用Python实现滚动回归时,发现一个很有用的量化金融包--pyfinance.顾名思义,pyfinance是为投资管理和证券收益分析而构建的Python分析包,主要是对面向定量金融的现有包进行补充,如pyfolio和pandas等. pyfinance包含六个模块
-
Python数据可视化常用4大绘图库原理详解
今天我们就用一篇文章,带大家梳理matplotlib.seaborn.plotly.pyecharts的绘图原理,让大家学起来不再那么费劲! 1. matplotlib绘图原理 关于matplotlib更详细的绘图说明,大家可以参考下面这篇文章,相信你看了以后一定学得会. matplotlib绘图原理:http://suo.im/678FCo 1)绘图原理说明 通过我自己的学习和理解,我将matplotlib绘图原理高度总结为如下几步: 导库;创建figure画布对象;获取对应位置的axes坐标
-
在Pandas中DataFrame数据合并,连接(concat,merge,join)的实例
最近在工作中,遇到了数据合并.连接的问题,故整理如下,供需要者参考~ 一.concat:沿着一条轴,将多个对象堆叠到一起 concat方法相当于数据库中的全连接(union all),它不仅可以指定连接的方式(outer join或inner join)还可以指定按照某个轴进行连接.与数据库不同的是,它不会去重,但是可以使用drop_duplicates方法达到去重的效果. concat(objs, axis=0, join='outer', join_axes=None, ignore_ind
-
对python中数据集划分函数StratifiedShuffleSplit的使用详解
文章开始先讲下交叉验证,这个概念同样适用于这个划分函数 1.交叉验证(Cross-validation) 交叉验证是指在给定的建模样本中,拿出其中的大部分样本进行模型训练,生成模型,留小部分样本用刚建立的模型进行预测,并求这小部分样本的预测误差,记录它们的平方加和.这个过程一直进行,直到所有的样本都被预测了一次而且仅被预测一次,比较每组的预测误差,选取误差最小的那一组作为训练模型. 下图所示 2.StratifiedShuffleSplit函数的使用 官方文档 用法: from sklearn.
-
对python打乱数据集中X,y标签对的方法详解
今天踩过的两个小坑: 一.用random的shuffle打乱数据集中的数据-标签对 index=[i for i in range(len(X_batch))] # print(type(index)) index=random.shuffle(index) 结果shuffle完以后index变成None了,看了下api,这样说明的: 这个函数如果返回值,就返回None,所以用index=balabala就把index的内容改变了.去掉index=random.shuffle(index)等号前
-
Python中关于元组 集合 字符串 函数 异常处理的全面详解
目录 元组 集合 字符串 1.字符串的驻留机制 2.常用操作 函数 1.函数的优点: 2.函数的创建:def 函数名([输入参数]) 3.函数的参数传递: 4.函数的返回值: 5.函数的参数定义: 6.变量的作用区域 7.递归函数:函数体内套用该函数本身 8.将函数存储在模块中 9.函数编写指南: Bug 1.Bug常见类型 2.常见异常类型 3.python异常处理机制 pycharm开发环境的调试 编程思想 (1)两种编程思想 (2)类和对象的创建 元组 元组是不可变序列 多任务环境下,同时
-
Python学习之魔法函数(filter,map,reduce)详解
目录 filter() 函数 map() 函数 reduce() 函数 filter() 函数 小实战 今天的这一章节我们来学习一下,Python 中的三个高级函数,也被称之为 魔法函数.之所以把他们交的这么高级,主要是因为它们返回的数据类型多数是 迭代器. 我们在上一章节有介绍过,迭代器 可以提升我们的代码的执行效率.降低内存消耗.所以接下来我们就认识一下这些 魔法函数. filter() 函数 filter() 函数 是python的一个内置函数. filter() 函数的功能:可以将一个可