C语言数据结构之复杂链表的拷贝
题目:
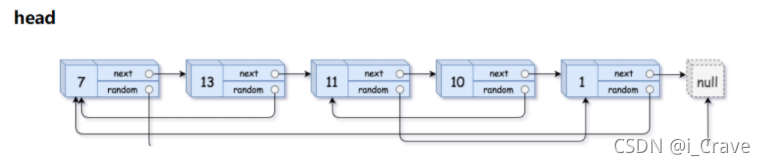
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
struct Node {
int val;
struct Node *next;
struct Node *random;
};
思路:
因为每个节点还有一个随机指针,向拷贝标准单向链表的方式才处理,是有困难的;
第一步,先将拷贝的节点链在原节点后面
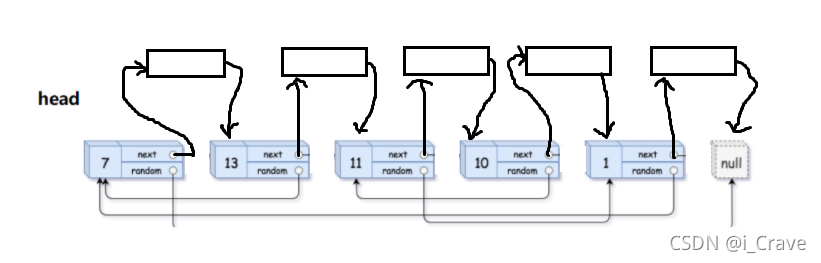
struct Node* cur = head;
while (cur)
{
struct Node* new = (struct Node*)malloc(sizeof(struct Node));
new->val = cur->val;
new->next = cur->next;
cur->next = new;
cur = new->next;
}
第二步,处理随机指针,因为拷贝的就在原节点后面,拷贝的随机指针就指向原节点随机指针的后一个;
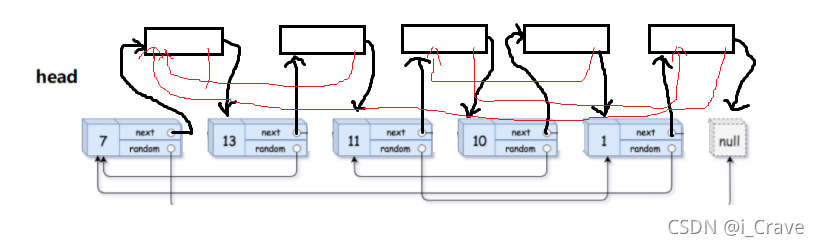
struct Node* cur = head;
while (cur)
{
struct Node* copy = cur->next;
if (cur->random == NULL)
{
copy->random = NULL;
}
else
{
copy->random = cur->random->next;
}
cur = copy->next;
}
第三步,将链表分开,并返回拷贝链表的头;
程序:
struct Node* copyRandomList(struct Node* head)
{
if (head == NULL)
{
return NULL;
}
struct Node* cur = head;
while (cur)
{
struct Node* new = (struct Node*)malloc(sizeof(struct Node));
new->val = cur->val;
new->next = cur->next;
cur->next = new;
cur = new->next;
}
cur = head;
while (cur)
{
struct Node* copy = cur->next;
if (cur->random == NULL)
{
copy->random = NULL;
}
else
{
copy->random = cur->random->next;
}
cur = copy->next;
}
cur = head;
struct Node* copyHead = head->next ,*copy_n=copyHead->next,*copy=copyHead;
while (cur)
{
if (copy_n == NULL)
{
copy->next = NULL;
cur->next = NULL;
return copyHead;
}
else
{
cur->next = copy_n;
copy->next = copy_n->next;
}
cur = copy_n;
copy = copy_n->next;
copy_n = copy->next;
}
return copyHead;
}
到此这篇关于C语言数据结构之复杂链表的拷贝的文章就介绍到这了,更多相关C语言 数据结构内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
C语言数据结构之单向链表详解分析
链表的概念:链表是一种动态存储分布的数据结构,由若干个同一结构类型的结点依次串连而成. 链表分为单向链表和双向链表. 链表变量一般用指针head表示,用来存放链表首结点的地址. 每个结点由数据部分和下一个结点的地址部分组成,即每个结点都指向下一个结点.最后一个结点称为表尾,其下一个结点的地址部分的值为NULL(表示为空地址). 特别注意:链表中的各个结点在内存中是可以不连续存放的,具体存放位置由系统分配. 例如:int *ptr ; 因此不可以用ptr++的方式来寻找下一个结点. 使用链表的优点
-

C语言数据结构创建及遍历十字链表
目录 一.十字链表是什么? 二.十字链表的存储结构 三.代码实现 1.引入头文件并定义结构体 2.建立十字链表 3.遍历十字链表 4.调用函数 本文需要读者有一定的代码基础,了解指针,链表,数组相关知识. 一.十字链表是什么? 十字链表常用于表示稀疏矩阵,可视作稀疏矩阵的一种链式表示,因此,这里以稀疏矩阵为背景介绍十字链表.不过,十字链表的应用远不止稀疏矩阵,一切具有正交关系的结构,都可用十字链表存储. 二.十字链表的存储结构 1.用于总结点的存储结构 m:总行数 n:总列数 len:总元素个数
-
C语言数据结构时间复杂度及空间复杂度简要分析
目录 一.时间复杂度和空间复杂度是什么? 1.1算法效率定义 1.2时间复杂度概念 1.3空间复杂度概念 二.如何计算常见算法的时间复杂度和空间复杂度 2.1时间复杂度计算 2.2空间复杂度计算 2.3快速推倒大O渐进表达法 三.一些特殊的情况 总结 一.时间复杂度和空间复杂度是什么? 1.1算法效率定义 算法效率分为两种,一种是时间效率--时间复杂度,另一种是空间效率--空间复杂度 1.2时间复杂度概念 时间复杂度,简言之就是你写一个代码,它解决一个问题上需要走多少步骤,需要花费多长时间.打个
-
C语言数据结构单链表接口函数全面讲解教程
目录 前言 一.链表的概念及结构 1.概念 二.链表的使用 1.遍历整个链表 2.尾插 3.头插 4.头删 5.尾删 6.任意位置插入数据 7.任意位置删除数据 后记 前言 上一期数据结构专栏我们学习了顺序表后:C语言数据结构顺序表 在运用时,细心的同学可能会发现,如果要头插.尾插或者任意位置.如果原先的空间已经被占满了,你是需要扩容的,动态链表扩容往往是2倍,但是扩容后,如果后面没有使用完全扩容后空间就会造成空间浪费,为了解决这个问题,我们今天将学习链表. 提示:以下是本篇文章正文内容,下面案
-
C语言数据结构之vector底层实现机制解析
目录 一.vector底层实现机制刨析 二.vector的核心框架接口的模拟实现 1.vector的迭代器实现 2.reserve()扩容 3.尾插尾删(push_back(),pop_back()) 4.对insert()插入时迭代器失效刨析 5.对erase()数据删除时迭代器失效刨析 一.vector底层实现机制刨析 通过分析 vector 容器的源代码不难发现,它就是使用 3 个迭代器(可以理解成指针)来表示的: 其中statrt指向vector 容器对象的起始字节位置: finish指
-
C语言数据结构进阶之栈和队列的实现
目录 栈的实现: 一.栈的概念和性质 二.栈的实现思路 三.栈的相关变量内存布局图 四.栈的初始化和销毁 五.栈的接口实现: 1.入栈 2.出栈 3.获取栈顶的数据 4.获取栈的元素个数 5.判断栈是否为空 队列的实现: 一.队列的概念和性质 二.队列的实现思路 三.队列相关变量的内存布局图 四.队列的初始化和销毁 五.队列的接口实现: 1. 入数据 2.出数据 3.取队头数据 4.取队尾数据 5.获取队列元素个数 6.判断队列是否为空 总结 栈的实现: 一.栈的概念和性质 栈(stack)又名
-
使用C语言实现vector动态数组的实例分享
下面是做项目时实现的一个动态数组,先后加入了好几个之后的项目,下面晒下代码. 头文件: # ifndef __CVECTOR_H__ # define __CVECTOR_H__ # define MIN_LEN 256 # define CVEFAILED -1 # define CVESUCCESS 0 # define CVEPUSHBACK 1 # define CVEPOPBACK 2 # define CVEINSERT 3 # define CVERM 4 # define EXP
-
C语言编程数据结构线性表之顺序表和链表原理分析
目录 线性表的定义和特点 线性结构的特点 线性表 顺序存储 顺序表的元素类型定义 顺序表的增删查改 初始化顺序表 扩容顺序表 尾插法增加元素 头插法 任意位置删除 任意位置添加 线性表的链式存储 数据域与指针域 初始化链表 尾插法增加链表结点 头插法添加链表结点 打印链表 任意位置的删除 双向链表 测试双向链表(主函数) 初始化双向链表 头插法插入元素 尾插法插入元素 尾删法删除结点 头删法删除结点 doubly-Linked list.c文件 doubly-Linkedlist.h 线性表的定
-
C语言数据结构之复杂链表的拷贝
题目: 给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点. 构造这个链表的 深拷贝. 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值.新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态.复制链表中的指针都不应指向原链表中的节点 . 例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y
-
C语言数据结构之使用链表模拟栈的实例
C语言数据结构之使用链表模拟栈的实例 以下是"使用链表模拟栈"的简单示例: 1. 用C语言实现的版本 #include<stdio.h> #include<stdlib.h> typedef char datatype; typedef struct node{ datatype data; struct node *next; } stack; stack* m_stack = NULL; /* 创建链表,从表头插入新元素 */ void creat(void
-
C语言数据结构之单链表的实现
目录 一.为什么使用链表 二.链表的概念 三.链表的实现 3.1 创建链表前须知 3.2 定义结构体 3.3 申请一个节点 3.4 链表的头插 3.5 链表的尾插 3.6 链表的尾删 3.7 链表的头删 3.8 寻找某节点 3.9 在指定节点前插入节点 3.10 删除指定节点前的节点 3.11 链表的销毁 一.为什么使用链表 在学习链表以前,我们存储数据用的方式就是数组.使用数组的好处就是便于查找数据,但缺点也很明显. 使用前需声明数组的长度,一旦声明长度就不能更改 插入和删除操作需要移动大量的
-
C语言数据结构之单链表与双链表的增删改查操作实现
目录 前言 单链表的增删改查 定义结构体以及初始化 增加结点 删除结点 查找修改结点 移除结点 最终效果 双链表的基本操作 初始化建表 遍历双链表 指定位置插入结点 指定位置删除结点 查找结点位置 最终效果 结语 前言 上篇博客分享了创建链表传入二级指针的细节,那么今天就分享几个c语言课程实践设计吧.这些程序设计搞懂了的话相当于链表的基础知识牢牢掌握了,那么再应对复杂的链表类的题也就能慢慢钻研了.学习是一个积累的过程,想要游刃有余就得勤学苦练! 单链表的增删改查 (1)项目需求 构造带有头结点的
-
C语言数据结构之单链表存储详解
目录 1.定义一个链表结点 2.初始化单链表 3.输出链表数据 4.完整代码 如果说,顺序表的所占用的内存空间是连续的,那么链表则是随机分配的不连续的,那么为了使随机分散的内存空间串联在一起形成一种前后相连的关系,指针则起到了关键性作用. 单链表的基本结构: 头指针:永远指向链表第一个节点的位置. 头结点:不存任何数据的空节点,通常作为链表的第一个节点.对于链表来说,头节点不是必须的,它的作用只是为了方便解决某些实际问题. 首元结点:首个带有元素的结点. 其他结点:链表中其他的节点. 1.定义一
-
C语言数据结构之单链表操作详解
目录 1.插入操作 2.删除操作 3.查找操作 4.修改操作 5.完整代码 1.插入操作 (1)创建一个新的要插入的结点 (2)将新结点的 next 指针指向插入位置后的结点 (3)将插入位置前的节点指针 next 指向新的结点 注意:步骤(2)(3)的顺序不能颠倒,否则会导致插入位置后的部分链表丢失. 插入位置一共分三种,分别是头部插入.中间插入和尾部插入. 如图: 代码: link* insertElem(link* p,int elem,int pos){ link* temp = p;/
-
Go语言数据结构之单链表的实例详解
目录 任意类型的数据域 实例01 快慢指针 实例02 反转链表 实例03 实例04 交换节点 实例05 任意类型的数据域 之前的链表定义数据域都是整型int,如果需要不同类型的数据就要用到 interface{}. 空接口 interface{} 对于描述起不到任何的作用(因为它不包含任何的method),但interface{}在需要存储任意类型的数值的时候相当有用,因为它可以存储任意类型的数值. 一个函数把interface{}作为参数,那么它可以接受任意类型的值作为参数:如果一个函数返回i
-
Go 语言数据结构之双链表学习教程
目录 双链表 创建节点 双链表遍历 扩展功能 链表长度 插入 删除 反转双链表 总结 双链表 双链表 (Doubly Linked List),每个节点持有一个指向列表前一个元素的指针,以及指向下一个元素的指针. 双向链表的节点中包含 3 个字段: 数据域 Value 一个 Next 指针指向双链表中的下一个节点 一个 Prev 指针,指向双链表中的前一个节点 结构体如下: type Node struct { Prev *Node Value int Next *Node } 实际应用: 音乐
-
C语言数据结构之单链表的查找和建立
目录 单链表的查找 按位查找 按值查找 单链表的建立 尾插法 头插法建立单链表 单链表的查找 其实在单链表的插入和删除中,我们已经使用过单链表的查找方法,因为插入和删除的前提都是先找到对应的结点,所以这里就不再多解释 按位查找 GetElem(L, i):按位查找操作.获取表 L 中第 i 个位置的元素的值 //按位查找 LNode * GetElem(LinkList L, int i) { if (i < 0) return false; LNode *p; //指针p指向当前扫描到的结点