利用C#实现最基本的小说爬虫示例代码
前言
作为一个新手,最近在学习C#,自己折腾弄了个简单的小说爬虫,实现了把小说内容爬下来写入txt,还只能爬指定网站。
第一次搞爬虫,涉及到了网络协议,正则表达式,弄得手忙脚乱跑起来效率还差劲,慢慢改吧。下面话不多说了,来一起看看详细的介绍吧。
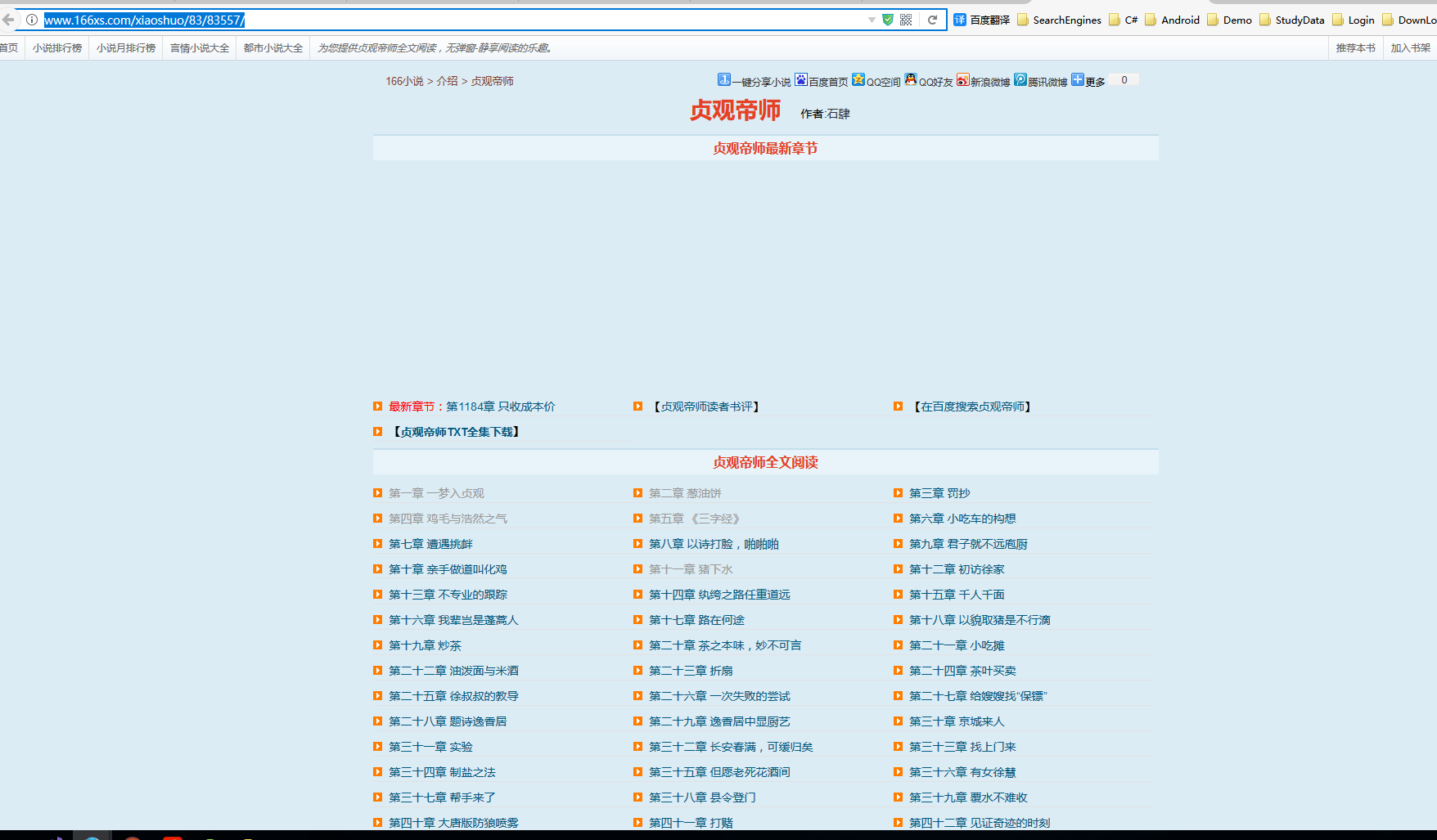
爬的目标:http://www.166xs.com/xiaoshuo/83/83557/
一、先写HttpWebRequest把网站扒下来
这里有几个坑,大概说下:
第一个就是记得弄个代理IP爬网站,第一次忘了弄代理然后ip就被封了。。。。。
第二个就是要判断网页是否压缩,第一次没弄结果各种转码gbk utf都是乱码。后面解压就好了。
/// <summary>
/// 抓取网页并转码
/// </summary>
/// <param name="url"></param>
/// <param name="post_parament"></param>
/// <returns></returns>
public string HttpGet(string url, string post_parament)
{
string html;
HttpWebRequest Web_Request = (HttpWebRequest)WebRequest.Create(url);
Web_Request.Timeout = 30000;
Web_Request.Method = "GET";
Web_Request.UserAgent = "Mozilla/4.0";
Web_Request.Headers.Add("Accept-Encoding", "gzip, deflate");
//Web_Request.Credentials = CredentialCache.DefaultCredentials;
//设置代理属性WebProxy-------------------------------------------------
WebProxy proxy = new WebProxy("111.13.7.120", 80);
//在发起HTTP请求前将proxy赋值给HttpWebRequest的Proxy属性
Web_Request.Proxy = proxy;
HttpWebResponse Web_Response = (HttpWebResponse)Web_Request.GetResponse();
if (Web_Response.ContentEncoding.ToLower() == "gzip") // 如果使用了GZip则先解压
{
using (Stream Stream_Receive = Web_Response.GetResponseStream())
{
using (var Zip_Stream = new GZipStream(Stream_Receive, CompressionMode.Decompress))
{
using (StreamReader Stream_Reader = new StreamReader(Zip_Stream, Encoding.Default))
{
html = Stream_Reader.ReadToEnd();
}
}
}
}
else
{
using (Stream Stream_Receive = Web_Response.GetResponseStream())
{
using (StreamReader Stream_Reader = new StreamReader(Stream_Receive, Encoding.Default))
{
html = Stream_Reader.ReadToEnd();
}
}
}
return html;
}
二、下面就是用正则处理内容了,由于正则表达式不熟悉所以重复动作太多。
1.先获取网页内容
IWebHttpRepository webHttpRepository = new WebHttpRepository(); string html = webHttpRepository.HttpGet(Url_Txt.Text, "");
2.获取书名和文章列表
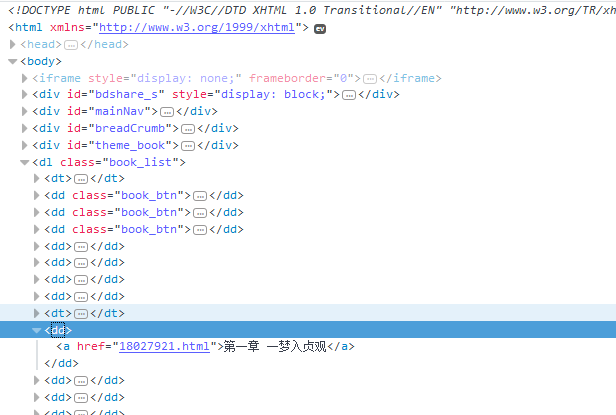
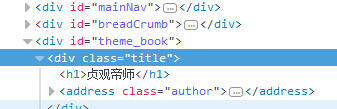
书名
文章列表
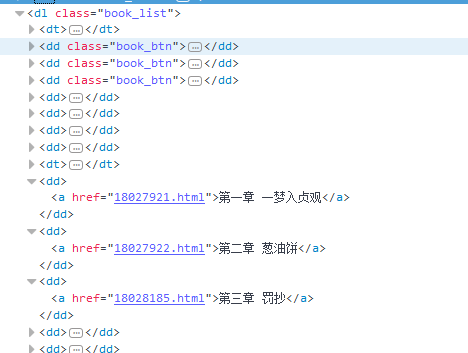
string Novel_Name = Regex.Match(html, @"(?<=<h1>)([\S\s]*?)(?=</h1>)").Value; //获取书名 Regex Regex_Menu = new Regex(@"(?is)(?<=<dl class=""book_list"">).+?(?=</dl>)"); string Result_Menu = Regex_Menu.Match(html).Value; //获取列表内容 Regex Regex_List = new Regex(@"(?is)(?<=<dd>).+?(?=</dd>)"); var Result_List = Regex_List.Matches(Result_Menu); //获取列表集合
3.因为章节列表前面有多余的<dd>,所以要剔除
int i = 0; //计数
string Menu_Content = ""; //所有章节
foreach (var x in Result_List)
{
if (i < 4)
{
//前面五个都不是章节列表,所以剔除
}
else
{
Menu_Content += x.ToString();
}
i++;
}
4.然后获取<a>的href和innerHTML,然后遍历访问获得内容和章节名称并处理,然后写入txt
Regex Regex_Href = new Regex(@"(?is)<a[^>]*?href=(['""]?)(?<url>[^'""\s>]+)\1[^>]*>(?<text>(?:(?!</?a\b).)*)</a>");
MatchCollection Result_Match_List = Regex_Href.Matches(Menu_Content); //获取href链接和a标签 innerHTML
string Novel_Path = Directory.GetCurrentDirectory() + "\\Novel\\" + Novel_Name + ".txt"; //小说地址
File.Create(Novel_Path).Close();
StreamWriter Write_Content = new StreamWriter(Novel_Path);
foreach (Match Result_Single in Result_Match_List)
{
string Url_Text = Result_Single.Groups["url"].Value;
string Content_Text = Result_Single.Groups["text"].Value;
string Content_Html = webHttpRepository.HttpGet(Url_Txt.Text + Url_Text, "");//获取内容页
Regex Rege_Content = new Regex(@"(?is)(?<=<p class=""Book_Text"">).+?(?=</p>)");
string Result_Content = Rege_Content.Match(Content_Html).Value; //获取文章内容
Regex Regex_Main = new Regex(@"( )(.*)");
string Rsult_Main = Regex_Main.Match(Result_Content).Value; //正文
string Screen_Content = Rsult_Main.Replace(" ", "").Replace("<br />", "\r\n");
Write_Content.WriteLine(Content_Text + "\r\n");//写入标题
Write_Content.WriteLine(Screen_Content);//写入内容
}
Write_Content.Dispose();
Write_Content.Close();
MessageBox.Show(Novel_Name+".txt 创建成功!");
System.Diagnostics.Process.Start(Directory.GetCurrentDirectory() + \\Novel\\);
三、小说写入成功

总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对我们的支持。
相关推荐
-
C#中Socket与Unity相结合示例代码
前言 初步接触了Socket,现使其与Unity相结合,做成一个简单的客户端之间可以互相发送消息的一个Test.下面话不多说了,来一起看看详细的介绍吧. 方法如下: 首先,是服务端的代码. 创建一个连接池,用于存储客户端的数量. using System; using System.Net; using System.Net.Sockets; using System.Collections; using System.Collections.Generic; namespace Server
-
C#实现基于ffmpeg加虹软的人脸识别的示例
关于人脸识别 目前的人脸识别已经相对成熟,有各种收费免费的商业方案和开源方案,其中OpenCV很早就支持了人脸识别,在我选择人脸识别开发库时,也横向对比了三种库,包括在线识别的百度.开源的OpenCV和商业库虹软(中小型规模免费). 百度的人脸识别,才上线不久,文档不太完善,之前联系百度,官方也给了我基于Android的Example,但是不太符合我的需求,一是照片需要上传至百度服务器(这个是最大的问题),其次,人脸的定位需要自行去实现(捕获到人脸后上传进行识别). OpenCV很早以前就用过,
-

C# 使用Free Spire.Presentation 实现对PPT插入、编辑、删除表格
现代学习和办公当中,经常会接触到对表格的运用,像各种单据.报表.账户等等.在PPT演示文稿中同样不可避免的应用到各种数据表格.对于在PPT中插入表格,我发现了一个新方法,不过我用到了一款免费的.NET组件--Free Spire.Presentation,在C#中添加该产品DLL文件,可以简单快速地实现对演示文稿的表格插入.编辑和删除等操作.有需要的话可以在下面的网址下载:https://www.e-iceblue.cn/Downloads/Free-Spire-Presentation-NET
-
C#中可枚举类型详解
枚举是迭代一个集合中的数据项的过程. 我们经常使用的大多数集合实际上都已经实现了枚举的接口IEnumerable和IEnumerator接口,这样才能使用foreach迭代,有些是含有某种抽象了枚举细节的接口:ArrayList类型有索引,BitArray有Get方法,哈希表和字典有键和值..........其实他们都已经实现了IEnumerable和IEnumerator接口.所以一切的集合和数组都可以用IEnumerable或者IEnumerable<T>接口来定义. IEnumerabl
-
C#简单爬虫案例分享
本文实例为大家分享了C#简单爬虫案例,供大家参考,具体内容如下 using System; using System.Collections.Generic; using System.Linq; using System.Net; using System.Text; using System.Text.RegularExpressions; using System.Threading.Tasks; namespace ConsoleApplication1 { class Program
-
C# 利用代理爬虫网页的实现方法
C# 利用代理爬虫网页 实现代码: // yanggang@mimvp.com // http://proxy.mimvp.com // 2015-11-09 using System; using System.IO; using System.Net; using System.Text; namespace ConsoleApplication1 { class Program { public static void Main(string[] args) { System.Net.We
-
C#使用yield关键字构建迭代器详解
以前,如果我们希望构建支持foreach枚举的自定义集合,只能实现IEnumerable接口(可能还有IEnumerator()),返回值还必须是IEnumerator类型,除此之外还可以通过迭代器来使用构建foreach循环的类型,详细见下链接. 代码 public class Car { //内部状态数据 public int CurentSpeed; public int MaxSpeed; public string name; //汽车能不能用 private bool carIsde
-
利用C#实现最基本的小说爬虫示例代码
前言 作为一个新手,最近在学习C#,自己折腾弄了个简单的小说爬虫,实现了把小说内容爬下来写入txt,还只能爬指定网站. 第一次搞爬虫,涉及到了网络协议,正则表达式,弄得手忙脚乱跑起来效率还差劲,慢慢改吧.下面话不多说了,来一起看看详细的介绍吧. 爬的目标:http://www.166xs.com/xiaoshuo/83/83557/ 一.先写HttpWebRequest把网站扒下来 这里有几个坑,大概说下: 第一个就是记得弄个代理IP爬网站,第一次忘了弄代理然后ip就被封了..... 第二个就是
-
python+selenium+chromedriver实现爬虫示例代码
下载好所需程序 1.Selenium简介 Selenium是一个用于Web应用程序测试的工具,直接运行在浏览器中,就像真正的用户在操作一样. 2.Selenium安装 方法一:在Windows命令行(cmd)输入pip install selenium即可自动安装,安装完成后,输入pip show selenium可查看当前的版本 方法二:直接下载selenium包: selenium下载网址 Pychome安装selenium如果出现无法安装,参考以下博客 解决Pycharm无法使用已经安装S
-
利用Selenium添加cookie实现自动登录的示例代码(fofa)
介绍 Selenium可以模拟浏览器进行自动化操作,但一些网站需要进行登录才能进行一些操作,比起输入账号密码,cookie是更加方便的.而且fofa首先登录邮箱账号时获得的cookie并不是fofa的cookie,因此我们直接选择利用fofa的cookie进行自动登录.但是selenium需要先打开一个网站才会加载进去cookies,因此我们需要将cookies写在代码中,加载进去 扩展 get_cookies(): 获得所有cookie信息. get_cookie(name): 返回字典的ke
-
利用Go语言实现流量回放工具的示例代码
目录 前言 goreplay介绍与安装 使用示例 流量放大.缩小 流量写入到ElastichSearch goreplay基本实现原理 总结 前言 哈喽,大家好,我是asong. 今天给大家推荐一款使用Go语言编写的流量回放工具 -- goreplay:工作中你一定遇到过需要在服务器上抓包的场景,有了这个工具就可以助你一臂之力,goreplay的功能十分强大,支持流量的放大.缩小,并且集成了ElasticSearch,将流量存入ES进行实时分析: 废话不多,我们接下来来看一看这个工具: gore
-
Python利用tkinter实现一个简易番茄钟的示例代码
之前捣鼓树莓派时,要求做一个番茄钟,但最后就只是搞成一个与树莓派没啥关系的py程序,虽然简陋,但就此记录一下自学的成果. 程序实现番茄工作法:25分钟工作,5分钟休息 完成一次番茄工作时间,就记一个番茄 (不把休息时间算在里面,有时候自己都不想休息,好吧,是我不知道怎么把番茄工作时间和休息时间联系在一块来记录番茄个数) 这个程序倒计时显示的是从24:59开始,是因为按的时候算是1秒? 运行界面如下: 自己感觉这个界面还行,朴素中带着点高级感 代码参考了一些大佬写的番茄钟程序,特别是那个倒计时的实
-
利用JavaScript实现绘制2023新年烟花的示例代码
目录 前言 烟花效果展示 使用教程 查看源码 HTML代码 CSS代码 JavaScript 新年祝福 前言 大家过年好!新春佳节,在这个充满喜悦的日子里,愿新年的钟声带给你一份希望和期待,我相信,时空的距离不能阻隔你我,我的祝福永远在你身边. 祝愿朋友,财源滚滚,吉祥高照,鸿运当头,幸福环绕,万事顺心,笑口常开. 在这喜庆的日子里,我给大家分享一个烟花代码,代码下载在使用教程部分,希望大家都能开开心心过大年! 烟花效果展示 烟花样式可以自定义选择,背景音乐选择十分真实的仿烟花声.当你把代码打包
-
利用Java快速查找21位花朵数示例代码
前言 本文主要给大家介绍了关于利用Java快速查找21位花朵数的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 以前备赛的时候遇到的算法题,求所有21位花朵数,分享一下,供大家参考,效率已经很高了. 示例代码 package com.jianggujin; import java.math.BigInteger; import java.util.ArrayList; import java.util.List; /** * 水仙花数 * * @author jian
-
利用java生成二维码工具类示例代码
二维码介绍 二维条形码最早发明于日本,它是用某种特定的几何图形按一定规律在平面(二维方向上)分布的黑白相间的图形记录数据符号信息的,在代码编制上巧妙地利用构成计算机内部逻辑基础的"0"."1"比特流的概念,使用若干个与二进制相对应的几何形体来表示文字数值信息,通过图象输入设备或光电扫描设备自动识读以实现信息自动处理. 如下为java生成二维码工具类,可以选择生成文件,或者直接在页面生成,话不多说了,来一起看看详细的示例代码吧. 示例代码 import java.aw
-
利用D3.js实现最简单的柱状图示例代码
首先把效果图放出来: 具备了一个柱状图的基础元素:柱形,坐标轴,刻度,数值等. 不得不说,d3.js比直接用的echarts更麻烦,但是确实更自由. 来看看如何实现吧. //确定画布的大小 var width = 400; var height = 400; //在 body 里添加一个 SVG 画布 var svg = d3.select("body") .append("svg") .attr("width", width) .attr(&q
-
SQL利用Function创建长整形的唯一ID示例代码
前言 在设计表的时候考虑主键的数据类型是长整形还是字符串,最简单的方式当然是newid(),但这也有个问题,就是主键长度过长(36个字),数据量一多,必然会影响数据库操作的效率,而且大大增加了数据文件和索引文件所占用的空间.而且,newid返回的字符串是随机的,查询结果不能保证按保存顺序返回.这对于有顺序要求的系统来说,需要额外增加顺序列来进行排序,这也导致查询语句更加复杂.这也是主要放弃newid作为主键的主要原因.因此考虑用长整形来作数据表主键的数据类型. 实现方法 一开始在C#等面向对像语