Python字典和列表性能之间的比较
Python列表和字典
- 前面我们了解了 “大O表示法” 以及对不同的算法的评估,下面来讨论下 Python 两种内置数据类型有关的各种操作的大O数量级:列表 list 和字典dict。
- 这是 Python 中两种非常重要的数据类型,后面会用来实现各种数据结构,通过运行试验来估计其各种操作运行时间数量级。
对比 list 和 dict 操作如下:

List列表数据类型常用操作性能:
最常用的是:按索引取值和赋值(v=a[i],a[i]=v),由于列表的随机访问特性,这两个操作执行时间与列表大小无关,均为O(1)。
另一个是列表增长,可以选择 append() 和 “+”:lst.append(v),执行时间是O(1);lst= lst+ [v],执行时间是O(n+k),其中 k 是被加的列表长度,选择哪个方法来操作列表,也决定了程序的性能。
测试 4 种生成 n 个整数列表的方法:

创建一个 Timer 对象,指定需要反复运行的语句和只需要运行一次的"安装语句"。
然后调用这个对象的 timeit 方法,指定反复运行多少次。
# Timer(stmt="pass", setup="pass") # 这边只介绍两个参数
# stmt:statement的缩写,就是要测试的语句,要执行的对象
# setup:导入被执行的对象(就和run代码前,需要导入包一个道理) 在主程序命名空间中 导入
time1 = Timer("test1()", "from __main__ import test1")
print("concat:{} seconds".format(time1.timeit(1000)))
time2 = Timer("test2()", "from __main__ import test2")
print("append:{} seconds".format(time2.timeit(1000)))
time3 = Timer("test3()", "from __main__ import test3")
print("comprehension:{} seconds".format(time3.timeit(1000)))
time4 = Timer("test4()", "from __main__ import test4")
print("list range:{} seconds".format(time4.timeit(1000))
结果如下:
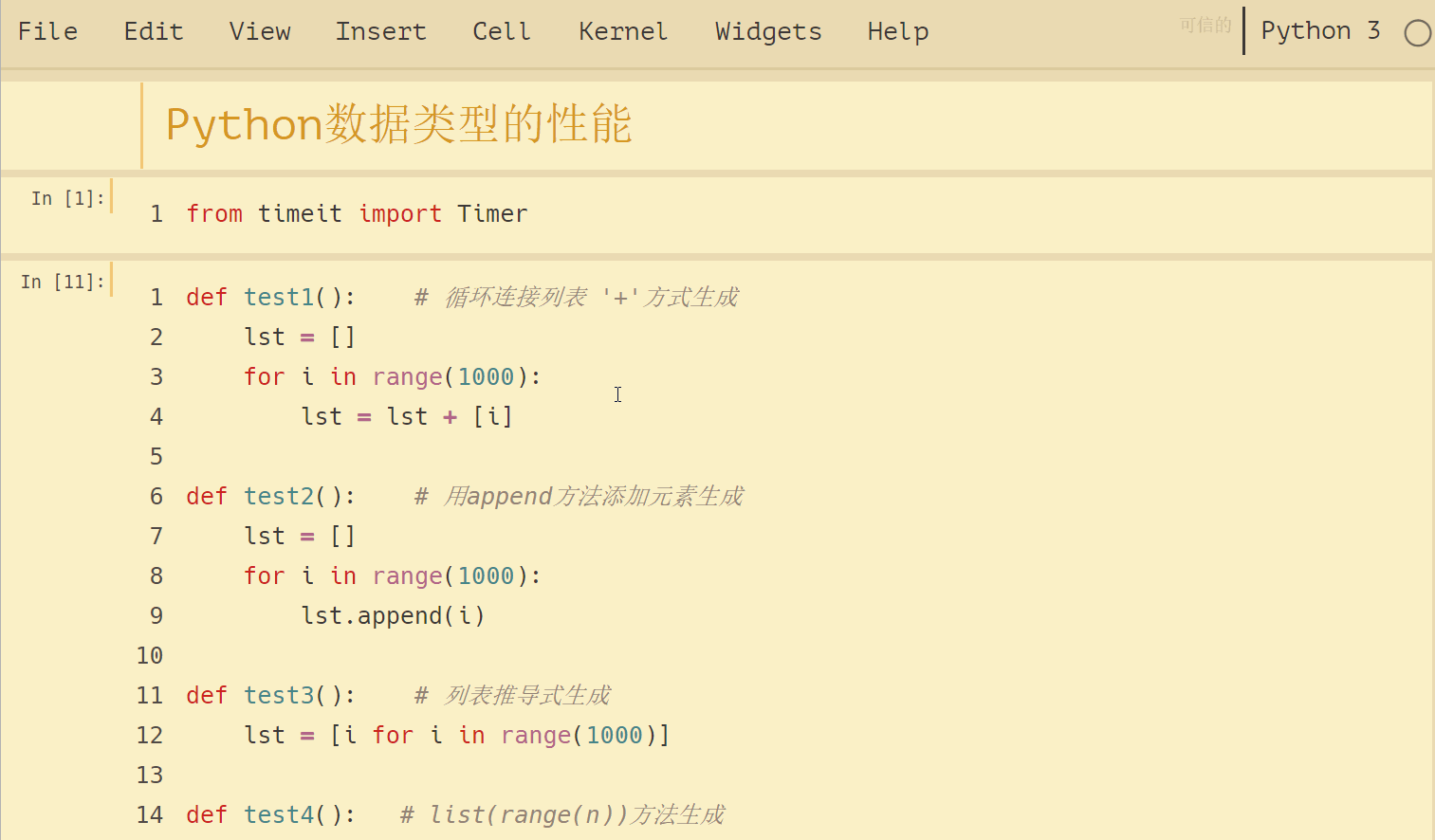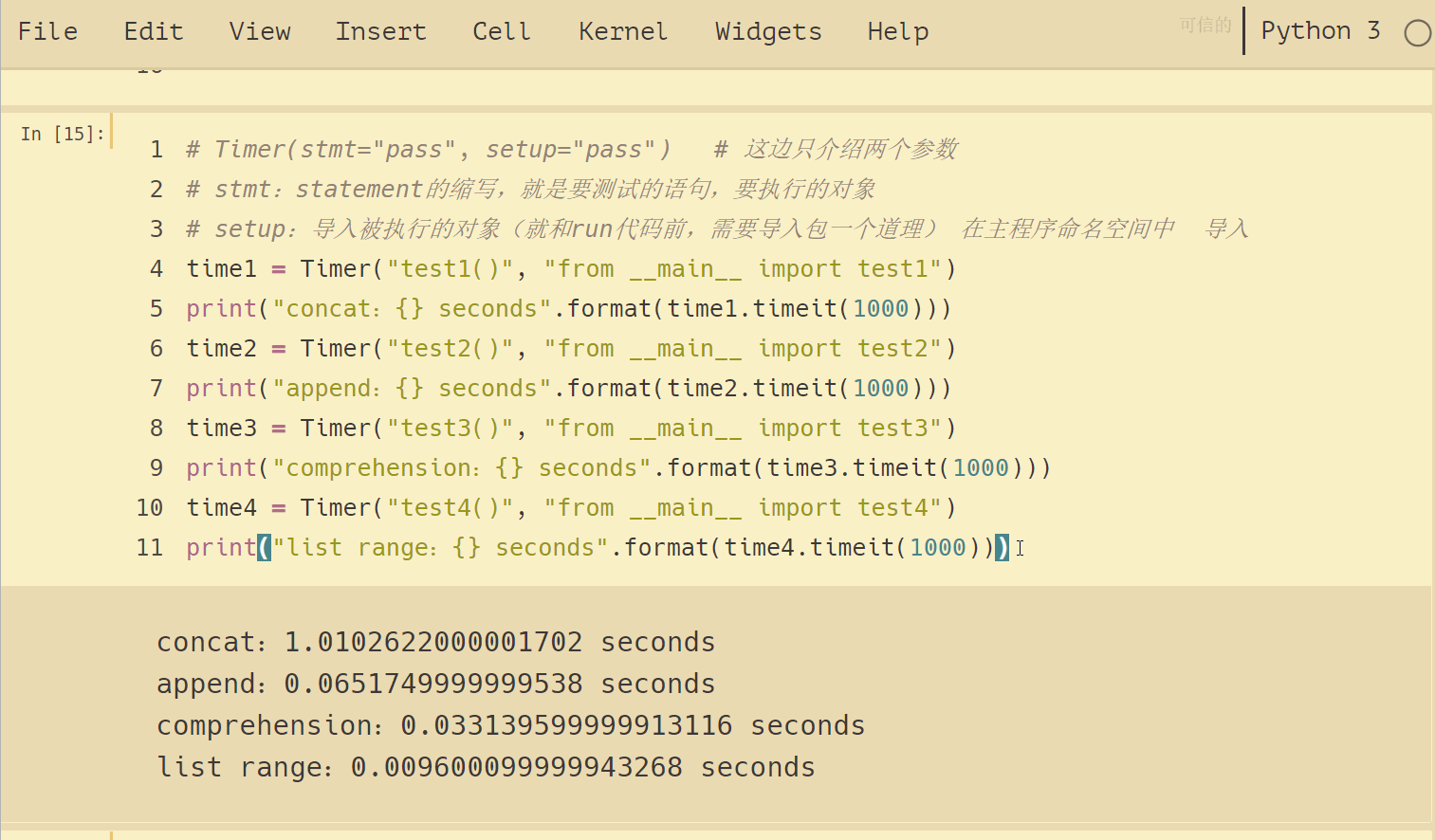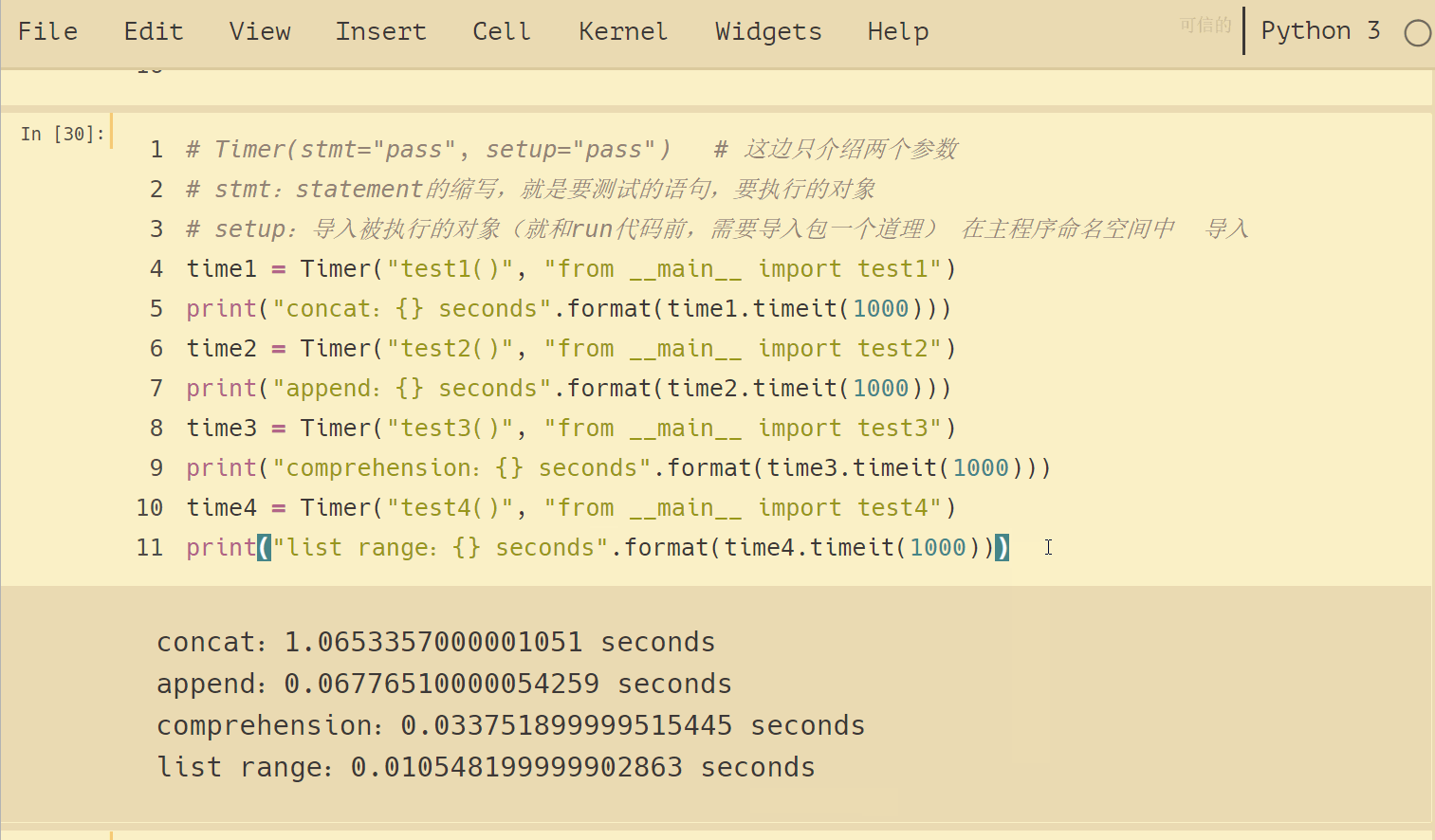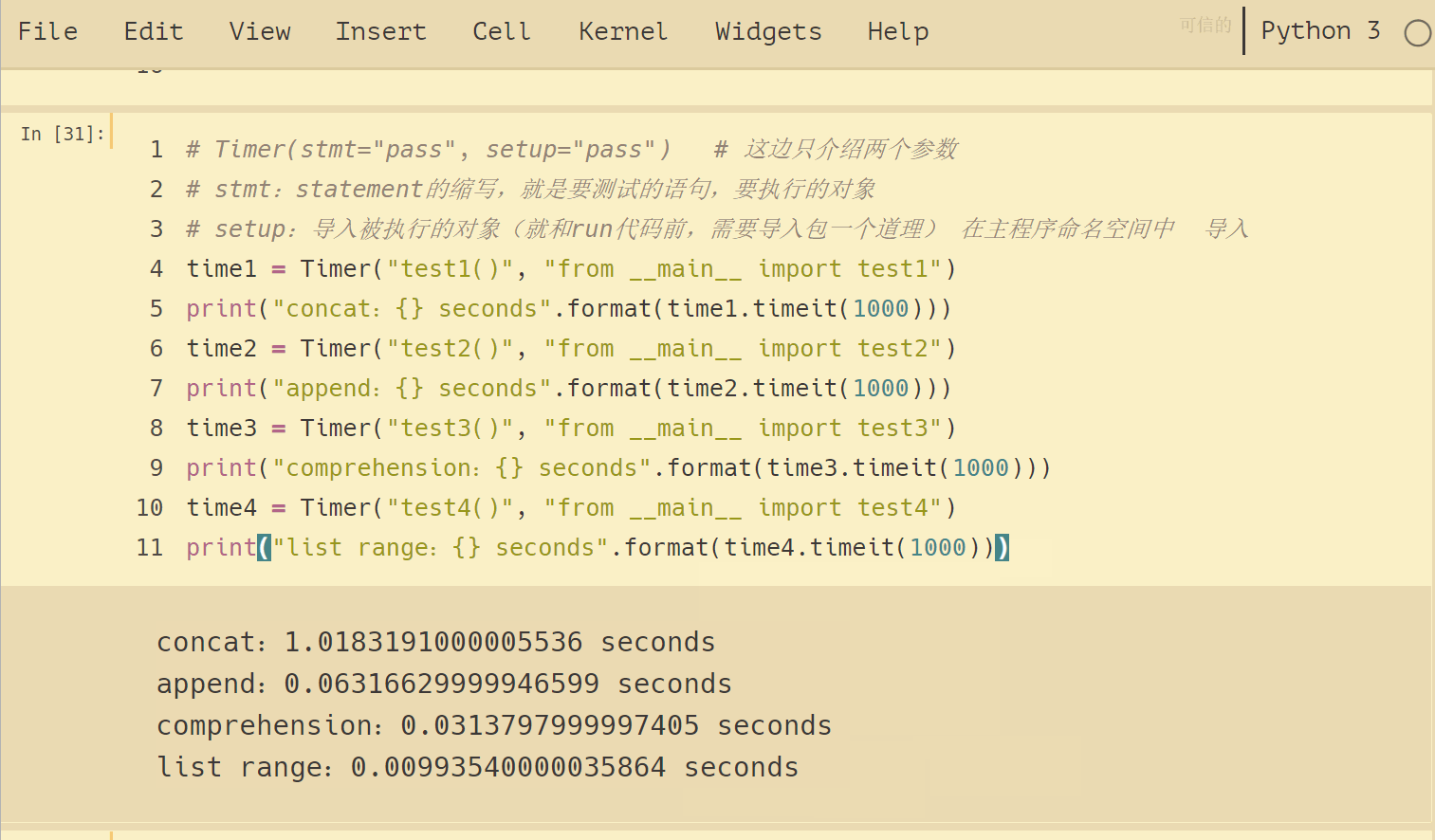
可以看到,4种方法运行时间差别挺大的,列表连接(concat)最慢,List range最快,速度相差近 100 倍。append要比 concat 快得多。另外,我们注意到列表推导式速度大约是 append 两倍的样子。
总结列表基本操作的大 O 数量级:
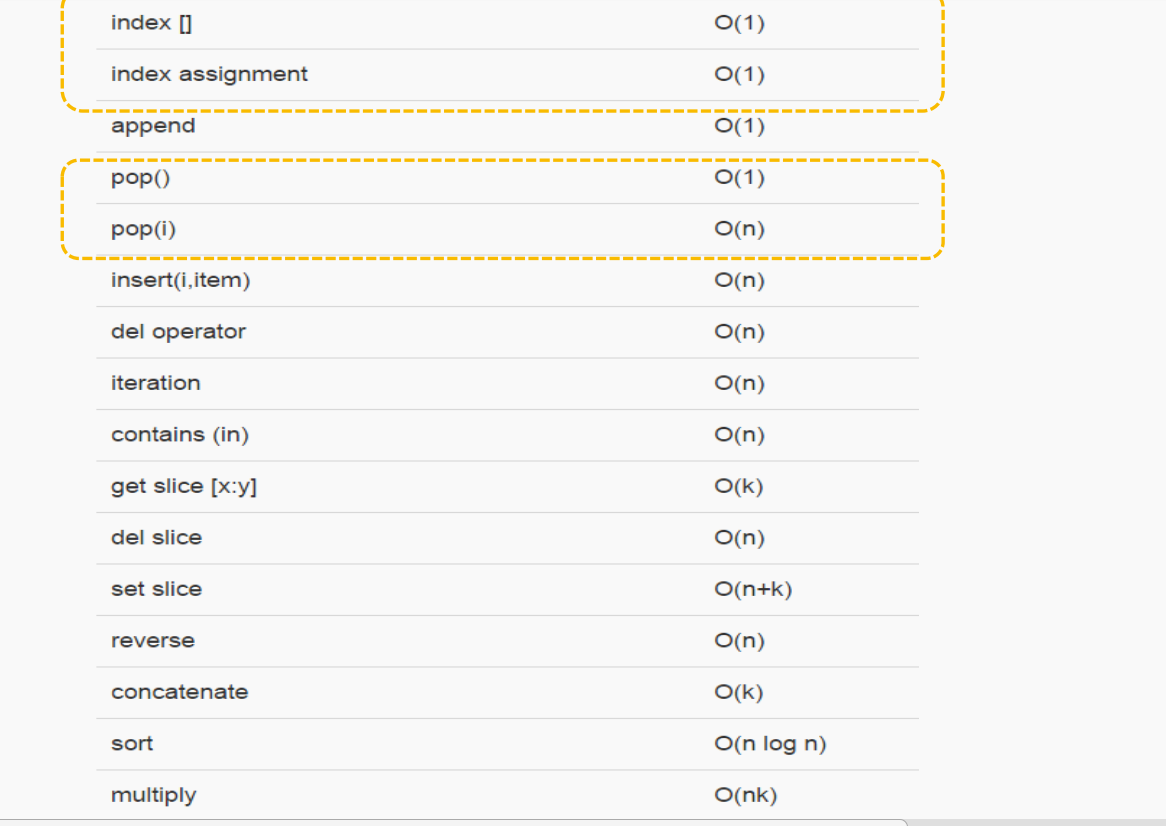
我们注意到 pop 这个操作,pop()是从列表末尾移除元素,时间复杂度为O(1);pop(i)从列表中部移除元素,时间复杂度为O(n)。
原因在于 Python 所选择的实现方法,从中部移除元素的话,要把移除元素后面的元素,全部向前挪位复制一遍,这个看起来有点笨拙
但这种实现方法能够保证列表按索引取值和赋值的操作很快,达到O(1)。这也算是一种对常用和不常用操作的折中方案。
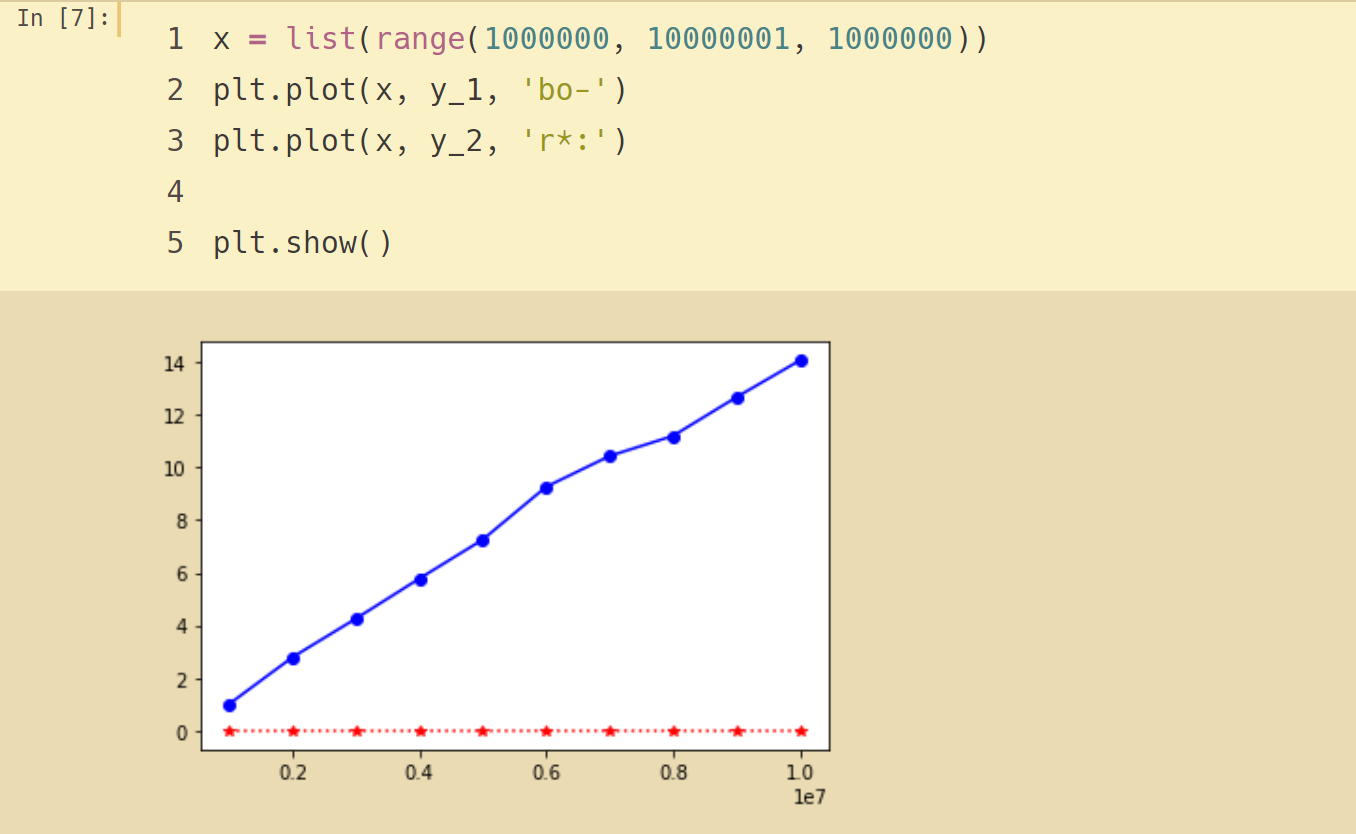
list.pop()的计时试验,通过改变列表的大小来测试两个操作的增长趋势:
import timeit
pop_first = timeit.Timer("x.pop(0)", "from __main__ import x")
pop_end = timeit.Timer("x.pop()", "from __main__ import x")
print("pop(0) pop()")
y_1 = []
y_2 = []
for i in range(1000000, 10000001, 1000000):
x = list(range(i))
p_e = pop_end.timeit(number=1000)
x = list(range(i))
p_f = pop_first.timeit(number=1000)
print("{:.6f} {:.6f}".format(p_f, p_e))
y_1.append(p_f)
y_2.append(p_e)
结果如下:

将试验结果可视化,可以看出增长趋势:pop()是平坦的常数,pop(0)是线性增长的趋势。
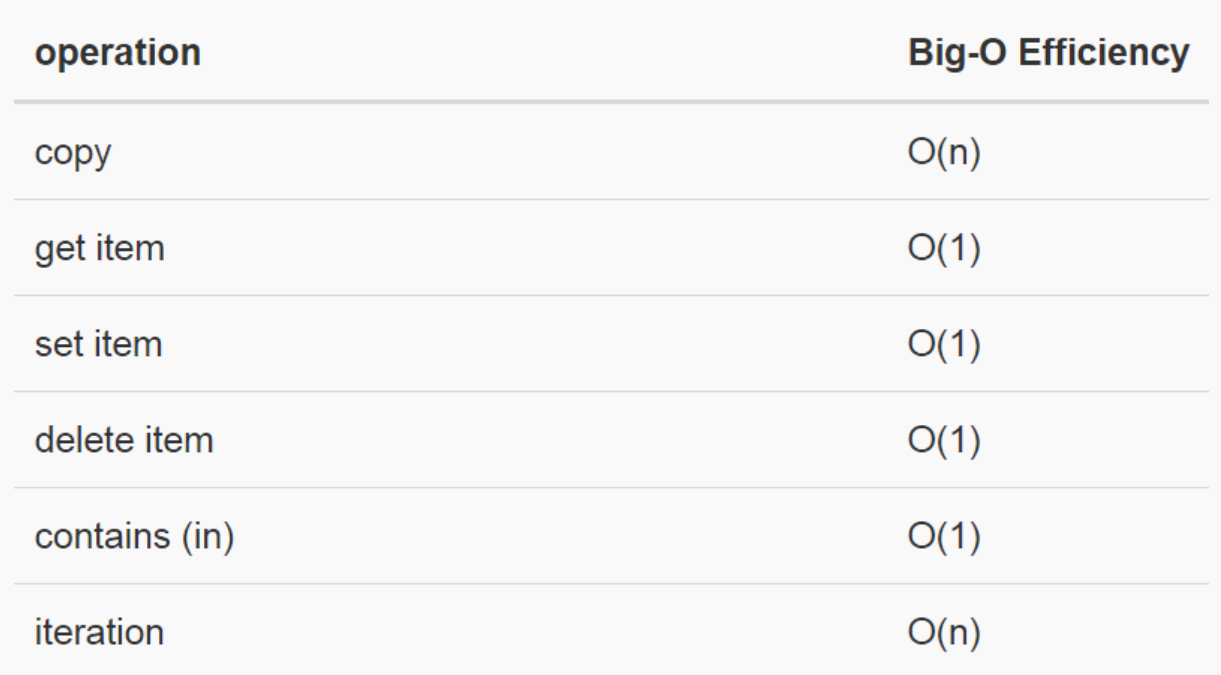
字典与列表不同,是根据键值(key)找到数据项,而列表是根据索引(index)。最常用的取值和赋值,其性能均为O(1)。另一个重要操作contains(in)是判断字典中是否存在某个键值(key),这个性能也是O(1)。
做一个性能测试试验来验证 list 中检索一个值,以及 dict 中检索一个值的用时对比,生成包含连续值的 list 和包含连续键值 key 的
dict,用随机数来检验操作符 in 的耗时。
import timeit
import random
y_1 = []
y_2 = []
print("lst_time dict_time")
for i in range(10000, 1000001, 25000):
t = timeit.Timer("random.randrange(%d) in x" % i, "from __main__ import random, x")
x = list(range(i))
lst_time = t.timeit(number=1000)
x = {j: 'k' for j in range(i)}
dict_time = t.timeit(number=1000)
print("{:.6f} {:.6f}".format(lst_time, dict_time))
y_1.append(lst_time)
y_2.append(dict_time)
结果如下:

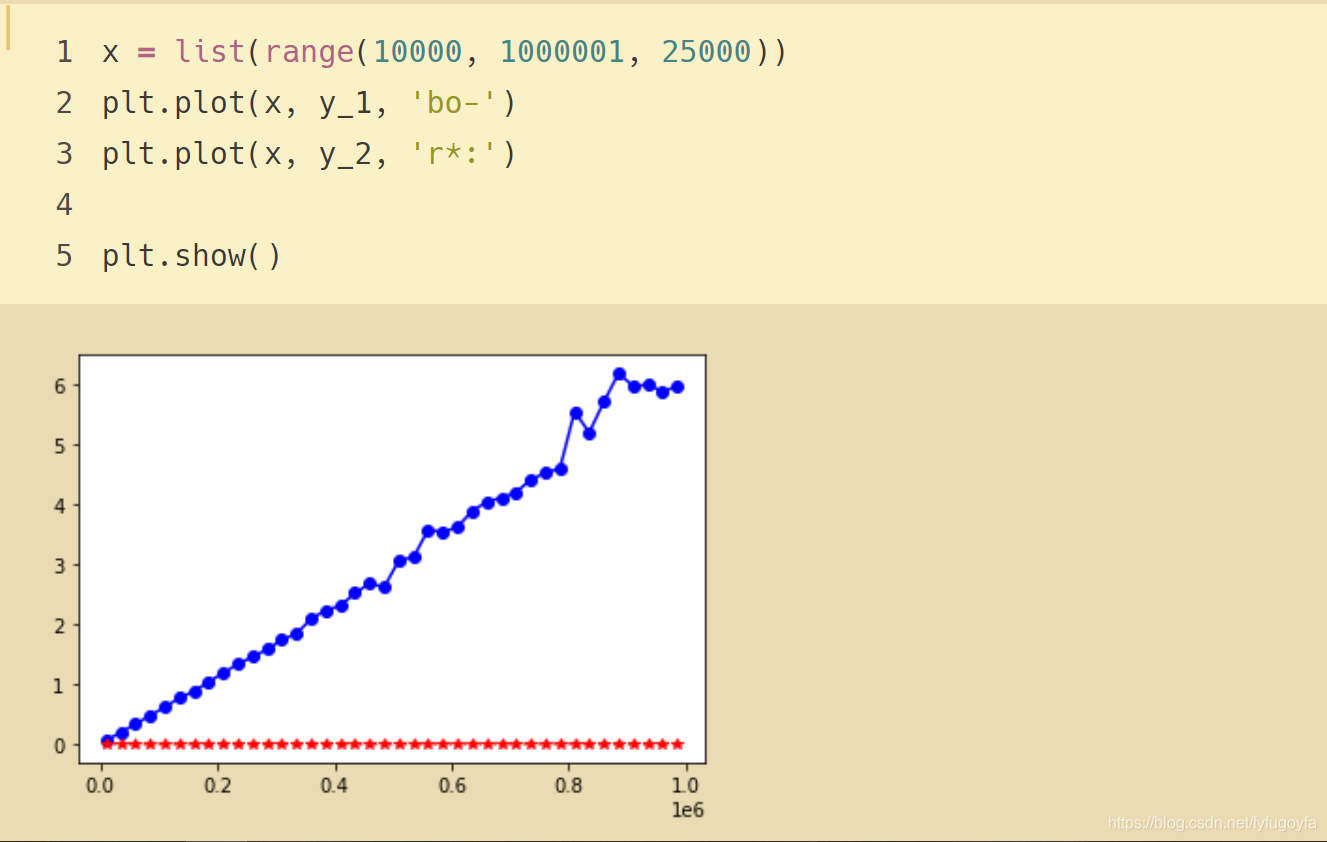
- 可见字典的执行时间与规模无关,是常数。
- 而列表的执行时间则会随着列表的规模加大而线性上升。
更多 Python 数据类型操作复杂度可以参考官方文档:
https://wiki.python.org/moin/TimeComplexity
到此这篇关于Python字典和列表性能之间的比较的文章就介绍到这了,更多相关Python列表和字典内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python 将列表里的字典元素合并为一个字典实例
我就废话不多说了,大家还是直接看代码吧~ def list_dict(list_data): dict_data = {} for i in list_data: key, = i value, = i.values() dict_data[key] = value return dict_data if __name__ == '__main__': list_data = [{'aa': 'aa'}, {'bb': 'bb'}, {'cc': 'cc'}, {'dd': 'dd'}] pri
-
python 实现让字典的value 成为列表
如果想让字典的VALUE成为字典,只有最开始让其成为列表,如下面程序中的b >>> b={} >>> b={1:['sdad']} >>> b {1: ['sdad']} >>> b[1].append('dada') >>> b {1: ['sdad', 'dada']} >>> c {0: 'dadsad'} >>> list(c[0]) ['d', 'a', 'd', 's'
-
python判断变量是否为int、字符串、列表、元组、字典的方法详解
在实际写程序中,经常要对变量类型进行判断,除了用type(变量)这种方法外,还可以用isinstance方法判断: a = 1 b = [1,2,3,4] c = (1,2,3,4) d = {'a':1, 'b':2, 'c':3} e = "abc" if isinstance(a,int): print ("a is int") else: print ("a is not int") if isinstance(b,list): prin
-
Python字典中的值为列表或字典的构造实例
1.值为列表的构造实例 dic = {} dic.setdefault(key,[]).append(value) *********示例如下****** >>dic.setdefault('a',[]).append(1) >>dic.setdefault('a',[]).append(2) >>dic >>{'a': [1, 2]} 2.值为字典的构造实例 dic = {} dic.setdefault(key,{})[value] =1 *******
-
python中for循环把字符串或者字典添加到列表的方法
python中如何for循环把字符串添加到列表? 实例: 1.单个字符串用for循环添加到列表中: # 把L1中的字符串添加到列表alist里面 L1 = 'MJlifeBlog' alist = [] # 可以用forin来迭代L1并保存值到x变量里头即可. # 接着在for循环里边用append方法即可把解析到的单个字符添加到列表了. for x in L1: alist.append(x) print(alist) 2.多个字符串用for循环添加到列表中: # 如果需要把多个字符串添加到列
-
python 字典套字典或列表的示例
文件f1 A 1 a A 1 b A 2 C B 2 a B 2 b 生成如下字典: tdict={'A':{1:['a','b'], 2:['C']}, 'B':{2:['a','b']} } In [22]: tdict={} In [23]: f=open('f1') In [24]: while True: ...: line=f.readline().strip() ...: if not line: ...: break ...: pos1=line.split()[0] ...:
-
python实现字典嵌套列表取值
如下所示: dict={'log_id': 5891599090191187877, 'result_num': 1, 'result': [{'probability': 0.9882395267486572, 'top': 205, 'height': 216, 'classname': 'Face', 'width': 191, 'left': 210}]} 访问dict的值: print(dict['log_id']) 访问dict下的result列表的值: print(dict['re
-

Python字符串、列表、元组、字典、集合的补充实例详解
本文实例讲述了Python字符串.列表.元组.字典.集合.分享给大家供大家参考,具体如下: 附加: python的很多编译器提供了代码补全功能,并且在填入参数时提供提示功能 字符串 1.常用函数: 字符串是不可变对象,字符串的方法都不会改变原字符串的数据 s=" hEllo world!\t " print("s.capitalize():",s.capitalize())#标题格式化 print("s.center(20,'-'):",s.ce
-
Python字典和列表性能之间的比较
Python列表和字典 前面我们了解了 "大O表示法" 以及对不同的算法的评估,下面来讨论下 Python 两种内置数据类型有关的各种操作的大O数量级:列表 list 和字典dict. 这是 Python 中两种非常重要的数据类型,后面会用来实现各种数据结构,通过运行试验来估计其各种操作运行时间数量级. 对比 list 和 dict 操作如下: List列表数据类型常用操作性能: 最常用的是:按索引取值和赋值(v=a[i],a[i]=v),由于列表的随机访问特性,这两个操作执行时间与列
-
python 字典和列表嵌套用法详解
python中字典和列表的使用,在数据处理中应该是最常用的,这两个熟练后基本可以应付大部分场景了.不过网上的基础教程只告诉你列表.字典是什么,如何使用,很少做组合说明. 刚好工作中采集prometheus监控接口并做数据处理的时候,用了很多组合场景,列出几个做一些分享. 列表(List) 序列是Python中最基本的数据结构.序列中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推. 列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现
-
Python的字典和列表的使用中一些需要注意的地方
Python 中有三个非常好用的数据结构,列表,元组和字典, 元组是不可变的,列表可以保存任意类型的Python对象,并可以随意扩展没有大小限制, 字典是一个key-value的键值映射的类型,可以存放任何Python对象,可以嵌套字典, 值可以是字典元组或者字典 这里说是Python 字典和列表的陷阱不如说是Python的一些特性,如果不了解这些特性 就会引发一些难以寻找的bug 下面我们来介绍这些特性 Python中所有对列表和字典的使用仅仅是对原来对象的引用而不是创建一个新的对象 如下面代
-
Python创建空列表的字典2种方法详解
如果要在 Python 中创建键值是空列表的字典,有多种方法,但是各种方法之间是否由区别?需要作实验验证,并且分析产生的原因.本文针对两种方法做了实验和分析. 如果要在 Python 中创建一个键值都是列表的字典,类似下面这样,该怎么做? {1:[], 2:[], 3:[], 4:[]} 方法1,字典构造器 用 dict 构造器生成,构造(key,value)对 > key = [1, 2, 3, 4] > a = dict([(k,[]) for k in key]) > a {1:
-
python提取字典key列表的方法
本文实例讲述了python提取字典key列表的方法.分享给大家供大家参考.具体如下: 这段代码可以把字典的所有key输出为一个数组 d2 = {'spam': 2, 'ham': 1, 'eggs': 3} # make a dictionary print d2 # order is scrambled print d2.keys() # create a new list of my keys 希望本文所述对大家的Python程序设计有所帮助.
-
Python编程对列表中字典元素进行排序的方法详解
本文实例讲述了Python编程对列表中字典元素进行排序的方法.分享给大家供大家参考,具体如下: 内容目录: 1. 问题起源 2. 对列表中的字典元素排序 3. 对json进行比较(忽略列表中字典的顺序) 一.问题起源 json对象a,b a = '{"ROAD": [{"id": 123}, {"name": "no1"}]}' b = '{"ROAD": [{"name": "
-
关于Python元祖,列表,字典,集合的比较
定义 方法 列表 可以包含不同类型的对象,可以增减元素,可以跟其他的列表结合或者把一个列表拆分,用[]来定义的 eg:aList=[123,'abc',4.56,['inner','list'],7-9j] 1.list(str):将str转换成list类型,str可以使字符串也可以是元组类型 2.aList.append('test'):追加元素到列表中去 3.del aList[1]:删除列表中下标为1的元素 del aList:删除整个列表 4.cmp(list1,list2):比较两个列
-
Python中元组,列表,字典的区别
Python中,有3种内建的数据结构:列表.元组和字典. 1.列表 list是处理一组有序项目的数据结构,即你可以在一个列表中存储一个序列的项目.列表中的项目.列表中的项目应该包括在方括号中,这样python就知道你是在指明一个列表.一旦你创建了一个列表,你就可以添加,删除,或者是搜索列表中的项目.由于你可以增加或删除项目,我们说列表是可变的数据类型,即这种类型是可以被改变的,并且列表是可以嵌套的. 实例: #coding=utf-8 animalslist=['fox','tiger','ra
-
Python实现嵌套列表及字典并按某一元素去重复功能示例
本文实例讲述了Python实现嵌套列表及字典并按某一元素去重复功能.分享给大家供大家参考,具体如下: #! /usr/bin/env python #coding=utf-8 class HostScheduler(object): def __init__(self, resource_list): self.resource_list = resource_list def MergeHost(self): allResource=[] allResource.append(self.res
-
python如何在列表、字典中筛选数据
python如何在列表.字典中筛选数据? 实际问题有哪些? 1.过滤掉列表[3,9,-1,10.-2......] 中负数 2.筛选出字典 {'li_ming':90,'xiao_hong':60,'li_kang':95,'bei_men':98} 中值高于90的项 3.筛选出集合{3,9,-1,10.-2......]中能被3整除的数 问题1如何解决? 最普通方法: #!/usr/bin/python3 def filter_l(data): res = [] for i in data: