Python 数据可视化实现5种炫酷的动态图
本文将介绍 5 种基于 Plotly 的可视化方法,你会发现,原来可视化不仅可用直方图和箱形图,还能做得如此动态好看甚至可交互。
那么,Plotly 有哪些好处?Plotly 的整合能力很强:可与 Jupyter Notebook 一起使用,可嵌入网站,并且完整集成了 Dash——一种用于构建仪表盘和分析应用的出色工具。
启动
如果你还没安装 Plotly,只需在你的终端运行以下命令即可完成安装:
pip install plotly
安装完成后,就开始使用吧!
动画
在研究这个或那个指标的演变时,我们常涉及到时间数据。Plotly 动画工具仅需一行代码就能让人观看数据随时间的变化情况,如下图所示:

代码如下:
import plotly.express as px
from vega_datasets import data
df = data.disasters()
df = df[df.Year > 1990]
fig = px.bar(df,
y="Entity",
x="Deaths",
animation_frame="Year",
orientation='h',
range_x=[0, df.Deaths.max()],
color="Entity")
# improve aesthetics (size, grids etc.)
fig.update_layout(width=1000,
height=800,
xaxis_showgrid=False,
yaxis_showgrid=False,
paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)',
title_text='Evolution of Natural Disasters',
showlegend=False)
fig.update_xaxes(title_text='Number of Deaths')
fig.update_yaxes(title_text='')
fig.show()
只要你有一个时间变量来过滤,那么几乎任何图表都可以做成动画。下面是一个制作散点图动画的例子:
import plotly.express as px
df = px.data.gapminder()
fig = px.scatter(
df,
x="gdpPercap",
y="lifeExp",
animation_frame="year",
size="pop",
color="continent",
hover_name="country",
log_x=True,
size_max=55,
range_x=[100, 100000],
range_y=[25, 90],
# color_continuous_scale=px.colors.sequential.Emrld
)
fig.update_layout(width=1000,
height=800,
xaxis_showgrid=False,
yaxis_showgrid=False,
paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)')
太阳图
太阳图(sunburst chart)是一种可视化 group by 语句的好方法。如果你想通过一个或多个类别变量来分解一个给定的量,那就用太阳图吧。
假设我们想根据性别和每天的时间分解平均小费数据,那么相较于表格,这种双重 group by 语句可以通过可视化来更有效地展示。
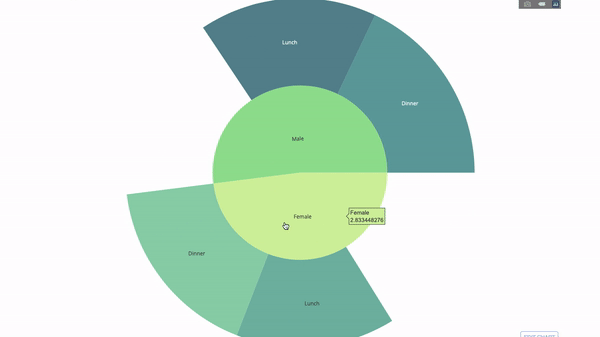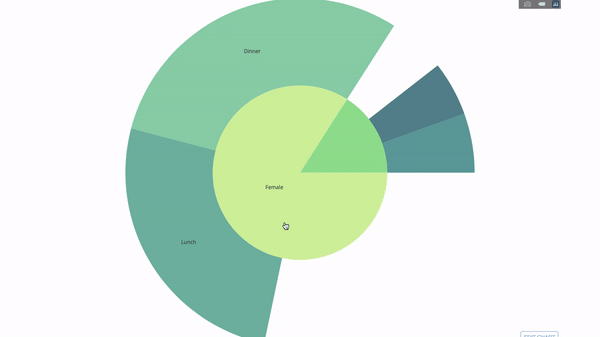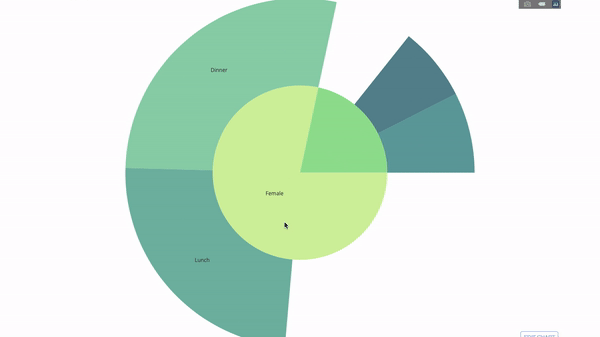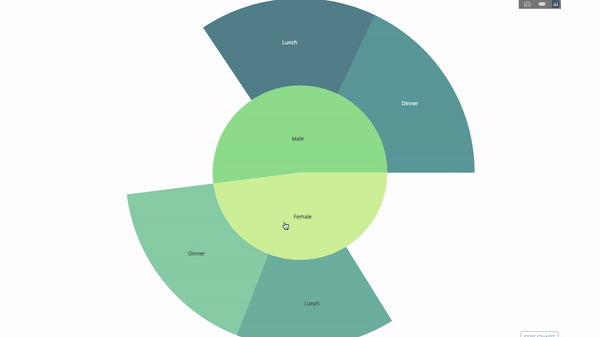
这个图表是交互式的,让你可以自己点击并探索各个类别。你只需要定义你的所有类别,并声明它们之间的层次结构(见以下代码中的 parents 参数)并分配对应的值即可,这在我们案例中即为 group by 语句的输出。
import plotly.graph_objects as go
import plotly.express as px
import numpy as np
import pandas as pd
df = px.data.tips()
fig = go.Figure(go.Sunburst(
labels=["Female", "Male", "Dinner", "Lunch", 'Dinner ', 'Lunch '],
parents=["", "", "Female", "Female", 'Male', 'Male'],
values=np.append(
df.groupby('sex').tip.mean().values,
df.groupby(['sex', 'time']).tip.mean().values),
marker=dict(colors=px.colors.sequential.Emrld)),
layout=go.Layout(paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)'))
fig.update_layout(margin=dict(t=0, l=0, r=0, b=0),
title_text='Tipping Habbits Per Gender, Time and Day')
fig.show()
现在我们向这个层次结构再添加一层:
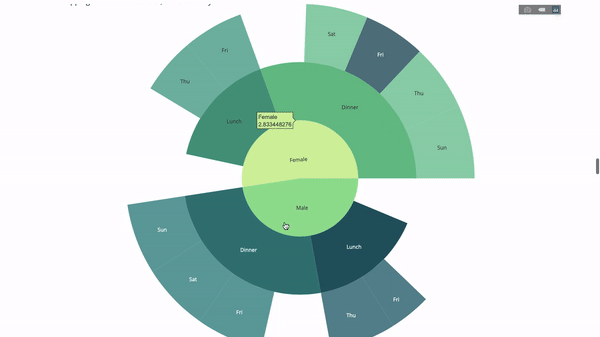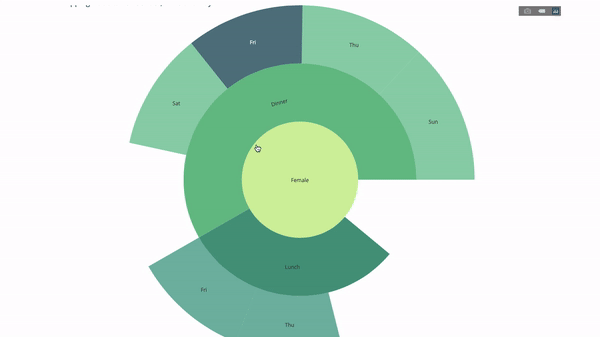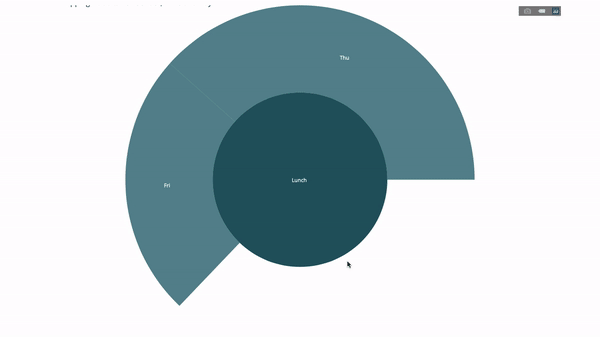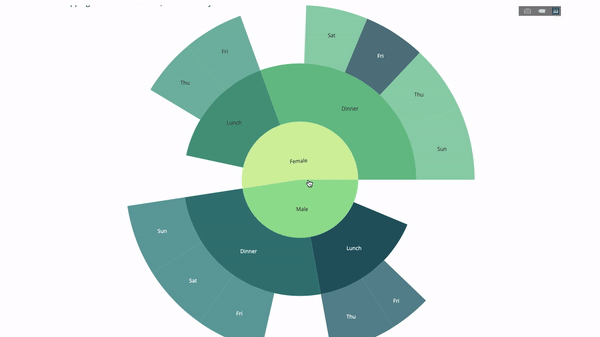
为此,我们再添加另一个涉及三个类别变量的 group by 语句的值。
import plotly.graph_objects as go
import plotly.express as px
import pandas as pd
import numpy as np
df = px.data.tips()
fig = go.Figure(go.Sunburst(labels=[
"Female", "Male", "Dinner", "Lunch", 'Dinner ', 'Lunch ', 'Fri', 'Sat',
'Sun', 'Thu', 'Fri ', 'Thu ', 'Fri ', 'Sat ', 'Sun ', 'Fri ', 'Thu '
],
parents=[
"", "", "Female", "Female", 'Male', 'Male',
'Dinner', 'Dinner', 'Dinner', 'Dinner',
'Lunch', 'Lunch', 'Dinner ', 'Dinner ',
'Dinner ', 'Lunch ', 'Lunch '
],
values=np.append(
np.append(
df.groupby('sex').tip.mean().values,
df.groupby(['sex',
'time']).tip.mean().values,
),
df.groupby(['sex', 'time',
'day']).tip.mean().values),
marker=dict(colors=px.colors.sequential.Emrld)),
layout=go.Layout(paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)'))
fig.update_layout(margin=dict(t=0, l=0, r=0, b=0),
title_text='Tipping Habbits Per Gender, Time and Day')
fig.show()
平行类别
另一种探索类别变量之间关系的方法是以下这种流程图。你可以随时拖放、高亮和浏览值,非常适合演示时使用。

代码如下:
import plotly.express as px
from vega_datasets import data
import pandas as pd
df = data.movies()
df = df.dropna()
df['Genre_id'] = df.Major_Genre.factorize()[0]
fig = px.parallel_categories(
df,
dimensions=['MPAA_Rating', 'Creative_Type', 'Major_Genre'],
color="Genre_id",
color_continuous_scale=px.colors.sequential.Emrld,
)
fig.show()
平行坐标图
平行坐标图是上面的图表的连续版本。这里,每一根弦都代表单个观察。这是一种可用于识别离群值(远离其它数据的单条线)、聚类、趋势和冗余变量(比如如果两个变量在每个观察上的值都相近,那么它们将位于同一水平线上,表示存在冗余)的好用工具。
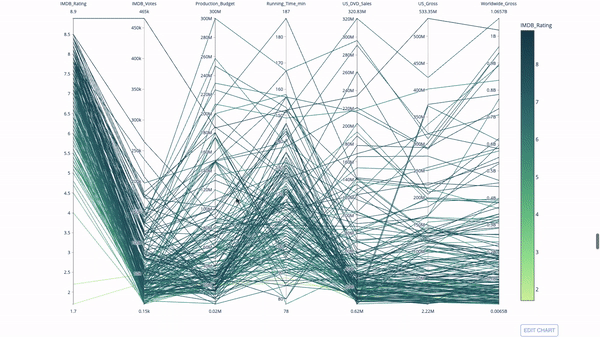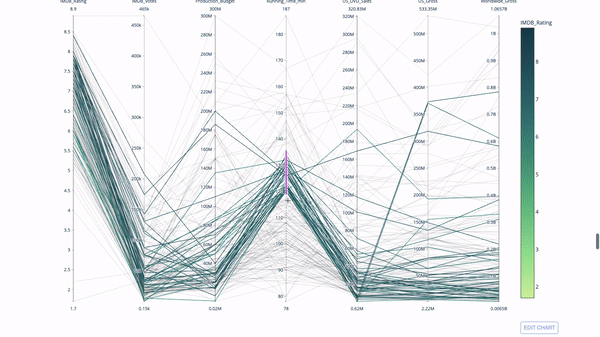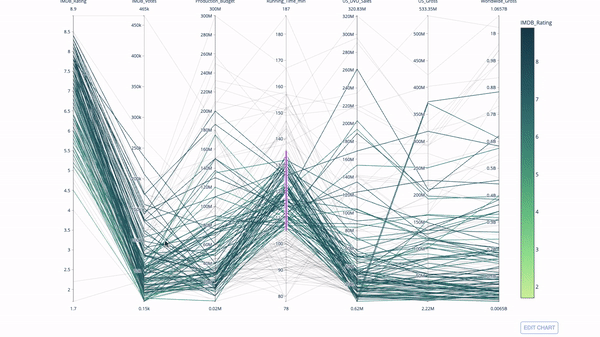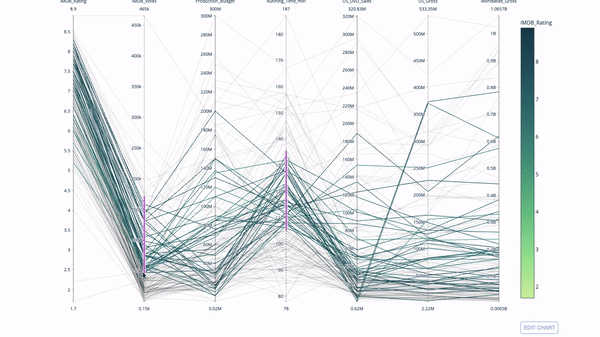
代码如下:
import plotly.express as px
from vega_datasets import data
import pandas as pd
df = data.movies()
df = df.dropna()
df['Genre_id'] = df.Major_Genre.factorize()[0]
fig = px.parallel_coordinates(
df,
dimensions=[
'IMDB_Rating', 'IMDB_Votes', 'Production_Budget', 'Running_Time_min',
'US_Gross', 'Worldwide_Gross', 'US_DVD_Sales'
],
color='IMDB_Rating',
color_continuous_scale=px.colors.sequential.Emrld)
fig.show()
量表图和指示器
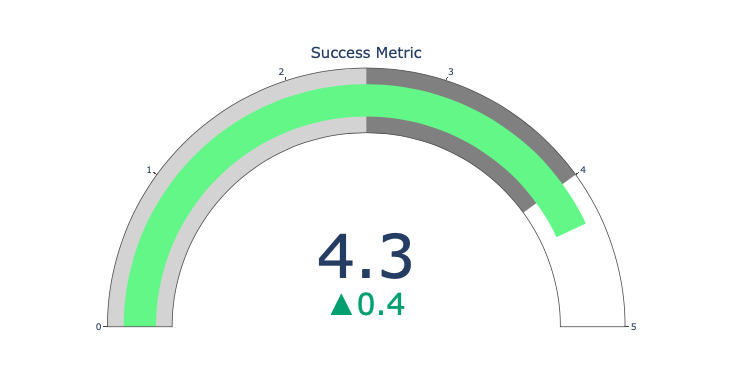
量表图仅仅是为了好看。在报告 KPI 等成功指标并展示其与你的目标的距离时,可以使用这种图表。
指示器在业务和咨询中非常有用。它们可以通过文字记号来补充视觉效果,吸引观众的注意力并展现你的增长指标。
import plotly.graph_objects as go
fig = go.Figure(go.Indicator(
domain = {'x': [0, 1], 'y': [0, 1]},
value = 4.3,
mode = "gauge+number+delta",
title = {'text': "Success Metric"},
delta = {'reference': 3.9},
gauge = {'bar': {'color': "lightgreen"},
'axis': {'range': [None, 5]},
'steps' : [
{'range': [0, 2.5], 'color': "lightgray"},
{'range': [2.5, 4], 'color': "gray"}],
}))
fig.show()
到此这篇关于Python 数据可视化实现5种炫酷的动态图的文章就介绍到这了,更多相关Python 数据可视化内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

用Python可视化新冠疫情数据
目录 前言 数据获取 数据可视化 python的特色 总结 前言 不知道大伙有没有看到过这一句话:“中国(疫苗研发)非常困难,因为在中国我们没有办法做第三期临床试验,因为没有病人了.”这句话是中国工程院院士钟南山在上海科技大学2021届毕业典礼上提出的.这句话在全网流传,被广大网友称之为“凡尔赛”发言. 今天让我们用数据来看看这句话是不是“凡尔赛”本赛.在开始之前我们先来说说今天要用到的python库吧! 1.数据获取部分 requests lxml json openpyxl 2.数据可视化部
-
python可视化大屏库big_screen示例详解
目录 big_screen 特点 安装环境 输入数据 本地运行 在线部署 对于从事数据领域的小伙伴来说,当需要阐述自己观点.展示项目成果时,我们需要在最短时间内让别人知道你的想法.我相信单调乏味的语言很难让别人快速理解.最直接有效的方式就是将数据如上图所示这样,进行可视化展现. 具体如下: big_screen 特点 便利性工具, 结构简单, 你只需传数据就可以实现数据大屏展示. 安装环境 pip install -i https://pypi.tuna.tsinghua.edu.cn/simp
-
Python实现地图可视化案例详解
目录 前言 一.pyecharts Map Geo Bmap 二.folium 结 语 前言 Python的地图可视化库很多,Matplotlib库虽然作图很强大,但只能做静态地图.而我今天要讲的是交互式地图库,分别为pyecharts.folium,掌握这两个库,基本可以解决你的地图可视化需求. 一.pyecharts 首先,必须说说强大的pyecharts库,简单易用又酷炫,几乎可以制作任何图表.pyecharts有v0.5和v1两个版本,两者不兼容,最新的v1版本开始支持链式调用,采用
-
Python抓取数据到可视化全流程的实现过程
目录 1.爬取目标网站:业绩预告_数据中心_同花顺财经 2.获取序号.股票代码.等你所需要的信息 3.组成DataFrame 4.处理数据 1.爬取目标网站:业绩预告_数据中心_同花顺财经 (ps:headers不会设置的可以看这篇:Python 用requests.get获取网页内容为空 ’ ’) import pandas as pd import numpy as np import matplotlib.pyplot as plt import re import requests##把
-
Python 轻松实现可视化大屏
提到数据可视化,我们会想到 Plotly.Matplotlib.Pyecharts等可视化库,或者一些商用软件Tableau.FineBI等等.如果你希望操作更简单.展现效果更强大,那么这款工具 big_screen 更适合你了. 本文介绍具体如下: big_screen 特点 安装环境 输入数据 结果展示 在线部署 代码领取 big_screen 特点 便利性工具, 结构简单, 你只需传数据就可以实现数据大屏展示. 安装环境 pip install -i https://pypi.tuna.t
-
基于Python Dash库制作酷炫的可视化大屏
目录 介绍 数据 大屏搭建 介绍 大家好,我是小F- 在数据时代,我们每个人既是数据的生产者,也是数据的使用者,然而初次获取和存储的原始数据杂乱无章.信息冗余.价值较低. 要想数据达到生动有趣.让人一目了然.豁然开朗的效果,就需要借助数据可视化. 以前给大家介绍过使用Streamlit库制作大屏,今天给大家带来一个新方法. 通过Python的Dash库,来制作一个酷炫的可视化大屏! 先来看一下整体效果,好像还不错哦. 主要使用Python的Dash库.Plotly库.Requests库. 其中R
-
Python机器学习之使用Pyecharts制作可视化大屏
目录 前言 Pyecharts可视化 Map世界地图 柱状图.饼图 Pyecharts组合图表 总结 前言 ECharts是由百度开源的基于JS的商业级数据图表库,有很多现成的图表类型和实例,而Pyecharts则是为了方便我们使用Python实现ECharts的绘图.使用Pyecharts制作可视化大屏,可以分为两步: 1.使用分别Pyecharts分别制作各类图形: 2.使用Pyecharts中的组合图表功能,将所有图片拼接在一张html文件中进行展示. 小五认为影响大屏美观最重要的两个因素
-
Python数据可视化之环形图
目录 1.引言 2.方式一:饼图形式 3.方式二:条形图形式 1.引言 环形图(圆环)在功能上与饼图相同,整个环被分成不同的部分,用各个圆弧来表示每个数据所占的比例值.但其中心的空白可用于显示其他相关数据展示,相比于标准饼图提供了更丰富的数据信息输出. 在本文中,我们将介绍 Matplolib中绘制圆环图的两种方法.使用饼图和参数wedgeprops 的简单方法,以及使用极轴和水平条形图的复杂方法. 2.方式一:饼图形式 在 Matplotlib 中没有绘制圆环图的直接方法,但我们可以使用饼图中
-
Python可视化分析全球火山分布
目录 准备工作 全球火山带的分布可视化 全球火山带的分布可视化优化 地图可视化实战 在地图上打上标记 也就在前几天,南太平洋岛国汤加发生火山喷发,有专门的专家学者分析,这可能是30年来全球规模最大的一次海底火山喷发,它引发的海啸以及火山灰将对周边的大气.洋流.淡水.农业以及民众健康等都造成不同程度的影响. 今天小编就用Python当中的folium模块以及其他的可视化库来对全球的火山情况做一个分析. 准备工作 和以往一样,我们先导入需要数据分析过程当中需要用到的模块并且读取数据集,本次的数据集来
-
Python 数据可视化实现5种炫酷的动态图
本文将介绍 5 种基于 Plotly 的可视化方法,你会发现,原来可视化不仅可用直方图和箱形图,还能做得如此动态好看甚至可交互. 那么,Plotly 有哪些好处?Plotly 的整合能力很强:可与 Jupyter Notebook 一起使用,可嵌入网站,并且完整集成了 Dash——一种用于构建仪表盘和分析应用的出色工具. 启动 如果你还没安装 Plotly,只需在你的终端运行以下命令即可完成安装: pip install plotly 安装完成后,就开始使用吧! 动画 在研究这个或那个指标的演变
-
利用Python代码实现数据可视化的5种方法详解
前言 数据科学家并不逊色于艺术家.他们用数据可视化的方式绘画,试图展现数据内隐藏的模式或表达对数据的见解.更有趣的是,一旦接触到任何可视化的内容.数据时,人类会有更强烈的知觉.认知和交流. 数据可视化是数据科学家工作中的重要组成部分.在项目的早期阶段,你通常会进行探索性数据分析(Exploratory Data Analysis,EDA)以获取对数据的一些理解.创建可视化方法确实有助于使事情变得更加清晰易懂,特别是对于大型.高维数据集.在项目结束时,以清晰.简洁和引人注目的方式展现最终结果是非常
-
Python数据可视化详解
目录 一.Matplotlib模块 1.绘制基本图表 1. 绘制柱形图 2. 绘制条形图 3. 绘制折线图 4. 绘制面积图 5. 绘制散点图 6. 绘制饼图和圆环图 2.图表的绘制和美化技巧 1. 在一张画布中绘制多个图表 2. 添加图表元素 3. 添加并设置网格线 4. 调整坐标轴的刻度范围 3.绘制高级图表 1. 绘制气泡图 2. 绘制组合图 3. 绘制直方图 4. 绘制雷达图 5. 绘制树状图 6. 绘制箱形图 7. 绘制玫瑰图 二.pyecharts模块 1.图表配置项 2.绘制漏斗图
-
Python数据可视化:顶级绘图库plotly详解
有史以来最牛逼的绘图工具,没有之一 plotly是现代平台的敏捷商业智能和数据科学库,它作为一款开源的绘图库,可以应用于Python.R.MATLAB.Excel.JavaScript和jupyter等多种语言,主要使用的js进行图形绘制,实现过程中主要就是调用plotly的函数接口,底层实现完全被隐藏,便于初学者的掌握. 下面主要从Python的角度来分析plotly的绘图原理及方法: ###安装plotly: 使用pip来安装plotly库,如果机器上没有pip,需要先进行pip的安装,这里
-
自己用python做的一款超炫酷音乐播放器
目录 前言 一.核心功能设计 UI设计排版布局 关键字音乐列表爬虫 音乐播放 附加功能 二.实现步骤 1. UI设计排版布局 2. 关键字音乐列表爬虫 3. 音乐播放 4. 附加功能 三.结束语 前言 晚上坐在电脑面前,想着一边撸代码,一边听音乐.搜了搜自己想听的歌,奈何好多歌曲都提示需要版权,无法播放! 没办法,想听歌还是得靠自己解决!今天就一起用python自制一款炫酷的音乐播放器吧~ 首先一起来看看最终实现的音乐播放器效果: 下面,我们开始介绍这个音乐播放器的制作过程. 一.核心功能设计
-
Python数据可视化JupyterNotebook绘图生成高清图片
大家好,我是小五???? 最近有小伙伴问了个问题:如何在jupyter notebook,用Matplotlib画图时能够更"高清"? 今天正好跟大家聊聊,解决办法. 先举个小例子,用 Matplotlib 绘制极坐标图: import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline s = pd.Series(np.arange(20)) fig = plt.figu
-
python数据可视化自制职位分析生成岗位分析数据报表
目录 前言 1. 核心功能设计 可视化展示岗位表格数据 分析岗位薪资情况 分析岗位公司情况 数据分析导出 2. GUI设计与实现 3. 功能实现 3.1 职位数据爬虫 3.2 数据预处理 3.3 岗位数据展示 3.4 薪资图表可视化 3.5 岗位公司情况统计 3.6 预览保存 前言 为什么要进行职位分析?职位分析是人力资源开发和管理的基础与核心,是企业人力资源规划.招聘.培训.薪酬制定.绩效评估.考核激励等各项人力资源管理工作的依据.其次我们可以根据不同岗位的职位分析,可视化展示各岗位的数据分析
-
Python数据可视化Pyecharts库实现桑葚图效果
目录 基本思路我总结大概有三步: 1. 先申明使用sankey 2. 使用add 添加对sankey图的配置信息 3. 最后render生成html文件展示 首先介绍一下什么是桑葚图? 桑基图(Sankey diagram),即桑基能量分流图,也叫桑基能量平衡图. 它是一种特定类型的流程图,图中延伸的分支的宽度对应数据流量的大小,通常应用于能源.材料成分.金融等数据的可视化分析. 因1898年Matthew Henry Phineas Riall Sankey绘制的"蒸汽机的能源效率图"
-
python数据可视化 – 利用Bokeh和Bottle.py在网页上展示你的数据
目录 1. 文章重点和项目介绍 2. 数据集研究和图表准备 2.1 导入数据集 2.2 绘制图表 图表1:2019年上海,北京,深圳三地的每天AQI变化曲线 图表2:2019年上海,北京,深圳三地的每月平均AQI对比 图表3:2017年到2019年北京每月平均AQI对比 3. Bottle网页应用 3.1 文件夹结构 3.2 路由 3.3 模板实现 3.4 启动网页服务 4. 将Bokeh和Bottle集成在一起 4.1 模板修改 4.2 Python代码集成 5. 部署应用到Heroku 6.
-
python数据可视化JupyterLab实用扩展程序Mito
目录 遇见 Mito 如何启动 Mito 数据透视表 Mito 令人印象深刻的功能 可视化数据 自动代码生成 Mito 安装 JupyterLab 是 Jupyter 主打的最新数据科学生产工具,某种意义上,它的出现是为了取代Jupyter Notebook. 它作为一种基于 web 的集成开发环境,你可以使用它编写notebook.操作终端.编辑markdown文本.打开交互模式.查看csv文件及图片等功能. JupyterLab 最棒的体验就是有丰富的扩展插件,我记得过去我们不得不依赖 nu