如何用Python实现自动发送微博
目录
- 一、软件准备
- 1.安装Python 环境
- 2.安装selenium库
- 二、实现方法
- 2.1 使用 Selenium 工具自动化模拟浏览器,当前重点是了解对元素的定位
- 2.2 对元素进行的操作包括
- 2.3 注意
- 2.4 如何定位元素
- 三、完整代码
- 3.1 目前自动输入账号可能会弹出登录保护需扫二维码验证
- 通过cookie进行登录可跳过扫码登录,cookie过期后重新获取下cookie就可以了。
- 拓展:检测cookies有效性
- 拓展:定时每日自动发送
- 总结
一、软件准备
1.安装Python 环境
首先需要你的电脑安装好了Python环境,并且安装好了Python开发工具。如果你还没有安装,可以参考以下文章:如果仅用Python来处理数据、爬虫、数据分析或者自动化脚本、机器学习等,建议使用Python基础环境+jupyter即可,安装使用参考Windows/Mac 安装、使用Python环境+jupyter notebook
2.安装selenium库
pip install selenium
3.下载谷歌浏览器驱动chromedriver,下载地址:http://npm.taobao.org/mirrors/chromedriver/需要选择对应的谷歌浏览器版本,(谷歌浏览器访问:chrome://settings/help,即可查看版本)
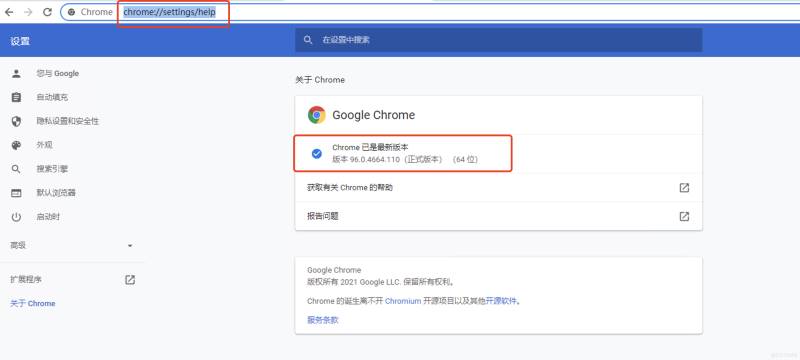
下载好后,随便发到一个路径下即可(简单点最好,记住路径)。
二、实现方法
2.1 使用 Selenium 工具自动化模拟浏览器,当前重点是了解对元素的定位
我们想定位一个元素,可以通过 id、name、class、tag、链接上的全部文本、链接上的部分文本、XPath 或者 CSS 进行定位,在 Selenium Webdriver 中也提供了这 8 种方法方便我们定位元素。
1)通过 id 定位:我们可以使用 find_element_by_id() 函数。比如我们想定位 id=loginName 的元素,就可以使用browser.find_element_by_id(“loginName”)。
2)通过 name 定位:我们可以使用 find_element_by_name() 函数,比如我们想要对 name=key_word 的元素进行定位,就可以使用 browser.find_element_by_name(“key_word”)。
3)通过 class 定位:可以使用 find_element_by_class_name() 函数。
4)通过 tag 定位:使用 find_element_by_tag_name() 函数。
5)通过 link 上的完整文本定位:使用 find_element_by_link_text() 函数。
6)通过 link 上的部分文本定位:使用 find_element_by_partial_link_text() 函数。有时候超链接上的文本很长,我们通过查找部分文本内容就可以定位。
7)通过 XPath 定位:使用 find_element_by_xpath() 函数。使用 XPath 定位的通用性比较好,因为当 id、name、class 为多个,或者元素没有这些属性值的时候,XPath 定位可以帮我们完成任务。
8)通过 CSS 定位:使用 find_element_by_css_selector() 函数。CSS 定位也是常用的定位方法,相比于 XPath 来说更简洁。
2.2 对元素进行的操作包括
1)清空输入框的内容:使用 clear() 函数;
2)在输入框中输入内容:使用 send_keys(content) 函数传入要输入的文本;
3)点击按钮:使用 click() 函数,如果元素是个按钮或者链接的时候,可以点击操作;
4)提交表单:使用 submit() 函数,元素对象为一个表单的时候,可以提交表单;
2.3 注意
由于selenium打开的chrome是原始设置的,所以访问微博首页时一定会弹出来是否提示消息的弹窗,导致不能定位到输入框。可使用如下方法关闭弹窗:
prefs = {"profile.default_content_setting_values.notifications": 2}
2.4 如何定位元素
点击需要定位的元素,然后右键选择检查,可以调出谷歌开发者工具。

获取xpath 路径,点击谷歌开发者工具左上角的小键头(选择元素),选择自己要查看的地方的,开发者工具就会自动定位到对应元素的源码位置,选中对应源码,然后右键,选择Copy-> Copy XPath即可获取到xpath 路径。
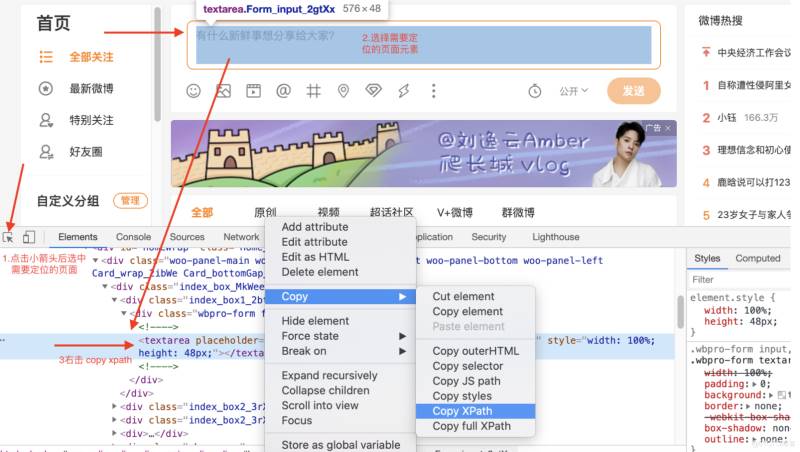
另外: 可以下载 XPath Helper插件,安装后 在网页上选取想要提取的元素, 点击右键 选中 检查 然后 开发者工具自动打开 你可以看到 HTML代码 ,选中然后再次点击右键,选中copy 里的 copy to xpath这样就得到了xpath的值了。
三、完整代码
实现思路: 其实和平时我们正常操作一样,只不过这里,全程由selenium来实现,模拟点击和输入,所以整个过程为:打开登录页面->输入账号密码->点击登录按钮->在发微博框输入发送内容->点击发送按钮->关闭浏览器(自选)。
3.1 目前自动输入账号可能会弹出登录保护需扫二维码验证
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
'''
自动发布微博
content:发送内容
username:微博账号
password:微博密码
'''
def post_weibo(content, username, password):
# 加载谷歌浏览器驱动
path = r'C:/MyEnv/chromedriver.exe ' # 指定驱动存放目录
ser = Service(path)
chrome_options = webdriver.ChromeOptions()
# 把允许提示这个弹窗关闭
prefs = {"profile.default_content_setting_values.notifications": 2}
chrome_options.add_experimental_option("prefs", prefs)
driver = webdriver.Chrome(service=ser, options=chrome_options)
driver.maximize_window() # 设置页面最大化,避免元素被隐藏
print('# get打开微博主页')
url = 'http://weibo.com/login.php'
driver.get(url) # get打开微博主页
time.sleep(5) # 页面加载完全
print('找到用户名 密码输入框')
input_account = driver.find_element_by_id('loginname') # 找到用户名输入框
input_psw = driver.find_element_by_css_selector('input[type="password"]') # 找到密码输入框
# 输入用户名和密码
input_account.send_keys(username)
input_psw.send_keys(password)
print('# 找到登录按钮 //div[@node-type="normal_form"]//div[@]/a')
bt_logoin = driver.find_element_by_xpath('//div[@node-type="normal_form"]//div[@]/a') # 找到登录按钮
bt_logoin.click() # 点击登录
# 等待页面加载完毕 #有的可能需要登录保护,需扫码确认下
time.sleep(40)
# 登录后 默认到首页,有微博发送框
print('# 找到文本输入框 输入内容 //*[@id="homeWrap"]/div[1]/div/div[1]/div/textarea')
weibo_content = driver.find_element_by_xpath('//*[@id="homeWrap"]/div[1]/div/div[1]/div/textarea')
weibo_content.send_keys(content)
print('# 点击发送按钮 //*[@id="homeWrap"]/div[1]/div/div[4]/div/button')
bt_push = driver.find_element_by_xpath('//*[@id="homeWrap"]/div[1]/div/div[4]/div/button')
bt_push.click() # 点击发布
time.sleep(15)
driver.close() # 关闭浏览器
if __name__ == '__main__':
username = '微博用户名'
password = "微博密码"
# 自动发微博
content = '每天进步一点'
post_weibo(content, username, password)
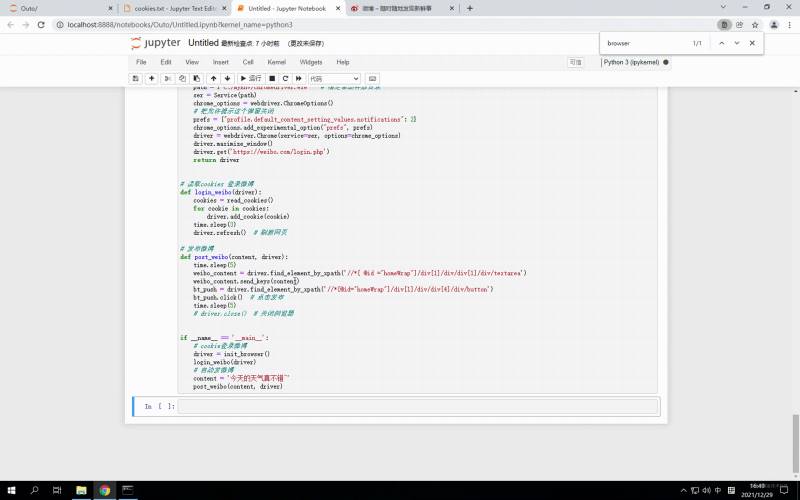
通过cookie进行登录可跳过扫码登录,cookie过期后重新获取下cookie就可以了。
导入第三方包
from selenium import webdriver from selenium.webdriver.chrome.service import Service import time import requests import json
获取cookie到本地
这里主要利用了selenium的get_cookies函数获取cookies。
# 获取cookies 到本地
def get_cookies(driver):
driver.get('https://weibo.com/login.php')
time.sleep(20) # 留时间进行扫码
Cookies = driver.get_cookies() # 获取list的cookies
jsCookies = json.dumps(Cookies) # 转换成字符串保存
with open('cookies.txt', 'w') as f:
f.write(jsCookies)
print('cookies已重新写入!')
# 读取本地的cookies
def read_cookies():
with open('cookies.txt', 'r', encoding='utf8') as f:
Cookies = json.loads(f.read())
cookies = []
for cookie in Cookies:
cookie_dict = {
'domain': '.weibo.com',
'name': cookie.get('name'),
'value': cookie.get('value'),
'expires': '',
'path': '/',
'httpOnly': False,
'HostOnly': False,
'Secure': False
}
cookies.append(cookie_dict)
return cookies
利用cookie登录微博并发送文字 完整代码
# 初始化浏览器 打开微博登录页面
def init_browser():
path = r'C:/MyEnv/chromedriver.exe ' # 指定驱动存放目录
ser = Service(path)
chrome_options = webdriver.ChromeOptions()
# 把允许提示这个弹窗关闭
prefs = {"profile.default_content_setting_values.notifications": 2}
chrome_options.add_experimental_option("prefs", prefs)
driver = webdriver.Chrome(service=ser, options=chrome_options)
driver.maximize_window()
driver.get('https://weibo.com/login.php')
return driver
# 读取cookies 登录微博
def login_weibo(driver):
cookies = read_cookies()
for cookie in cookies:
driver.add_cookie(cookie)
time.sleep(3)
driver.refresh() # 刷新网页
# 发布微博
def post_weibo(content, driver):
time.sleep(5)
weibo_content = driver.find_element_by_xpath('//*[ @id ="homeWrap"]/div[1]/div/div[1]/div/textarea')
weibo_content.send_keys(content)
bt_push = driver.find_element_by_xpath('//*[@id="homeWrap"]/div[1]/div/div[4]/div/button')
bt_push.click() # 点击发布
time.sleep(5)
driver.close() # 关闭浏览器
if __name__ == '__main__':
# cookie登录微博
driver = init_browser()
login_weibo(driver)
# 自动发微博
content = '今天的天气真不错~'
post_weibo(content, driver)
拓展:检测cookies有效性
检测方法:利用本地cookies向微博发送get请求,如果返回的页面源码中包含自己的微博昵称,就说明cookies还有效,否则无效。

# 检测cookies的有效性
def check_cookies():
# 读取本地cookies
cookies = read_cookies()
s = requests.Session()
for cookie in cookies:
s.cookies.set(cookie['name'], cookie['value'])
response = s.get("https://weibo.com")
html_t = response.text
# 检测页面是否包含我的微博用户名
if '老表max' in html_t:
return True
else:
return False
拓展:定时每日自动发送
from apscheduler.schedulers.blocking import BlockingSchedulera
'''
每天早上9:00 发送一条微博
'''
def every_day_nine():
# cookie登录微博
driver = init_browser()
login_weibo(driver)
req = requests.get('https://hitokoto.open.beeapi.cn/random')
get_sentence = req.json()
content = f'【每日一言】{get_sentence["data"]} 来自:一言api'
# 自动发微博
post_weibo(content, driver)
# 选择BlockingScheduler调度器
sched = BlockingScheduler(timezone='Asia/Shanghai')
# job_every_nine 每天早上9点运行一次 日常发送
sched.add_job(every_day_nine, 'cron', hour=9)
# 启动定时任务
sched.start()
总结
到此这篇关于如何用Python实现自动发送微博的文章就介绍到这了,更多相关Python发送微博内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python使用新浪微博API发送微博的例子
1.注册一个新浪应用,得到appkey和secret,以及token,将这些信息写入配置文件sina_weibo_config.ini,内容如下,仅举例: 复制代码 代码如下: [userinfo]CONSUMER_KEY=8888888888CONSUMER_SECRET=777777f3feab026050df37d711200000TOKEN=2a21b19910af7a4b1962ad6ef9999999TOKEN_SECRET=47e2fdb0b0ac983241b0caaf45555
-
Python脚本实现自动发带图的微博
要自动发微博最简单的办法无非是调用新浪微博的API(因为只是简单的发微博,就没必要用它的SDK了).参考开发文档http://open.weibo.com/wiki/API 进行代码编写 创建应用 要使用微博的API,需先要有个应用.随便是个应用就行,可以到这里注册一个站内应用应用注册.注册应用的主要目的是要获得MY_APPKEY 和MY_ACCESS_TOKEN,如图所示 获取access_token API的调用需要登录授权获得access_token.参考 首先,调用https://api
-
python发腾讯微博代码分享
复制代码 代码如下: import urllib.parse,os.path,time,sys,re,urllib.requestfrom http.client import HTTPSConnectionfrom PyQt5.QtCore import *from PyQt5.QtGui import *from PyQt5.QtWidgets import *from PyQt5.QtWebKitWidgets import *from PyQt5.QtNetwork import * #
-
Python3实现的腾讯微博自动发帖小工具
复制代码 代码如下: # -*- coding: UTF-8 -*-import mysql.connector as dbimport client.tWeiboimport time if __name__ == '__main__': connect = db.connect(user='root',db='collection',password='',host="127.0.0.1") cursor = connect.cursor() cursor.execute(&quo
-
如何用Python实现自动发送微博
目录 一.软件准备 1.安装Python 环境 2.安装selenium库 二.实现方法 2.1 使用 Selenium 工具自动化模拟浏览器,当前重点是了解对元素的定位 2.2 对元素进行的操作包括 2.3 注意 2.4 如何定位元素 三.完整代码 3.1 目前自动输入账号可能会弹出登录保护需扫二维码验证 通过cookie进行登录可跳过扫码登录,cookie过期后重新获取下cookie就可以了. 拓展:检测cookies有效性 拓展:定时每日自动发送 总结 一.软件准备 1.安装Python
-
如何用python爬取微博热搜数据并保存
主要用到requests和bf4两个库 将获得的信息保存在d://hotsearch.txt下 import requests; import bs4 mylist=[] r = requests.get(url='https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6',timeout=10) print(r.status_code) # 获取返回状态 r.encoding=r.apparent_encoding demo
-
看看如何用Python绘制小米新版天价logo
最终呈现效果 哈哈,咋们在讲述之前,首先看看最终呈现的效果吧,整体来说还是很不错的. 小米 "新" logo背后的数学 前段时间,小米公司发布了一条微博,引发了热议,原来小米换了新logo了. 很多人,都觉得雷总被骗了.说实话,我当时猛的一看,也是很蒙蔽,可能咋们不懂美学,不懂新logo背后蕴藏的文化底蕴吧! 但是,原设计者原研哉说到:最新设计的小米logo,融入了东方哲学的思考,从而提出了一个具有「超椭圆」数学之美的小米新 LOGO,同时还增加了黑色和科技银来作为小米品牌色彩的新搭档
-
如何用组件实现自动发送电子邮件?
如何用组件实现自动发送电子邮件?JMailUploadAutoForm.asp<html><body><font face="verdana, arial" size="2"><b><form method="post" action="JmailUploadAutoFormProcess.asp" ENCTYPE="multipart/form-data&quo
-
基于python编写的微博应用
本文实例讲述了基于python编写的微博应用,分享给大家供大家参考.具体如下: 在编写自己的微博应用之前,先要到weibo开放平台申请应用的公钥和私钥. 下载python版的SDK,打开example目录,仿照oauthSetTokenUpdate.py进行编码, 复制代码 代码如下: # -*- coding: utf-8 -*- from weibopy.auth import OAuthHandler from weibopy.api import API consumer_key= '应
-
如何用Python来搭建一个简单的推荐系统
在这篇文章中,我们会介绍如何用Python来搭建一个简单的推荐系统. 本文使用的数据集是MovieLens数据集,该数据集由明尼苏达大学的Grouplens研究小组整理.它包含1,10和2亿个评级. Movielens还有一个网站,我们可以注册,撰写评论并获得电影推荐.接下来我们就开始实战演练. 在这篇文章中,我们会使用Movielens构建一个基于item的简易的推荐系统.在开始前,第一件事就是导入pandas和numPy. import pandas as pd import numpy a
-
python爬虫-模拟微博登录功能
微博模拟登录 这是本次爬取的网址:https://weibo.com/ 一.请求分析 找到登录的位置,填写用户名密码进行登录操作 看看这次请求响应的数据是什么 这是响应得到的数据,保存下来 exectime: 8 nonce: "HW9VSX" pcid: "gz-4ede4c6269a09f5b7a6490f790b4aa944eec" pubkey: "EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D24
-
如何用Python合并lmdb文件
由于Caffe使用的存储图像的数据库是lmdb,因此有时候需要对lmdb文件进行操作,本文主要讲解如何用Python合并lmdb文件.没有lmdb支持的,需要用pip命令安装. pip install lmdb 代码及注释如下: # coding=utf-8 # filename: merge_lmdb.py import lmdb # 将两个lmdb文件合并成一个新的lmdb def merge_lmdb(lmdb1, lmdb2, result_lmdb): print 'Merge sta
-
如何用python处理excel表格
openpyxl是一个第三方库,可以处理xlsx格式的Excel文件.pip install openpyxl安装. 读取Excel文件 需要导入相关函数 from openpyxl import load_workbook # 默认可读写,若有需要可以指定write_only和read_only为True wb = load_workbook('pythontab.xlsx') 默认打开的文件为可读写,若有需要可以指定参数read_only为True. 获取工作表--Sheet # 获得所有s
-
如何用python免费看美剧
最早一部<越狱>转变了我对美剧的看法.主人公scofield的聪明才智和坚强的毅力,<绝命毒师>里面主人公的中年逆袭,<纸牌屋>里面老谋深算的政客,等等,这些美剧和里面鲜活的任务,至今令人记忆尤新. 最近,又迷上了美剧,无奈多数视频平台上的美剧都是收费的.对于一个资深Pythoner,我们可以用Python自动获取美剧的网址,下载了慢慢看. 我们以天天看M剧这个网站为例,来展示如何分析和下载这些内容,这里提供一种思路供大家学习.当然,我们还是得支持正版内容,这里是介绍技