python:目标检测模型预测准确度计算方式(基于IoU)
训练完目标检测模型之后,需要评价其性能,在不同的阈值下的准确度是多少,有没有漏检,在这里基于IoU(Intersection over Union)来计算。
希望能提供一些思路,如果觉得有用欢迎赞我表扬我~
IoU的值可以理解为系统预测出来的框与原来图片中标记的框的重合程度。系统预测出来的框是利用目标检测模型对测试数据集进行识别得到的。
计算方法即检测结果DetectionResult与GroundTruth的交集比上它们的并集,如下图:
蓝色的框是:GroundTruth
黄色的框是:DetectionResult
绿色的框是:DetectionResult ⋂GroundTruth
红色的框是:DetectionResult ⋃GroundTruth
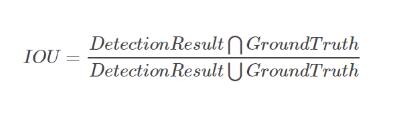

基本思路是先读取原来图中标记的框信息,对每一张图,把所需要的那一个类别的框拿出来,与测试集上识别出来的框进行比较,计算IoU,选择最大的值作为当前框的IoU值,然后通过设定的阈值(漏检0, 0.3, 0.5, 0.7)来进行比较统计,最后得到每个阈值下的所有的判定为正确检测(IoU值大于阈值)的框的数量,然后与原本的标记框的数量一起计算准确度。
其中计算IoU的时候是重新构建一个背景为0的图,设定框所在的位置为1,分别利用原本标注的框和测试识别的框来构建两个这样的图,两者相加就能够让重叠的部分变成2,于是就可以知道重叠部分的大小(交集),从而计算IoU。
构建代码如下:
#读取txt-标准txt为基准-分类别求阈值-阈值为0. 0.3 0.5 0.7的统计
import glob
import os
import numpy as np
#设定的阈值
threshold1=0.3
threshold2=0.5
threshold3=0.7
#阈值计数器
counter0=0
counter1=0
counter2=0
counter3=0
stdtxt=''#标注txt路径
testtxt=''#测试txt路径
txtlist=glob.glob(r'%s\*.txt' %stdtxt)#获取所有txt文件
for path in txtlist:#对每个txt操作
txtname=os.path.basename(path)[:-4]#获取txt文件名
label=1
eachtxt=np.loadtxt(path) #读取文件
for line in eachtxt:
if line[0]==label:
#构建背景为0框为1的图
map1=np.zeros((960,1280))
map1[line[2]:(line[2]+line[4]),line[1]:(line[1]+line[3])]=1
testfile=np.loadtxt(testtxt + txtname + '.txt')
c=0
iou_list=[]#用来存储所有iou的集合
for tline in testfile:#对测试txt的每行进行操作
if tline[0]==label:
c=c+1
map2=np.zeros((960,1280))
map2[tline[2]:(tline[2]+tline[4]),tline[1]:(tline[1]+tline[3])]=1
map3=map1+map2
a=0
for i in map3:
if i==2:
a=a+1
iou=a/(line[3]*line[4]+tline[3]*tline[4]-a)#计算iou
iou_list.append(iou)#添加到集合尾部
threshold=max(iou_list)#阈值取最大的
#阈值统计
if threshold>=threshold3:
counter3=counter3+1
elif threshold>=threshold2:
counter2=counter2+1
elif threshold>=threshold1:
counter1=counter1+1
elif threshold<threshold1:#漏检
counter0=counter0+1
以上这篇python:目标检测模型预测准确度计算方式(基于IoU)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python实现的Iou与Giou代码
最近看了网上很多博主写的iou实现方法,但Giou的代码似乎比较少,于是便自己写了一个,新手上路,如有错误请指正,话不多说,上代码: def Iou(rec1,rec2): x1,x2,y1,y2 = rec1 #分别是第一个矩形左右上下的坐标 x3,x4,y3,y4 = rec2 #分别是第二个矩形左右上下的坐标 area_1 = (x2-x1)*(y1-y2) area_2 = (x4-x3)*(y3-y4) sum_area = area_1 + area_2 w1 = x2 - x1#第
-
Python计算机视觉里的IOU计算实例
其中x1,y1;x2,y2分别表示两个矩形框的中心点 def calcIOU(x1, y1, w1, h1, x2, y2, w2, h2): if((abs(x1 - x2) < ((w1 + w2)/ 2.0)) and (abs(y1-y2) < ((h1 + h2)/2.0))): left = max((x1 - (w1 / 2.0)), (x2 - (w2 / 2.0))) upper = max((y1 - (h1 / 2.0)), (y2 - (h2 / 2.0))) righ
-

python实现BP神经网络回归预测模型
神经网络模型一般用来做分类,回归预测模型不常见,本文基于一个用来分类的BP神经网络,对它进行修改,实现了一个回归模型,用来做室内定位.模型主要变化是去掉了第三层的非线性转换,或者说把非线性激活函数Sigmoid换成f(x)=x函数.这样做的主要原因是Sigmoid函数的输出范围太小,在0-1之间,而回归模型的输出范围较大.模型修改如下: 代码如下: #coding: utf8 '''' author: Huangyuliang ''' import json import random impo
-
python:目标检测模型预测准确度计算方式(基于IoU)
训练完目标检测模型之后,需要评价其性能,在不同的阈值下的准确度是多少,有没有漏检,在这里基于IoU(Intersection over Union)来计算. 希望能提供一些思路,如果觉得有用欢迎赞我表扬我~ IoU的值可以理解为系统预测出来的框与原来图片中标记的框的重合程度.系统预测出来的框是利用目标检测模型对测试数据集进行识别得到的. 计算方法即检测结果DetectionResult与GroundTruth的交集比上它们的并集,如下图: 蓝色的框是:GroundTruth 黄色的框是:Dete
-
python目标检测SSD算法预测部分源码详解
目录 学习前言 什么是SSD算法 ssd_vgg_300主体的源码 学习前言 ……学习了很多有关目标检测的概念呀,咕噜咕噜,可是要怎么才能进行预测呢,我看了好久的SSD源码,将其中的预测部分提取了出来,训练部分我还没看懂 什么是SSD算法 SSD是一种非常优秀的one-stage方法,one-stage算法就是目标检测和分类是同时完成的,其主要思路是均匀地在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,然后利用CNN提取特征后直接进行分类与回归,整个过程只需要一步,所以其优势是速度
-
python目标检测yolo3详解预测及代码复现
目录 学习前言 实现思路 1.yolo3的预测思路(网络构建思路) 2.利用先验框对网络的输出进行解码 3.进行得分排序与非极大抑制筛选 实现结果 学习前言 对yolo2解析完了之后当然要讲讲yolo3,yolo3与yolo2的差别主要在网络的特征提取部分,实际的解码部分其实差距不大 代码下载 本次教程主要基于github中的项目点击直接下载,该项目相比于yolo3-Keras的项目更容易看懂一些,不过它的许多代码与yolo3-Keras相同. 我保留了预测部分的代码,在实际可以通过执行dete
-
python目标检测yolo2详解及预测代码复现
目录 前言 实现思路 1.yolo2的预测思路(网络构建思路) 2.先验框的生成 3.利用先验框对网络的输出进行解码 4.进行得分排序与非极大抑制筛选 实现结果 前言 ……最近在学习yolo1.yolo2和yolo3,写这篇博客主要是为了让自己对yolo2的结构有更加深刻的理解,同时要理解清楚先验框的含义. 尽量配合代码观看会更容易理解. 直接下载 实现思路 1.yolo2的预测思路(网络构建思路) YOLOv2使用了一个新的分类网络DarkNet19作为特征提取部分,DarkNet19包含19
-
python目标检测实现黑花屏分类任务示例
目录 背景 核心技术与架构图 技术实现 1.数据的标注 2.训练过程 3.损失的计算 4.对输出内容的处理 效果展示 总结 背景 视频帧的黑.花屏的检测是视频质量检测中比较重要的一部分,传统做法是由测试人员通过肉眼来判断视频中是否有黑.花屏的现象,这种方式不仅耗费人力且效率较低. 为了进一步节省人力.提高效率,一种自动的检测方法是大家所期待的.目前,通过分类网络模型对视频帧进行分类来自动检测是否有黑.花屏是比较可行且高效的. 然而,在项目过程中,视频帧数据的收集比较困难,数据量较少,部分花屏和正
-
python目标检测SSD算法训练部分源码详解
目录 学习前言 讲解构架 模型训练的流程 1.设置参数 2.读取数据集 3.建立ssd网络. 4.预处理数据集 5.框的编码 6.计算loss值 7.训练模型并保存 开始训练 学习前言 ……又看了很久的SSD算法,今天讲解一下训练部分的代码.预测部分的代码可以参照https://blog.csdn.net/weixin_44791964/article/details/102496765 讲解构架 本次教程的讲解主要是对训练部分的代码进行讲解,该部分讲解主要是对训练函数的执行过程与执行思路进行详
-
python目标检测yolo1 yolo2 yolo3和SSD网络结构对比
目录 睿智的目标检测5——yolo1.yolo2.yolo3和SSD的网络结构汇总对比 学习前言各个网络的结构图与其实现代码1.yolo12.yolo23.yolo34.SSD 总结 学习前言 ……最近在学习yolo1.yolo2和yolo3,事实上它们和SSD网络有一定的相似性,我准备汇总一下,看看有什么差别. 各个网络的结构图与其实现代码 1.yolo1 由图可见,其进行了二十多次卷积还有四次最大池化,其中3x3卷积用于提取特征,1x1卷积用于压缩特征,最后将图像压缩到7x7xfilter的
-
python目标检测IOU的概念与示例
目录 学习前言 什么是IOU IOU的特点 全部代码 学习前言 神经网络的应用还有许多,目标检测就是其中之一,目标检测中有一个很重要的概念便是IOU 什么是IOU IOU是一种评价目标检测器的一种指标. 下图是一个示例:图中绿色框为实际框(好像不是很绿……),红色框为预测框,当我们需要判断两个框之间的关系时,需要用什么指标呢? 此时便需要用到IOU. 计算IOU的公式为: 可以看到IOU是一个比值,即交并比. 在分子部分,值为预测框和实际框之间的重叠区域: 在分母部分,值为预测框和实际框所占有的
-
python目标检测YoloV4当中的Mosaic数据增强方法
目录 什么是Mosaic数据增强方法 实现思路 全部代码 什么是Mosaic数据增强方法 Yolov4的mosaic数据增强参考了CutMix数据增强方式,理论上具有一定的相似性! CutMix数据增强方式利用两张图片进行拼接. 但是mosaic利用了四张图片,根据论文所说其拥有一个巨大的优点是丰富检测物体的背景!且在BN计算的时候一下子会计算四张图片的数据!就像下图这样: 实现思路 1.每次读取四张图片. 2.分别对四张图片进行翻转.缩放.色域变化等,并且按照四个方向位置摆好. 3.进行图片的
-
python目标检测非极大抑制NMS与Soft-NMS
目录 睿智的目标检测31——非极大抑制NMS与Soft-NMS 注意事项学习前言什么是非极大抑制NMS1.非极大抑制NMS的实现过程2.柔性非极大抑制Soft-NMS的实现过程 注意事项 Soft-NMS对于大多数数据集而言,作用比较小,提升效果非常不明显,它起作用的地方是大量密集的同类重叠场景,大量密集的不同类重叠场景其实也没什么作用,同学们可以借助Soft-NMS理解非极大抑制的含义,但是实现的必要性确实不强,在提升网络性能上,不建议死磕Soft-NMS. 已对该博文中的代码进行了重置,视频