浅谈MySQL与redis缓存的同步方案
本文介绍MySQL与Redis缓存的同步的两种方案
- 方案1:通过MySQL自动同步刷新Redis,MySQL触发器+UDF函数实现
- 方案2:解析MySQL的binlog实现,将数据库中的数据同步到Redis
一、方案1(UDF)
场景分析:当我们对MySQL数据库进行数据操作时,同时将相应的数据同步到Redis中,同步到Redis之后,查询的操作就从Redis中查找
过程大致如下:
在MySQL中对要操作的数据设置触发器Trigger,监听操作
客户端(NodeServer)向MySQL中写入数据时,触发器会被触发,触发之后调用MySQL的UDF函数
UDF函数可以把数据写入到Redis中,从而达到同步的效果

方案分析:
- 这种方案适合于读多写少,并且不存并发写的场景
- 因为MySQL触发器本身就会造成效率的降低,如果一个表经常被操作,这种方案显示是不合适的
演示案例
下面是MySQL的表

下面是UDF的解析代码

定义对应的触发器



二、方案2(解析binlog)
在介绍方案2之前我们先来介绍一下MySQL复制的原理,如下图所示:
- 主服务器操作数据,并将数据写入Bin log
- 从服务器调用I/O线程读取主服务器的Bin log,并且写入到自己的Relay log中,再调用SQL线程从Relay log中解析数据,从而同步到自己的数据库中

方案2就是:
- 上面MySQL的整个复制流程可以总结为一句话,那就是:从服务器读取主服务器Bin log中的数据,从而同步到自己的数据库中
- 我们方案2也是如此,就是在概念上把主服务器改为MySQL,把从服务器改为Redis而已(如下图所示),当MySQL中有数据写入时,我们就解析MySQL的Bin log,然后将解析出来的数据写入到Redis中,从而达到同步的效果

例如下面是一个云数据库实例分析:
云数据库与本地数据库是主从关系。云数据库作为主数据库主要提供写,本地数据库作为从数据库从主数据库中读取数据
本地数据库读取到数据之后,解析Bin log,然后将数据写入写入同步到Redis中,然后客户端从Redis读数据

这个技术方案的难点就在于:如何解析MySQL的Bin Log。但是这需要对binlog文件以及MySQL有非常深入的理解,同时由于binlog存在Statement/Row/Mixedlevel多种形式,分析binlog实现同步的工作量是非常大的
Canal开源技术
canal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL(也支持mariaDB)
开源参考地址有:https://github.com/liukelin/canal_mysql_nosql_sync
工作原理(模仿MySQL复制):
- canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
- mysql master收到dump请求,开始推送binary log给slave(也就是canal)
- canal解析binary log对象(原始为byte流)

架构:
server代表一个canal运行实例,对应于一个jvm
instance对应于一个数据队列 (1个server对应1..n个instance)
instance模块:
- eventParser (数据源接入,模拟slave协议和master进行交互,协议解析)
- eventSink (Parser和Store链接器,进行数据过滤,加工,分发的工作)
- eventStore (数据存储)
- metaManager (增量订阅&消费信息管理器)

大致的解析过程如下:
- parse解析MySQL的Bin log,然后将数据放入到sink中
- sink对数据进行过滤,加工,分发
- store从sink中读取解析好的数据存储起来
- 然后自己用设计代码将store中的数据同步写入Redis中就可以了
- 其中parse/sink是框架封装好的,我们做的是store的数据读取那一步

更多关于Cancl可以百度搜索
下面是运行拓扑图

MySQL表的同步,采用责任链模式,每张表对应一个Filter。例如zvsync中要用到的类设计如下:
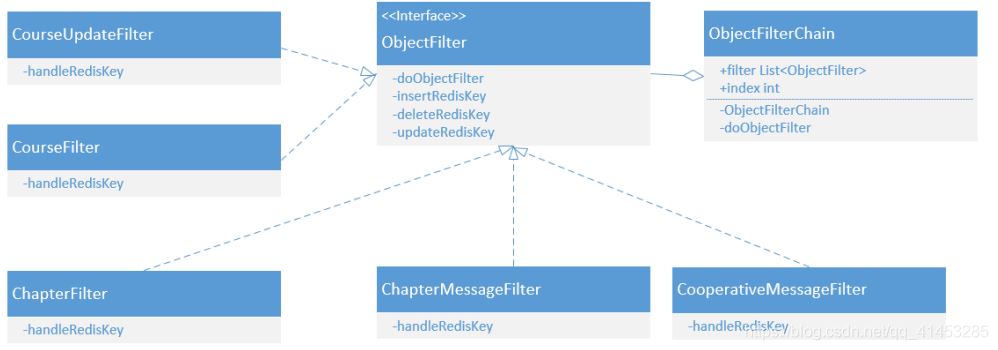
下面是具体化的zvsync中要用到的类,每当新增或者删除表时,直接进行增删就可以了

三、附加
本文上面所介绍的都是从MySQL中同步到缓存中。但是在实际开发中可能有人会用下面的方案:
- 客户端有数据来了之后,先将其保存到Redis中,然后再同步到MySQL中
- 这种方案本身也是不安全/不可靠的,因此如果Redis存在短暂的宕机或失效,那么会丢失数据

到此这篇关于浅谈MySQL与redis缓存的同步方案的文章就介绍到这了,更多相关MySQL与redis缓存同步内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
PHP使用redis实现统计缓存mysql压力的方法
本文实例讲述了PHP使用redis实现统计缓存mysql压力的方法.分享给大家供大家参考,具体如下: <?php header("Content-Type:text/html;charset=utf-8"); include 'lib/mysql.class.php'; $mysql_obj = mysql::getConn(); //redis $redis = new Redis(); $redis->pconnect('127.0.0.1', 6379); if(is
-
redis服务器环境下mysql实现lnmp架构缓存
配置环境:redhat6.5 server1:redis(172.25.254.1) server2:php(172.25.254.2) server3:mysql(172.25.254.3) 配置步骤: server2: 1.server2安装php的redis相应模块 2.nginx安装 [root@server2 php-fpm.d]# rpm -ivh nginx-1.8.0-1.el6.ngx.x86_64.rpm warning: nginx-1.8.0-1.el6.ngx.x86_
-
MySQL和Redis实现二级缓存的方法详解
redis简介 Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库 Redis 与其他 key - value 缓存产品有以下三个特点: Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用 Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储 Redis支持数据的备份,即master-slave模式的数据备份 优势 性能极高 - Redis能读的速度是110
-

浅谈MySQL与redis缓存的同步方案
本文介绍MySQL与Redis缓存的同步的两种方案 方案1:通过MySQL自动同步刷新Redis,MySQL触发器+UDF函数实现 方案2:解析MySQL的binlog实现,将数据库中的数据同步到Redis 一.方案1(UDF) 场景分析:当我们对MySQL数据库进行数据操作时,同时将相应的数据同步到Redis中,同步到Redis之后,查询的操作就从Redis中查找 过程大致如下: 在MySQL中对要操作的数据设置触发器Trigger,监听操作 客户端(NodeServer)向MySQL中写入数
-
浅谈MySQL 统计行数的 count
MySQL count() 函数我们并不陌生,用来统计每张表的行数.但如果你的表越来越大,且是 InnoDB 引擎的话,会发现计算的速度会越来越慢.在这篇文章里,会先介绍 count() 实现的原理及原因,然后是 count 不同用法的性能分析,最后给出需要频繁改变并需要统计表行数的解决方案. Count() 的实现 InnoDB 和 MyISAM 是 MySQL 常用的数据引擎,由于两者实现的不同,导致 count() 操作计算的效率也不同. 对于 MyISAM 来说,它把每个表的总行数都存在
-
浅谈mysql 树形结构表设计与优化
前言 在诸多的管理类,办公类等系统中,树形结构展示随处可见,以"部门"或"机构"来说,接触过的同学应该都知道,最终展示到页面的效果就是层级结构的那种,下图随机列举了一个部门的树型结构展示图 设计考虑因素 1.表结构设计 稍稍有点开发和表结构设计经验的同学,设计出这样一张表,应该很容易,只需要在depart表中,添加一个pid/字段即可满足要求,参考下表: CREATE TABLE `depart` ( `depart_id` varchar(32) NOT NULL
-
浅谈MySQL和Lucene索引的对比分析
MySQL和Lucene都可以对数据构建索引并通过索引查询数据,一个是关系型数据库,一个是构建搜索引擎(Solr.ElasticSearch)的核心类库.两者的索引(index)有什么区别呢?以前写过一篇<Solr与MySQL查询性能对比>,只是简单的对比了下查询性能,对于内部原理却没有解释,本文简单分析下两者的索引区别. MySQL索引实现 在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,本文主要讨论MyISAM和InnoDB两个存储引擎的索引实现方式. M
-
浅谈MySQL大表优化方案
背景 阿里云RDS FOR MySQL(MySQL5.7版本)数据库业务表每月新增数据量超过千万,随着数据量持续增加,我们业务出现大表慢查询,在业务高峰期主业务表的慢查询需要几十秒严重影响业务 方案概述 一.数据库设计及索引优化 MySQL数据库本身高度灵活,造成性能不足,严重依赖开发人员的表设计能力以及索引优化能力,在这里给几点优化建议 时间类型转化为时间戳格式,用int类型储存,建索引增加查询效率 建议字段定义not null,null值很难查询优化且占用额外的索引空间 使用TINYINT类
-
浅谈Mysql多表连接查询的执行细节
先构建本篇博客的案列演示表: create table a(a1 int primary key, a2 int ,index(a2)); --双字段都有索引 create table c(c1 int primary key, c2 int ,index(c2), c3 int); --双字段都有索引 create table b(b1 int primary key, b2 int); --有主键索引 create table d(d1 int, d2 int); --没有索引 insert
-
浅谈mysql执行过程以及顺序
前言:mysql在我们的开发中基本每天都要面对的,作为开发中的数据的来源,mysql承担者存储数据和读写数据的职责.因为学习和了解mysql是至关重要的,那么当我们在客户端发起一个sql到出现详细的查询数据,这其中究竟经历了什么样的过程?mysql服务端是如何处理请求的,又是如何执行sql语句的?本篇博客将来探讨这个问题: 一:mysql执行过程 mysql整体的执行过程如下图所示: 1.1:连接器 连接器的主要职责就是: ①负责与客户端的通信,是半双工模式,这就意味着某一固定时刻只能由客户端向
-
浅谈MySQL user权限表
MySQL 在安装时会自动创建一个名为 mysql 的数据库,mysql 数据库中存储的都是用户权限表.用户登录以后,MySQL 会根据这些权限表的内容为每个用户赋予相应的权限. user 表是 MySQL 中最重要的一个权限表,用来记录允许连接到服务器的账号信息.需要注意的是,在 user 表里启用的所有权限都是全局级的,适用于所有数据库. user 表中的字段大致可以分为 4 类,分别是用户列.权限列.安全列和资源控制列,下面主要介绍这些字段的含义. 用户列 用户列存储了用户连接 MySQL
-
浅谈mysql join底层原理
目录 join算法 驱动表和非驱动表的区别 1.Simple Nested-Loop Join,简单嵌套-无索引的情况 2.Index Nested-Loop Join-有索引的情况 3.Block Nested-Loop Join ,join buffer缓冲区 缓冲区大小 数据量大的表和数据量小的表如何选择连接顺序 细节 join算法 mysql只支持一种join算法:Nested-Loop Join(嵌套循环连接),但Nested-Loop Join有三种变种: Simple Nested
-
浅谈mysql的timestamp存在的时区问题
目录 简介 基本概念 timestamp与datetime区别 为什么网上又说timestamp类型存在时区问题? 那为什么网上会说timestamp存在时区问题? serverTimezone的本质 将serverTimezone与mysql时区保持一致 Entity中日期属性是String呢? 最佳实践 数据库中用timestamp还是int来存储时间? 总结 简介 众所周知,mysql中有两个时间类型,timestamp与datetime,但当在网上搜索timestamp与datetime