R语言创建矩阵的实现方法
矩阵
- 向量vector用于描述一维数据,是R语言中最基础的数据结构形式
- 矩阵matrix可以描述二维数据,和向量相似,其内部元素可以是实数、复数、字符、逻辑型数据
- 矩阵包含行和列,分为单位矩阵、对角矩阵和普通矩阵。矩阵可以进行四则运算,以及进行求特征值、特征向量等运算
- 矩阵matrix使用两个下标来访问元素,A[i,j]表示矩阵A第i行、第j列的元素
矩阵创建——matrix函数
matrix函数创建矩阵,其格式为:
matrix(data = NA,nrow = 1,ncol = 1,byrow = FALSE,dimnames = NULL)
| 参数 | 描述 |
|---|---|
| data | 矩阵的元素 |
| nrow | 行的维数 |
| ncol | 列的维数 |
| byrow | 矩阵的元素是否按行填充,默认为FALSE(按列填充) |
| dimnames | 以字符型向量表示的行名和列名 |
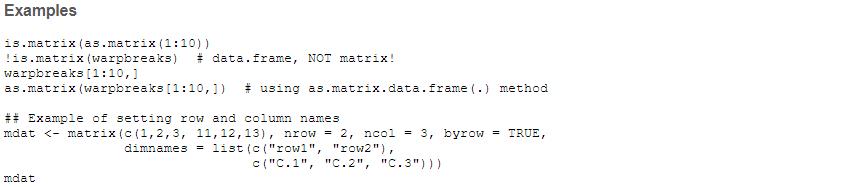

在创建矩阵时,也可以使用dimnames参数设置行和列的名称
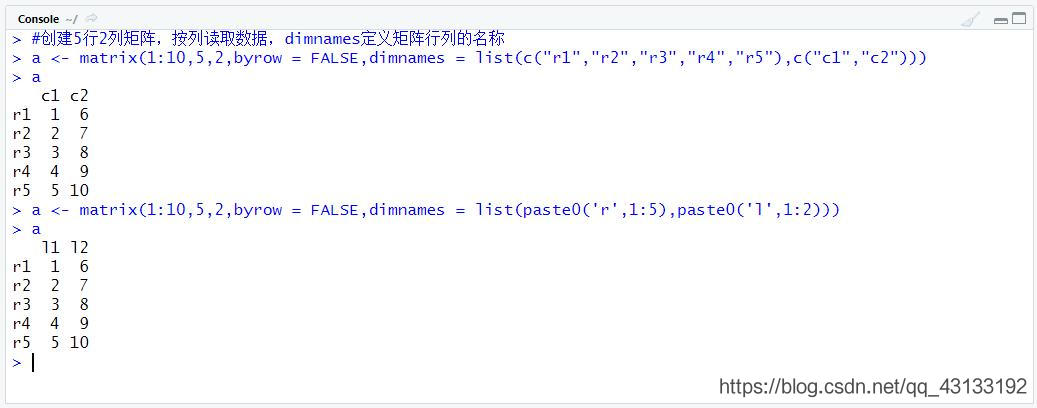
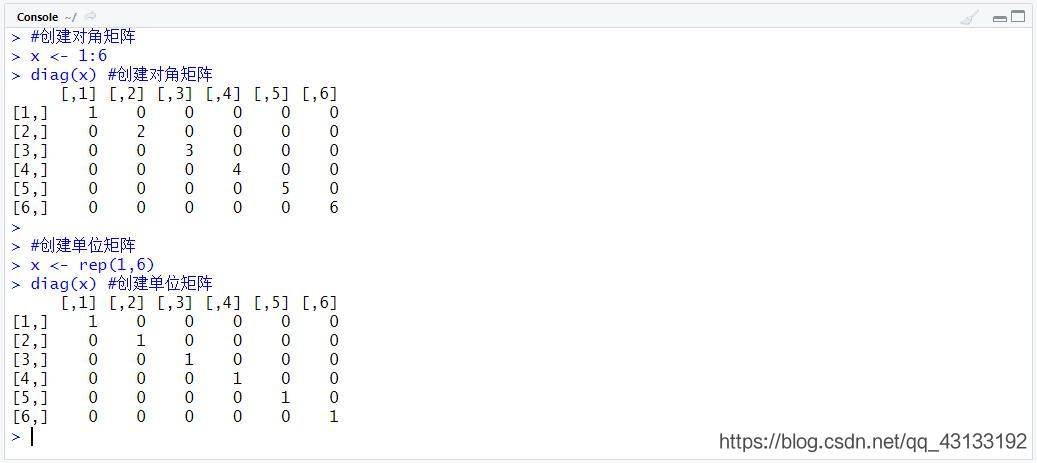
矩阵创建——对角矩阵和单位矩阵的创建
diag函数创建矩阵

矩阵——维度(dim)
dim——维度
矩阵:向量+维度

到此这篇关于R语言创建矩阵的实现方法的文章就介绍到这了,更多相关R语言创建矩阵内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

R语言 出现矩阵/缺失值的解决方案
缺失值处理一般包括三步: 1. 识别缺失数据: 2. 检查导致数据缺失的原因: 3. 删除包含缺失值的实例或用合理的数值代替(插补)缺失值. 1.判断缺失值 函数is.na().is.nan()和is.infinite()可分别用来识别缺失值.不可能值和无穷值.每个返回结果都是 TRUE或FALSE na表示缺失值 nan表示NOT A NUMBER infinite表示+-Inf 一定要亲手试x = 0/0,以及x = 1/0 >x <- NA > is.na(x) [1] TRUE
-
R语言中向量和矩阵简单运算的实现
一.向量运算 向量是有相同基本类型的元素序列,一维数组,定义向量的最常用办法是使用函数c(),它把若干个数值或字符串组合为一个向量. 1.R语言向量的产生方法 > x <- c(1,2,3) > x [1] 1 2 3 2.向量加减乘除都是对其对应元素进行的,例如下面 > x <- c(1,2,3) > y <- x*2 > y [1] 2 4 6 (注:向量的整数除法是%/%,取余是%%.) 3.向量的内积,有两种方法. 第一种方法:%*% > x
-
R语言创建矩阵的实现方法
矩阵 向量vector用于描述一维数据,是R语言中最基础的数据结构形式 矩阵matrix可以描述二维数据,和向量相似,其内部元素可以是实数.复数.字符.逻辑型数据 矩阵包含行和列,分为单位矩阵.对角矩阵和普通矩阵.矩阵可以进行四则运算,以及进行求特征值.特征向量等运算 矩阵matrix使用两个下标来访问元素,A[i,j]表示矩阵A第i行.第j列的元素 矩阵创建--matrix函数 matrix函数创建矩阵,其格式为: matrix(data = NA,nrow = 1,ncol = 1,byro
-
R语言中矩阵matrix和数据框data.frame的使用详解
本文主要介绍了R语言中矩阵matrix和数据框data.frame的一些使用,分享给大家,具体如下: "一,矩阵matrix" "创建向量" x_1=c(1,2,3) x_1=c(1:3) x_2=1:3 typeof(x_1)==typeof(x_2)#查看目标类型 x_3=seq(1,6,length=3)#将1--6分为3个数 a<-rep(1:3,each=3) #1到3依次重复 c<-rep(1:3,times=3) #1到3重复3次 d<
-
R语言处理JSON文件的方法
JSON文件以人类可读格式将数据存储为文本. Json代表JavaScript Object Notation. R可以使用rjson包读取JSON文件. 安装rjson包 在R语言控制台中,您可以发出以下命令来安装rjson包. install.packages("rjson") 输入数据 通过将以下数据复制到文本编辑器(如记事本)中来创建JSON文件. 使用.json扩展名保存文件,并将文件类型选择为所有文件(*.*). { "ID":["1"
-
R语言实现随机森林的方法示例
目录 随机森林算法介绍 算法介绍: 决策树生长步骤: 投票过程: 基本思想: 随机森林的优点: 缺点 R语言实现 随机森林模型搭建 1:randomForest()函数用于构建随机森林模型 2:importance()函数用于计算模型变量的重要性 3:MDSplot()函数用于实现随机森林的可视化 4:rfImpute()函数可为存在缺失值的数据集进行插补(随机森林法),得到最优的样本拟合值 5:treesize()函数用于计算随机森林中每棵树的节点个数 随机森林算法介绍 算法介绍: 简单的说,
-
C语言创建线程thread_create()的方法
在头文件 threads.h 中,定义和声明了支持多线程的宏.类型和函数.所有直接与线程相关的标识符,均以前缀 thrd_ 作为开头.例如,thrd_t 是一个对象类型,它标识了一个线程. 函数 thrd_create()用于创建并开始执行一个新线程.函数 thrd_create()的其中一个参数为在新线程中需要被执行的函数 thrd_create()的其中一个参数为在新线程中需要被执行的函数.thrd_create()的完整原型是: int thrd_create(thrd_t *thr, t
-
R语言seq()函数的调用方法
看到有很多读者浏览了这篇文章,心里很是开心,为了能够更好地帮助大家,决定再修改一下,帮助大家更好地理解. --------修改于:2018年4月28日 为了方便大家在开发环境中直接实验测试代码,下面,我将说明和函数的用法全部用英文给出(避免乱码),并加以注释,希望能够对大家有所帮助! 首先,我们来看一个seq()函数应用的实例! x <- seq(0, 10, by = 0.01) y <- sin(x) plot(y) 下面,我们来看函数的主要使用方法! 注意:在本文调用函数时,均采用写出入
-
R语言读取excel数据的方法(两行命令)
安装库 安装xlsx install.packages("xlsx") 使用 library(xlsx) ray = read.xlsx('D:/Code/R/Data in Excel/Chapter 8/gamma-ray.xls',1) 后面的参数,第一个放地址,第二个放具体sheet页(这里除了可以放数值之外,还可以放对应的名字(字符串)).除此之外,还可以使用encoding="utf-8"的方式来定义使用中文数据. 效果: > a = read.x
-
R语言实现LASSO回归的方法
Lasso回归又称为套索回归,是Robert Tibshirani于1996年提出的一种新的变量选择技术.Lasso是一种收缩估计方法,其基本思想是在回归系数的绝对值之和小于一个常数的约束条件下,使残差平方和最小化,从而能够产生某些严格等于0的回归系数,进一步得到可以解释的模型.R语言中有多个包可以实现Lasso回归,这里使用lars包实现. 1.利用lars函数实现lasso回归并可视化显示 x = as.matrix(data5[, 2:7]) #data5为自己的数据集 y = as.ma
-
R语言 实现矩阵相乘100次
[D1 D2]2*1 [T1 T2]1*2 要求D1和D2随机的变动, 矩阵相乘100次 rm(list=ls()) gc() options(scipen = 2000) ##################写成函数###########3 #################定义TT矩阵(1*2) TT <- matrix(c(1,3),1,2) DD<- matrix(c(1,2),2,1) result1 <- DD %*% TT m1=result1 ##############
-
R语言常用两种并行方法之snowfall详解
上一篇博客(R中两种常用并行方法之parallel)中已经介绍了R中常见的一种并行包:parallel,其有着简单便捷等优势,其实缺点也是非常明显,就是很不稳定.很多时候我们将大量的计算任务挂到服务器上进行运行时,更看重的是其稳定性. 这时就要介绍R中的另一个并行利器--snowfall,这也是在平时做模拟时用的最多的一种方法. 针对上篇中的简单例子 首先是一个最简单的并行的例子,这个例子不需要载入任何依赖库.函数.对象等.相对也比较简单: library(snowfall) # 载入snowf