SpringBoot+OCR 实现图片文字识别
本篇介绍的是基于百度人工智能接口的文字识别实现。
1. 注册百度云,获得AppID
此处百度云非百度云盘,而是百度智能云。
大家可进入https://cloud.baidu.com/自行注册,这里就不多说了。
接下来,我们进行应用的创建
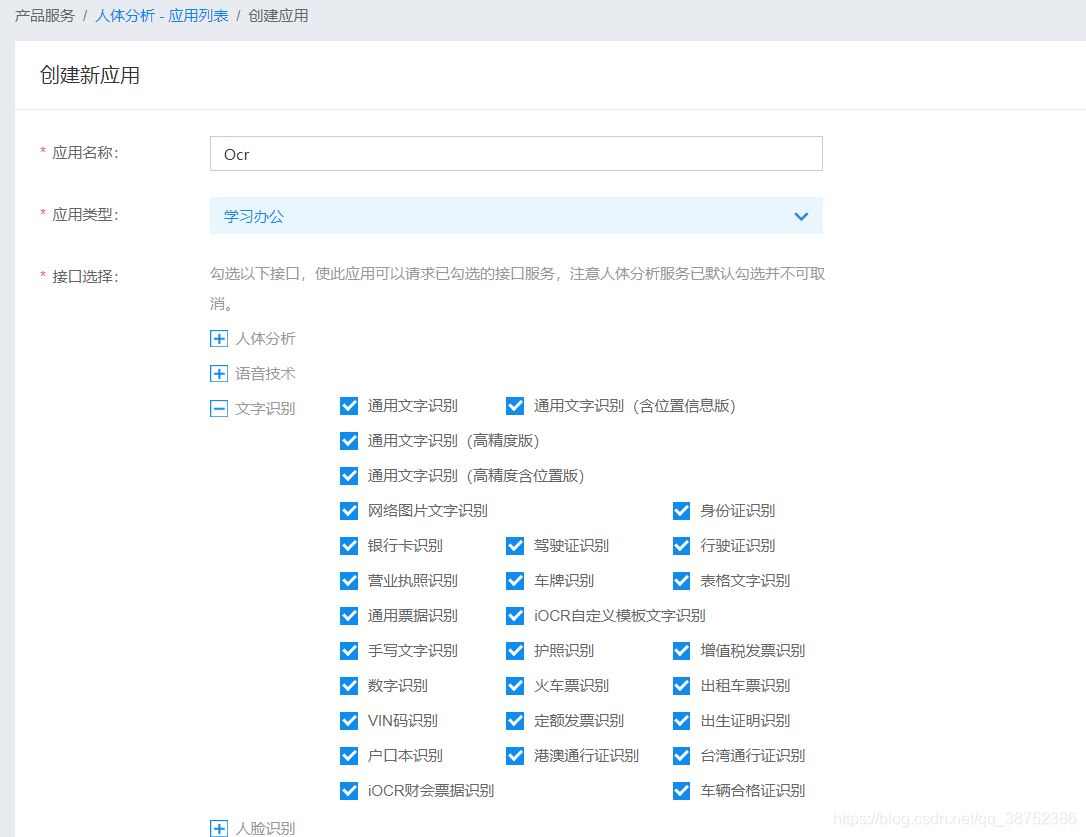
所需接口根据实际勾选,我们暂时只需前四个即可。
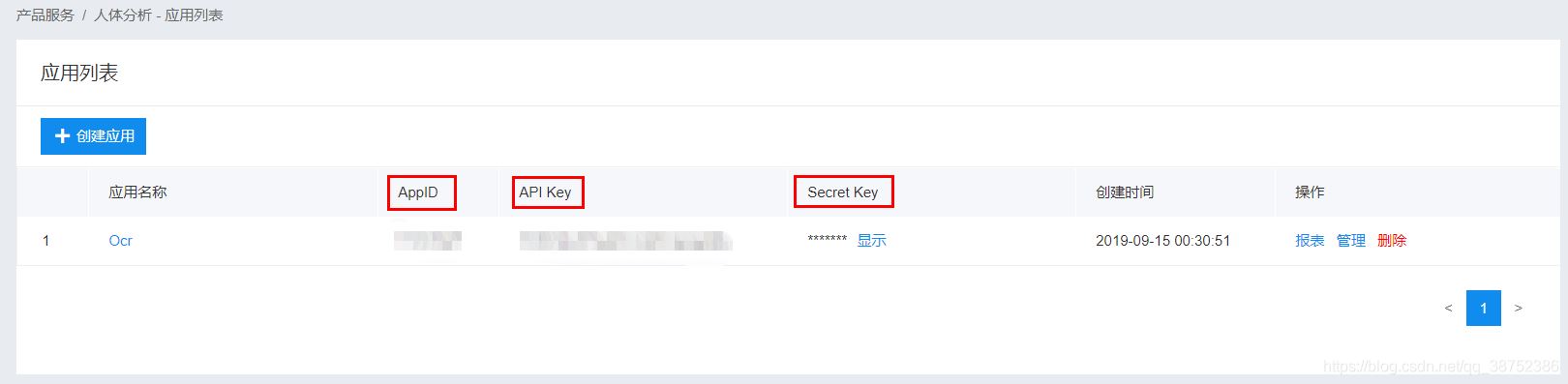
2. 日常demo操作
pom.xml:
<dependencies>
<!-- 百度人工智能依赖 -->
<!-- https://mvnrepository.com/artifact/com.baidu.aip/java-sdk -->
<dependency>
<groupId>com.baidu.aip</groupId>
<artifactId>java-sdk</artifactId>
<version>4.11.3</version>
</dependency>
<!-- 对象转换成json -->
<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-databind -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.8</version>
</dependency>
</dependencies>
JsonChange.class:(json处理工具类)
public class JsonChange {
/**
* json字符串转换为map
*/
public static <T> Map<String, Object> json2map(String jsonString) throws Exception {
ObjectMapper mapper = new ObjectMapper();
mapper.setSerializationInclusion(JsonInclude.Include.NON_NULL);
return mapper.readValue(jsonString, Map.class);
}
}
OcrController.class:
AipOcr client = new AipOcr(“AppID”, “API Key”, “Secret Key”) 切记换成刚刚创建的应用的AppID,而且三个参数均是String类型。
@RestController
public class OcrController {
@PostMapping(value = "/ocr")
public Map<Object, Object> ocr(MultipartFile file) throws Exception {
AipOcr client = new AipOcr("AppID", "API Key", "Secret Key");
// 传入可选参数调用接口
HashMap<String, String> options = new HashMap<String, String>(4);
options.put("language_type", "CHN_ENG");
options.put("detect_direction", "true");
options.put("detect_language", "true");
options.put("probability", "true");
// 参数为二进制数组
byte[] buf = file.getBytes();
JSONObject res = client.basicGeneral(buf, options);
Map map = JsonChange.json2map(res.toString());
return map;
}
}
如果只想要识别出来的文字即可,可加入
// 提取并打印出识别的文字
List list = (List) map.get("words_result");
int len = ((List) map.get("words_result")).size();
for(int i=0; i<len; i++) {
str = str + ((Map) list.get(i)).get("words") + "\n";
}
接下来 postman 测试
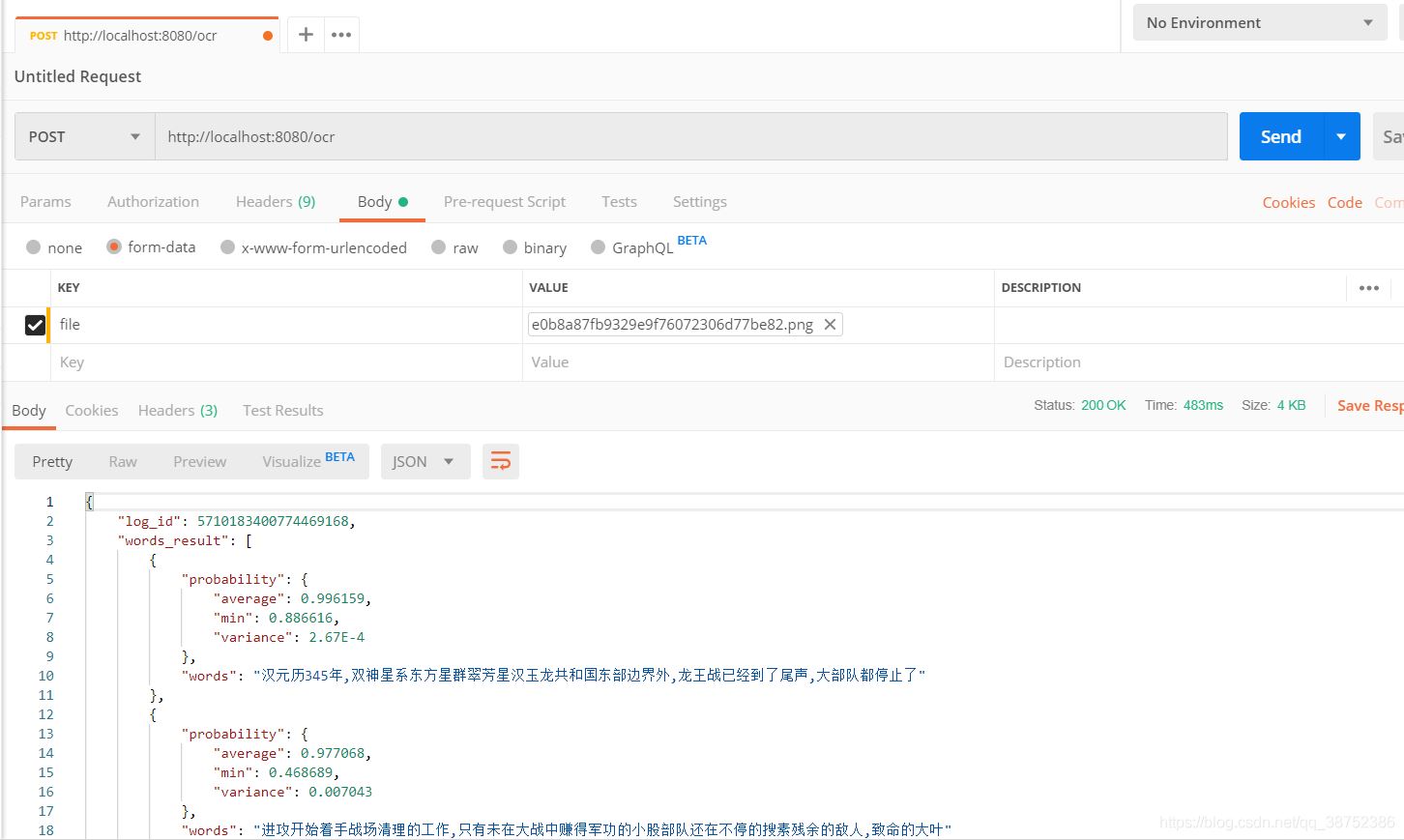
ocr识别出的全部数据输出

提取其中识别的文字,剔除其他信息
到此这篇关于SpringBoot+OCR 实现图片文字识别的文章就介绍到这了,更多相关SpringBoot OCR 图片文字识别内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

SpringBoot+Tess4j实现牛逼的OCR识别工具的示例代码
前言 " 等不到风中你的脸颊 眼泪都美到很融洽 等不到掩饰的雨落下 我的眼泪被你察觉 " 听着循环的歌曲,写着久违的bug.好吧,还是一天.正好一个小伙伴说,要不要做个工具站玩一下.我就随意的找了个工具站,看了下,发现很多都有文字的OCR识别功能.因此,我想起来之前了解的非常流行的开源的OCR大神级别的项目,Tesseract OCR. 简单介绍 官网如下所示 tesseract-ocr.github.io/ 简洁明了,挂在github上的网站. 详细的不再介绍,感兴趣的,可以进入同志
-
SpringBoot+OCR 实现图片文字识别
本篇介绍的是基于百度人工智能接口的文字识别实现. 1. 注册百度云,获得AppID 此处百度云非百度云盘,而是百度智能云. 大家可进入https://cloud.baidu.com/自行注册,这里就不多说了. 接下来,我们进行应用的创建 所需接口根据实际勾选,我们暂时只需前四个即可. 2. 日常demo操作 pom.xml: <dependencies> <!-- 百度人工智能依赖 --> <!-- https://mvnrepository.com/artifact/com
-
Python调用百度OCR实现图片文字识别的示例代码
百度AI提供了一天50000次的免费文字识别额度,可以愉快的免费使用!下面直接上方法: 首先在百度AI创建一个应用,按照下图创建即可,创建后会获得如下: 创建后会获得如下信息: APP_ID = '******' API_KEY = '************' SECRET_KEY = '**************' 下面就是百度API包的安装,在终端cmd输入如下语句直接pip方式安装,注意是 baidu-api 哦! pip install --user baidu-aip 接下来上py
-
Python图像处理之图片文字识别功能(OCR)
OCR与Tesseract介绍 将图片翻译成文字一般被称为光学文字识别(Optical Character Recognition,OCR).可以实现OCR 的底层库并不多,目前很多库都是使用共同的几个底层OCR 库,或者是在上面进行定制. Tesseract 是一个OCR 库,目前由Google 赞助(Google 也是一家以OCR 和机器学习技术闻名于世的公司).Tesseract 是目前公认最优秀.最精确的开源OCR 系统. 除 了极高的精确度,Tesseract 也具有很高的灵活性.它可
-
Java使用Tessdata做OCR图片文字识别的详细思路
说到文字识别,目前除了用一些现成的api,大概就是 tessdata.canvas或者 ocrad等. 1.百度接口用过(可以自己去百度开发者申请,免费的),识别率吧,还可以,但也不是百分百的,但是次数使用有限制,虽然也是够用,但是被限制总是害怕超过不让用. 2.canvas的话是需要对图片做具体的处理,涉及到图片的翻转.置灰.文字间隔的设定等等,成功率很高,但是公司产品验证码是各式各样的,没办法用这种方法处理,所以暂时放弃了. 3.ocrad这个目前用过其.js版本,识别率还是比较低的,具体使
-
Node+OCR实现图像文字识别功能
开发目的 这算是node应用的第二个小应用吧,主要目的是熟悉node和express框架.原理很简单:在node搭建的环境下引用第三方包处理图片数据并返回给前台信息. 实现效果,百度提供的图片识别,经过测试识别车牌号等规范文字数字还是比较准确的 环境需求 1.Express 是一个非常流行的node.js的web框架.基于connect(node中间件框架).提供了很多便于处理http请求等web开发相关的扩展. 2.OCR: 通用文字识别 Node SDK目录结构: ├── src │
-
Android实现图片文字识别
导言 OCR,tess-two ,openCV等晕人的东西先分清,OCR,tess-two是图片文字识别,而openCV是图像识别比对,对于更复杂的图片文字识别需求可以采用百度云人工智能通用文字识别开发的SDK,准确性更高 可运行的步骤 1.添加依赖 implementation 'com.rmtheis:tess-two:8.0.0' 2.下载字体识别库(chi_sim.traineddata 中文简体,chi_tra.traineddata 中文繁体,eng.traineddata 英文库)
-
Python 图片文字识别的实现之PaddleOCR
目录 项目使用 项目结构 环境部署 1.安装Anaconda,构造虚拟环境 2.依赖包下载 测试代码 参数补充 总结 前言 什么是OCR? 光学字符识别(Optical Character Recognition, OCR),是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程.简而言之,检测图像中的文本资料,并且识别出文本的内容. 那么有哪些应用场景呢? 其实我们日常生活中处处都有ocr的影子,比如在疫情期间身份证识别录入信息.车辆车牌号识别.自动驾驶等.我们的生活中,机器学习已
-
Python3一行代码实现图片文字识别的示例
自学Python3第5天,今天突发奇想,想用Python识别图片里的文字.没想到Python实现图片文字识别这么简单,只需要一行代码就能搞定 from PIL import Image import pytesseract #上面都是导包,只需要下面这一行就能实现图片文字识别 text=pytesseract.image_to_string(Image.open('denggao.jpeg'),lang='chi_sim') print(text) 我们以识别诗词为例 下面是我们要识别的图片 先
-
java实现图片文字识别ocr
最近在开发的时候需要识别图片中的一些文字,网上找了相关资料之后,发现google有一个离线的工具,以下为java使用的demo 在此之前,使用这个工具需要在本地安装OCR工具: 下面一个是一定要安装的离线包,建议默认安装 上面一个是中文的语言包,如果网络可以FQ的童鞋可以在安装的时候就选择语言包在线安装,有多种语言可供选择,默认只有英文的 exe安装好之后,把上面一个文件拷到安装目录下tessdata文件夹下 如C:\Program Files (x86)\Tesseract-OCR\tessd
-
图片文字识别(OCR)插件Ocrad.js教程
Ocrad.js 相当于是 Ocrad 项目的纯 JavaScript 版本,使用 Emscripten 自动转换.这是一个简单的 OCR (光学字符识别)程序,可以扫描图像中的文字回文本. 不像 GOCR.js,Ocrad.js 被设计成一个端口,而不是围绕可执行的包装.这意味着后续的图像处理,并不涉及重新初始化可执行代码,以便处理图像尽可能少的进行,因此它需要的时间仅为 GOCR.js 的八分之一. GOCR.js 已在 github 进行开源,下载地址 ocrad.js 的csdn资源下载