解决java文件流处理异常 mark/reset not supported问题
原因:
给定的流不支持mark和reset就会报这个错误。
获取到一个网络流,这个网络流不允许读写头来回移动,也就不允许mark/reset机制.
解决办法:
用BufferedInputStream把原来的流包一层.
BufferedInputStream buffInputStream = new BufferedInputStream(fileInputStream);
补充知识:Java BufferedReader之mark和reset方法实践
在读取文本的操作中,常常会在读取到文件末尾时重新到文件开头进行操作。通过搜索发现,有两种方法:
(1)mark和reset方法,但是在博客中都是以简短的string为示例对象;
(2)利用randomacessfile中的seek方法,seek方法可进行移动。
由于前面的文本操作使用了BufferedReader,所以只能用mark和reset方法将程序进行完善。非常好理解这两个方法,一个在前面做标记,另一个重置返回到做标记的位置。
首先,看一下mark方法
public void mark
(int readAheadLimit) throws IOException
Marks the present position in the stream. Subsequent calls to reset() will attempt to reposition the stream to this point.
Overrides:
markin class Reader
Parameters:
readAheadLimit - Limit on the number of characters that may be read while still preserving the mark. An attempt to reset the stream after reading characters up to this limit or beyond may fail. A limit value larger than the size of the input buffer will cause a new buffer to be allocated whose size is no smaller than limit. Therefore large values should be used with care.
Throws:
IllegalArgumentException- If readAheadLimit is < 0
IOException- If an I/O error occurs
mark(readAheadLimit)方法仅有一个参数,翻译过来就是“保证mark有效的情况下限制读取的字符数。当 读取字符达到或超过此限制时,尝试重置流会失败。当限制数值大于输入buffer的默认大小时,将会动态分配一个容量不小于限制数值的buffer。因此,应该慎用大数值。”
第二,获取文件的大小
既然要读取某文件,需知道该文件的大小,调用file.length()方法,将会“Returns the length of the file denoted by this abstract pathname. The return value is unspecified if this pathname denotes a directory.”
由于返回数值为long型,需加一个判断(是否超出int默认最大值,因为mark方法的参数为int类型)后才能进行int的强制转换
int size;
if(filesize>=2147483647){
Toast.makeText(……).show();
}else{
size=(int)filesize;
}
第三,设置mark参数
如果完成前两步后,并mark(size)你就去尝试,那么还会出错,为什么呢?
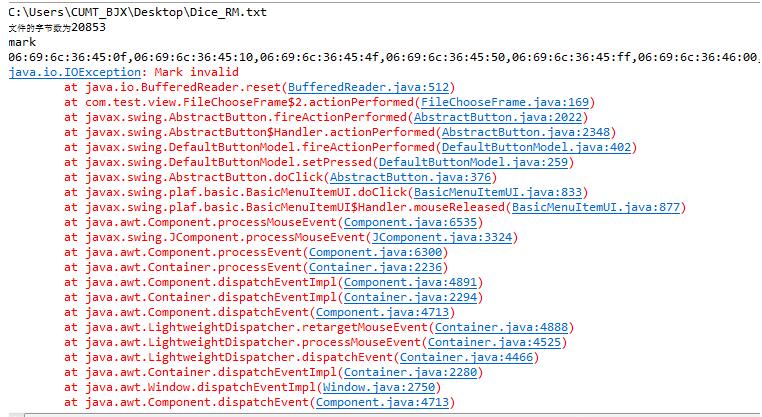
前面的mark()方法已经讲过“当读取字符达到或超过此限制时,尝试重置流会失败”,所以最好还要将mark的size数值加1.
解决。
PS:我尝试了270多KB的文件,也可以正常读取。
修改---2016-07-19 17:03
吃完午饭回来后,就意识到一个问题,重复操作io是非常浪费资源的,为何不将数据全部写入list或map中,这样就是从缓存中读取数据,操作更快一点。一下午都在修改程序,包括输出部分及排序操作,总之对这部分的理解加深了许多。
相关推荐
-
Java优先队列(PriorityQueue)重写compare操作
we can custom min heap or max heap by override the method compare. package myapp.kit.quickstart.utils; import java.util.Comparator; import java.util.Queue; /** * priority queue (heap) demo. * * @author huangdingsheng * @version 1.0, 2020/5/8 */ publi
-
Java map 优雅的元素遍历方式说明
Java 8 , Lambda + foreach 语法糖, 写起来非常的 clean public static void main(String[] args) { // map init Map<String, String> map = new HashMap<>(); map.put("k", "v"); /*=====处理函数只有单条语句=====*/ map.forEach((k, v) -> System.out.pri
-
java 流与 byte[] 的互转操作
1. InputStream -> byte[] 引入 apache.commons.is 包 import org.apache.commons.io.IOUtils; byte[] bytes = IOUtils.toByteArray(inputStream); 2. byte[] -> InputStream InputStream inputStream = new ByteArrayInputStream(bytes); 补充知识:byte[]与各种数据类型互相转换示例 在sock
-
Java 遍历 String 字符串所有字符的操作
我就废话不多说了,大家还是直接看代码吧~ package com.app.main.utils; /** * Created with IDEA * author:Dingsheng Huang * Date:2019/6/28 * Time:下午8:48 */ public class StringUtils { public static void main(String[] args) { String test = "abc123"; // 遍历所有字符 for (int i
-
Java内部类的实现原理与可能的内存泄漏说明
在使用java内部类的时候要注意可能引起的内存泄漏 代码如下 package com.example; public class MyClass { public static void main(String[] args) throws Throwable { } public class A{ public void methed1(){ } } public static class B{ public void methed1(){ } } 编译生成了如下文件 反编译MyClass 反
-
Java.toCharArray()和charAt()的效率对比分析
LeetCode中的一道算法题,使用toCharArray()时间超时,换成charAt()之后通过,所以测试一下两者的运行效率: public static void test() { String s = "a"; for(int i = 0; i < 100000; i++) { s += "a"; } long start1 = System.currentTimeMillis(); char[] cs = s.toCharArray(); for(c
-
解决java文件流处理异常 mark/reset not supported问题
原因: 给定的流不支持mark和reset就会报这个错误. 获取到一个网络流,这个网络流不允许读写头来回移动,也就不允许mark/reset机制. 解决办法: 用BufferedInputStream把原来的流包一层. BufferedInputStream buffInputStream = new BufferedInputStream(fileInputStream); 补充知识:Java BufferedReader之mark和reset方法实践 在读取文本的操作中,常常会在读取到文件末
-

java 文件流的处理方式 文件打包成zip
目录 java 文件流的处理 文件打包成zip 1.下载文件到本地 2.java后端下载 3.文件打包成zip 后台多文件打包成zip返回流 前台提供按钮一键下载 java 文件流的处理 文件打包成zip 1.下载文件到本地 public void download(HttpServletResponse response){ String filePath ="";//文件路径 String fileName ="";//文件名称 // 读到流中 InputStr
-
Java文件流关闭和垃圾回收机制
1.先看以下一段代码 import java.io.FileInputStream; public class TTT { public static void main(String[] args) throws Exception { for (int i = 0; i < 10; i++) { final String threadId = "thread_" + i; Thread thread = new Thread(new Runnable() { public v
-
Java文件字符输入流FileReader读取txt文件乱码的解决
目录 Java文件字符输入流FileReader读取txt文件乱码 先上代码 控制台输出结果如下 原因是 运行之后的结果为 字符流读取UTF-8和写出txt文件乱码问题 话不多说,直接上图 解决 Java文件字符输入流FileReader读取txt文件乱码 先上代码 public class FileInAndOut { public static void main(String[] args) { //定义指定磁盘的文件的File对象 File file = new File("E:/大三下
-
解决Eclipse打开.java文件异常,提示用系统工具打开的问题
问题描述: Eclipse中打开目录中的.java文件,提示用系统工具打开.其它文件都能正常打开,只有这一个文件有问题. 解决方案: 右键->openWith->Java Edit 补充:eclipse运行项目特别慢,出现Java heap space溢出 在eclipse中可用为JVM设置参数: Window-->Preferences-->Java-->Installed JREs 然后选中你安装的 jre-->Edit-->Default VM Argume
-
完美解决java读取大文件内存溢出的问题
1. 传统方式:在内存中读取文件内容 读取文件行的标准方式是在内存中读取,Guava 和Apache Commons IO都提供了如下所示快速读取文件行的方法: Files.readLines(new File(path), Charsets.UTF_8); FileUtils.readLines(new File(path)); 实际上是使用BufferedReader或者其子类LineNumberReader来读取的. 传统方式的问题: 是文件的所有行都被存放在内存中,当文件足够大时很快就会
-
解决java.util.NoSuchElementException异常的问题
java.util.NoSuchElementException 报错的行数是一个scnner的next,本来和老师讨论了半天没有什么头绪,错误的原因是,因为找不到下一个元素,然后,如果把上一个函数中操作system.in的函数注释掉,就不会出现问题. 后来,老师一问,就是因为在上面函数的时候,我将system手动关闭掉了,系统资源不同于文件,一旦关闭就不能再打开,这就是问题的原因. 系统资源一旦释放就不能再开启了,所以只有确定不在使用系统的时候,才能将流关闭. 补充知识:对于springboo
-
response文件流输出文件名中文不显示的解决
目录 文件流输出文件名中文不显示 使用如下方法没有解决 解决方法 response下载时中文文件名乱码 文件流输出文件名中文不显示 response返回文件流 用response.setHeader(“Content-disposition”, “attachment; filename=”+fileName);结果中文名称以“—”下滑下显示. 使用如下方法没有解决 response.setCharacterEncoding("UTF-8"); response.setContentT
-
Java IO流 文件传输基础
一.文件的编码 package com.study.io; /** * 测试文件编码 */ public class EncodeDemo { /** * @param args * @throws Exception */ public static void main(String[] args) throws Exception { String s="好好学习ABC"; byte[] bytes1=s.getBytes();//这是把字符串转换成字符数组,转换成的字节序列用的是
-
JAVA读取文件流,设置浏览器下载或直接预览操作
最近项目需要在浏览器中通过URL预览图片.但发现浏览器始终默认下载,而不是预览.研究了一下,发现了问题: // 设置response的Header,注意这句,如果开启,默认浏览器会进行下载操作,如果注释掉,浏览器会默认预览. response.addHeader("Content-Disposition", "attachment;filename=" + FileUtil.getOriginalFilename(path)); 然后需要注意: response.s