Python移动测试开发subprocess模块项目实战
目录
- 一、背景
- 二、subprocess 模块基础
- 1. subprocess.run 方法
- 2. subprocess.Popen 方法
- 3. run 与 Popen 的同步/异步对比实验
- 三、遇到的问题与解决方案
- 如何保证获取到完整的进程执行日志
- 解决方案如下:
一、背景
我们日常测试中存在大量重复的造数操作,且流程较长,为了提升测试效率,我们搭建了数据构造平台。平台采用了前端 + 脚本分离的形式,数据构造脚本独立存在,页面和脚本的关联关系通过页面配置进行绑定。
页面配置中,包含了脚本的路径以及启动命令,因此,运行脚本的时候需要在服务器上启动子进程中去执行脚本命令。为了能够了解脚本的执行情况,还需要获取脚本的执行状态以及执行日志。
平台后端语言是 Python,因此,选择了 Python 中的 subprocess 模块,本文重点阐述 subprocess 模块在项目实战中遇到的问题以及解决方案。
本文涉及的程序执行环境如下:
Python 版本:3.8.3
操作系统:windows server
二、subprocess 模块基础
subprocess 模块允许我们启动一个新进程,并连接到它们的输入/输出/错误管道,从而获取返回值。subprocess 模块首先推荐使用的是它的 run 方法,更高级的用法可以直接使用 Popen 接口。
1. subprocess.run 方法
subprocess.run() 方法是 3.5 版本新增的,用于可以接受等待进程执行结束后获取返回值的场景,如果可以满足使用需求,官方推荐使用 run() 方法。
subprocess.run() 的执行过程是同步的,脚本执行结束之前是阻塞的,只有脚本结束之后才会返回 subprocess.CompletedProcess 对象。
2. subprocess.Popen 方法
subprocess.Popen() 是 subprocess 的核心,子进程的创建和管理都靠它处理。Popen() 相当于 run() 的高级版本,更加灵活,使开发人员能够处理 run() 方法未涵盖的更丰富的场景。subprocess.Popen() 是异步的,进程启动以后,我们可以通过预先指定好的 stdout 和 stderr 来实时读取到子进程的输出。
subprocess.Popen()常用参数介绍:
args:shell命令,可以是字符串或者序列类型(如:list,元组)
stdin, stdout, stderr:分别表示程序的标准输入、输出、错误句柄
shell:如果该参数为 True,将通过操作系统的 shell 执行指定的命令,args只能是String类型的参数;该参数为False,args可以是序列类型。
Popen 对象常用方法:
poll(): 检查进程是否终止,如果终止返回 returncode,否则返回 None,项目中通过该方法返回判断进程是否执行结束。
wait(timeout): 等待子进程终止,如果进程执行时间较长,可以使用该方法来保证进程执行完整。
communicate(input,timeout): 和子进程交互,发送和读取数据。
send_signal(singnal): 发送信号到子进程 。
terminate(): 停止子进程,也就是发送SIGTERM信号到子进程。
kill(): 杀死子进程。发送 SIGKILL 信号到子进程。
3. run 与 Popen 的同步/异步对比实验
Run() 和 Popen() 同步/异步的简单对比如下:
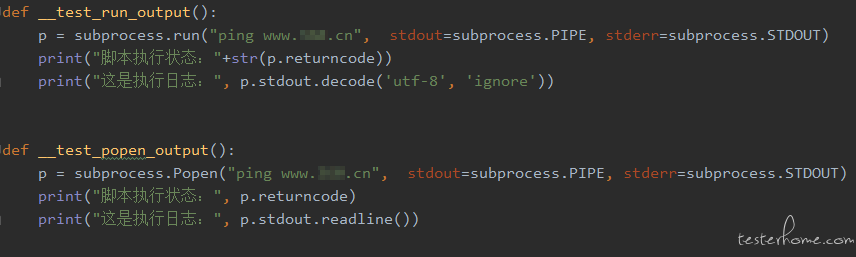

从执行结果可以看出,Popen 在子进程执行过程中就可以获取到日志,run 需要等待进程执行完成才能获取到日志。如果需要执行的命令耗时很短,可以选择 run 方法。因为我们的数据构造流程通常比较长,需要实时获取日志,所以选择了 Popen。
三、遇到的问题与解决方案
在使用 Popen 的过程中也遇到了一些问题,下面将具体介绍一下遇到的问题以及解决方案。
如何保证获取到完整的进程执行日志
subprocess.Popen() 可以获取到执行过程中的日志了,那我们如何保证进程日志获取的完整性呢?我们来看下具体方案:
方案一:这是我们最开始采用的方案。通过获取方法 poll() 返回的状态码来检查进程是否终止。如果终止,返回 returncode,否则返回 None,代码如下:

该方案在使用的过程中存在问题。当子程序已经执行完毕,日志还没有获取完整,会出现日志接收不全的情况。为了解决这种问题,保证日志的完整性,我们选择通过判断日志是否读取完毕作为判断依据,详细参见方案二。
方案二:通过判断日志是否读取完毕保证日志完整性。代码如下:

这种方法看似解决了日志不全的问题,但是存在着一定的风险。日志为 None 无法有效保证子进程执行结束(虽然经过多方实践,暂时没有发现日志为 None 但脚本未执行结束的情况)。为了安全起见,我们还是需要兼顾一下进程的执行状态,具体参见方案三。
方案三:通过判断 poll() 返回状态和日志返回值,也就是说,程序状态结束且返回对象为空,才表示子进程已经执行结束,并且获取到了完整的日志,代码如下:
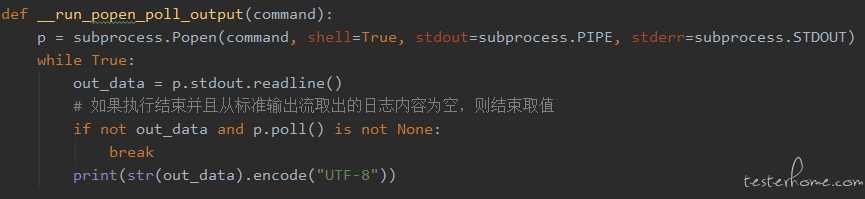
该方案已经比较完善了,通过子进程执行结束并且执行日志为 None,保证执行日志的完整性。美中不足的是,日志信息可能会比实际的多一些,当输出先读取完毕,子进程还没有结束,我们会获取到一部分空行,为了日志的美观度,我们可以进一步优化,获取日志的时候,过滤掉空行,代码如下:

通过判断输出流和进程的执行状态,完美的解决了上面的问题,保证了日志的完整性与正确性。
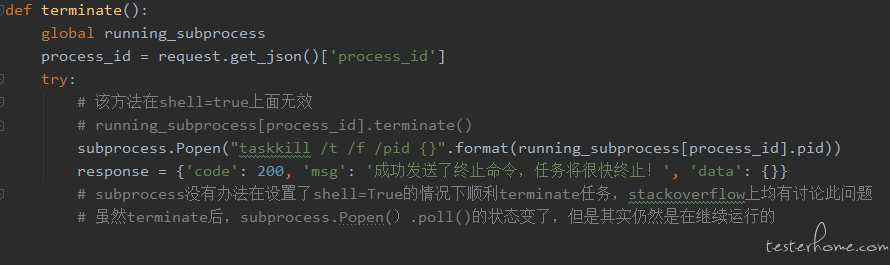
如何保证脚本进程正常终止 当脚本执行以后,我们可能会因为某些原因想终止脚本的运行,如参数错误等。 在我们项目代码中,使用 Popen.terminate() 去终止进程的时候,发现命令只终止了父进程,唤起的子进程仍然在执行。
为了找到原因,先看一下项目中创建 Popen 的代码:

参数介绍的时候提到过,shell 为 True 或 False 时,command 的类型是有要求的。因为我们 command 传值是 String 类型,参数 shell 只能设置为 True。当 shell=True 的时,程序会创建一个 shell 进程,command 是 shell 进程的子进程。
我们再来看下 Popen.terminate() 做了什么?官方的说明如下:
Stop the child. On POSIX OSs the method sends SIGTERM to the child. On Windows the Win32 API function TerminateProcess()is called to stop the child
也就是说,在 POSIX 系统中,该方法会发送 SIGTERM 信号给子进程;
在 Windows 系统中,该方法会调用 Win32 提供的 API TerminateProcess() 方法。
原因很清晰了,当 shell=True 的时候,发送 SIGTERM 能够杀死 shell 进程,但是无法杀死它的子进程(command);windows 系统中同理,TerminateProcess() 杀死了 shell 进程,却没有杀死它的子进程(command)。
解决方案如下:
方案一:比较优雅的方式,创建 Popen 对象时,将参数 shell 设为 False。实践发现,当 shell=False 的时候,Popen.terminate() 方法的执行结果是符合预期的;
subprocess.Popen(command, shell=False)
前面提到过,因为 command 格式问题,在我们项目中,shell 只能设置为 True,所以我们又探索了新的解决方案。
方案二:手动终止进程。使用第三方工具包 psutil,获取全部的子进程并逐一杀掉,该方法在 Linux 和 windows 平台通用。代码见下图。
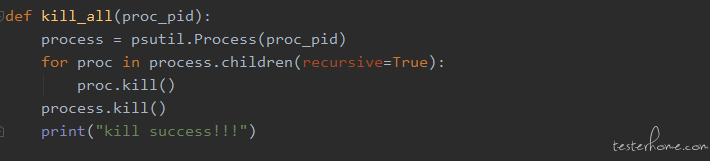
在 windows 服务器下,还可以用以下命令:
taskkill /t /f /pid {pid},强制杀掉指定进程以及它的子进程。
windows 平台的方案无需第三方依赖,所以我们项目中选择了该方案,项目代码如下:
以上就是 Python 中的 subprocess 模块在我们项目实践中遇到的问题以及解决方案,希望可以给大家提供一些使用思路以及规避掉一系列问题,更多关于Python测试开发subprocess的资料请关注我们其它相关文章!
相关推荐
-

Python实现subprocess执行外部命令
一.Python执行外部命令 1.subprocess模块简介 subprocess 模块允许我们启动一个新进程,并连接到它们的输入/输出/错误管道,从而获取返回值. 这个模块用来创建和管理子进程.它提供了高层次的接口,用来替换os.system*(). os.spawn*(). os.popen*().os,popen2.*()和commands.*等模块和函数. subprocess提供了一个名为Popen的类启动和设置子进程的参数,由于这个类比较复杂, subprocess还提供了若干便利
-
Python实现系统交互(subprocess)
目录 一.os与commands模块 1. os.system()函数实例 2. os.popen()函数实例 3. commands.getstatusoutput()函数实例 二.subprocess模块 1. subprocess模块中的常用函数 2. 上面各函数的定义及参数说明 3. subprocess.CompletedProcess类介绍 4. 实例 三.subprocess.Popen介绍 1.subprocess.Popen的构造函数 2. subprocess.Popen类的
-
python中subprocess实例用法及知识点详解
1.subprocess这个模块来产生子进程,并且可以连接到子进程的标准输入.输出.错误中,还可以获得子进程的返回值. 2.subprocess提供了2种方法调用子程序. 实例 # coding:utf-8 import os # popen返回文件对象,同open操作一样 f = os.popen(r"ls", "r") l = f.read() print(l) f.close() Python subprocess知识点扩充 使用subprocess模块的目的
-
Python执行外部命令subprocess的使用详解
一.了解subprocess subeprocess模块是python自带的模块,无需安装,主要用来取代一些就的模块或方法,如os.system.os.spawn*.os.popen.commands.*等. 因此执行外部命令优先使用subprocess模块 1.subprocess.run()方法 subprocess.run()方法是官方推荐的方法,几乎所有的工作都可以用它来完成. 如下是函数源码: subprocess.run(args, *, stdin=None, input=None
-
解决python subprocess参数shell=True踩到的坑
0x01 问题现象 写的程序使用subprocess创建子进程运行其他程序,判断其他程序运行完后进行处理. 在subprocess使用了shell=True,判断用户程序退出的代码如下 while self.proc.poll() is None: do_something 判断子进程是否运行结束,程序在子进程运行结束后,代码未向下继续运行,而是卡在了这个循环中. 0x02 原因分析 百度后对shell参数的解释如下: shell=True参数会让subprocess.Popen接受字符串类型的
-
Python移动测试开发subprocess模块项目实战
目录 一.背景 二.subprocess 模块基础 1. subprocess.run 方法 2. subprocess.Popen 方法 3. run 与 Popen 的同步/异步对比实验 三.遇到的问题与解决方案 如何保证获取到完整的进程执行日志 解决方案如下: 一.背景 我们日常测试中存在大量重复的造数操作,且流程较长,为了提升测试效率,我们搭建了数据构造平台.平台采用了前端 + 脚本分离的形式,数据构造脚本独立存在,页面和脚本的关联关系通过页面配置进行绑定. 页面配置中,包含了脚本的路径
-
React 模块联邦多模块项目实战详解
目录 前提: 1. 修改webpack增加ModuleFederationPlugin 2.本地开发测试 3.根据路由变化自动加载对应的服务入口 4.线上部署 5.问题记录 前提: 老项目是一个多模块的前端项目,有一个框架层级的前端服务A,用来渲染界面的大概样子,其余各个功能模块前端定义自己的路由信息与组件.本地开发时,通过依赖框架服务A来启动项目,在线上部署时会有一个总前端的应用,在整合的时候,通过在获取路由信息时批量加载各个功能模块的路由信息,来达到服务整合的效果. // config.js
-
SpringBoot创建maven多模块项目实战代码
工作中一直都是一个人奋战一人一个项目,使用maven管理,看这个也挺好,但是总感觉没有充分发挥maven的功能,于是研究了一下这个,网上关于这个的文章很多,虽然不是很好,但我从中收获了很多,在这集百家所长,写一份实战记录,大家跟着我一块做吧! 声明:构建多模块不是最难的,难点是如果把多模块打包成一个执行jar. SpringBoot官方推崇的是富jar,也就是jar文件启动项目,所以如果在这里打war包我不具体介绍,如果需要的朋友可以给我留言,我回复. 建议clone项目后,在看教程(有不足的地
-
Python进阶多线程爬取网页项目实战
目录 一.网页分析 二.代码实现 一.网页分析 这次我们选择爬取的网站是水木社区的Python页面 网页:https://www.mysmth.net/nForum/#!board/Python?p=1 根据惯例,我们第一步还是分析一下页面结构和翻页时的请求. 通过前三页的链接分析后得知,每一页链接中最后的参数是页数,我们修改它即可得到其他页面的数据. 再来分析一下,我们需要获取帖子的链接就在id 为 body 的 section下,然后一层一层找到里面的 table,我们就能遍历这些链接的标题
-
Python爬虫开发与项目实战
内容简介 随着大数据时代到来,网络信息量也变得更多更大,基于传统搜索引擎的局限性,网络爬虫应运而生,本书从基本的爬虫原理开始讲解,通过介绍Pthyon编程语言和Web前端基础知识引领读者入门,之后介绍动态爬虫原理以及Scrapy爬虫框架,最后介绍大规模数据下分布式爬虫的设计以及PySpider爬虫框架等. 主要特点: l 由浅入深,从Python和Web前端基础开始讲起,逐步加深难度,层层递进. l 内容详实,从静态网站到动态网站,从单机爬虫到分布式爬虫,既包含基础知识点,又讲解了关键问题和难点
-
使用Python+Flask开发博客项目并实现内网穿透
目录 前言 1.个人的注册与登录模块 2.首页文章展示模块 3.文章详情展示模块 4.文章发布模块 5.文章添加分类模块 6.文章分类管理模块 7.文章管理模块 8.用户个人信息注销模块 9.信息管理模块 10.程序启动模块 11.内网穿透模块 12.总结 前言 Flask是一个使用python编写的轻量级Web框架,对比其他相同类型的框架而言,这个框架更加的灵活轻便.并且具有很强的定制性,用户可以根据自己的需求添加功能,有强大的插件库,这也是为什么这个框架在python领域一直火热的原因.这篇
-
python+django+mysql开发实战(附demo)
开发工具:pycharm 环境:python3.7.4(例子中用的3.6)下载安装pycharm:http://www.jetbrains.com/pycharm/download/#section=windows分为社区版和专业版,一个免费一个收费Pycharm2021破解版下载: https://www.jb51.net/softs/598504.html下载安装python:https://www.python.org/downloads/windows/安装好开发工具和python环境后
-
Python用selenium实现自动登录和下单的项目实战
目录 前言 前期准备 代码实现思路 配置浏览器驱动 确定浏览器版本 下载驱动 测试是否成功 代码实现 最后 前言 学python对selenium应该不陌生吧 Selenium 是最广泛使用的开源 Web UI(用户界面)自动化测试套件之一.Selenium 支持的语言包括C#,Java,Perl,PHP,Python 和 Ruby.目前,Selenium Web 驱动程序最受 Python 和 C#欢迎.Selenium 测试脚本可以使用任何支持的编程语言进行编码,并且可以直接在大多数现代 W
-
Python中subprocess模块用法实例详解
本文实例讲述了Python中subprocess模块用法.分享给大家供大家参考.具体如下: 执行命令: >>> subprocess.call(["ls", "-l"]) 0 >>> subprocess.call("exit 1", shell=True) 1 测试调用系统中cmd命令,显示命令执行的结果: x=subprocess.check_output(["echo", "
-
python实现H2O中的随机森林算法介绍及其项目实战
H2O中的随机森林算法介绍及其项目实战(python实现) 包的引入:from h2o.estimators.random_forest import H2ORandomForestEstimator H2ORandomForestEstimator 的常用方法和参数介绍: (一)建模方法: model =H2ORandomForestEstimator(ntrees=n,max_depth =m) model.train(x=random_pv.names,y='Catrgory',train